






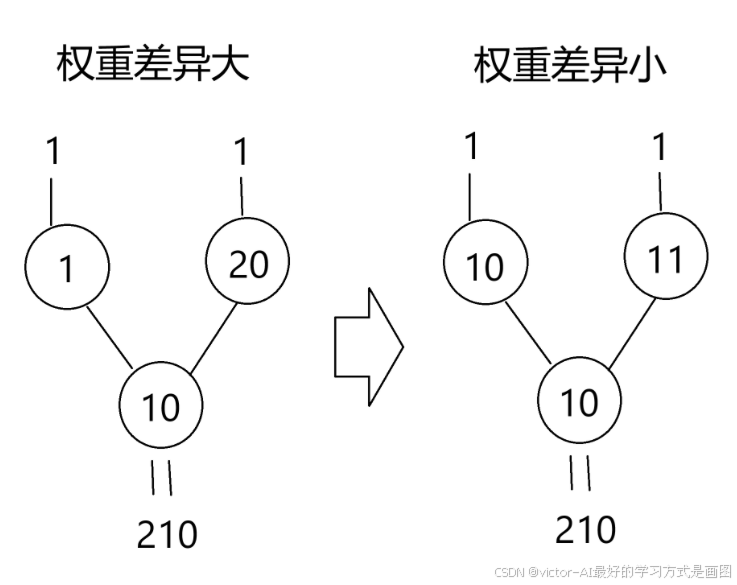
左边是没有正则化的,右边是有正则化L2的,结果是一样的
没有正则化:1×1×10 + 1×20×10 = 210。
正则化L2: 1×10×10 + 1×11×10 = 210。
我看别人的文章,说权重差异大就复杂,权重差不多就不复杂,我也不是很理解,大概是认为希望模型权重不要太过依赖某条路径吧。
大白话:
在反向传播时,加入额外的损失值,让总损失值变得比原来更大,并且加入的损失值要关联到神经网络全部权重的大小,当出现权重的平方变大的时候,也就是网络权重往更加负或者更加正的方向走的时候,损失就越大,从而控制极大正或者极大负的情况出现。
原因:
在神经网络训练的时候,当网络结构和数量足够牛皮,网络有能力单独拟合那些躁点数据,模型为了拟合这些躁点数据,权重可能会变得很大,或者变得很小,因为我们没有制定任何的限制,可能会出现99,-100这种较大权重出现,因为可能拟合了奇怪的数据。一般情况下我看到权重大概都在-5到5之间。
机制:
在原有的损失函数的前提下,加多一个值(也可以理解为加多一个计算公式),使得损失值扩大。

我们知道一个定理:损失值越大,惩罚越大。
- 大的权重会导致更大的平方和,因此在正则化项中贡献更多的惩罚。小的权重虽然也会被惩罚,但相对贡献较小。
- 权重衰减的目的是鼓励模型学习到的权重保持较小的值,降低模型的复杂度,从而提升模型的泛化能力。
举个例子
weights = [[0.5, -0.2, 0.1],
[0.3, 0.8, -0.5],
[-0.7, 0.4, 0.6]]
这个权重矩阵有 3 行 3 列,共有 9 个权重值。我们将计算这些权重的平方和以及基于这个平方和的权重衰减。
首先,我们计算权重矩阵中所有权重的平方和:

逐项计算:

将它们加在一起:

设定权重衰减系数
假设我们设定权重衰减系数 λ=0.01。
Regularization Term=λ×Weight Sum of Squares
代入数值:
Regularization Term=0.01×2.09=0.0209
最终损失计算
假设我们有一个损失
L(θ)(例如,交叉熵损失)为 0.5。结合正则化项,最终的损失函数为:

总结
在这个例子中:
我们计算了权重的平方和为 2.09。
设置的权重衰减系数为 0.01。
计算得出的正则化项为 0.0209。
最终损失(包括正则化)为 0.5209。
结论
尽管小权重也会受到惩罚,但相对来说,较大的权重会对总损失产生更大的影响,导致优化算法优先处理它们。
权重衰减的目的是通过综合考虑所有权重的影响,促进更简单、泛化能力更强的模型。
在实际应用中,调整正则化强度(如 λ 值)可以帮助找到在避免过拟合和确保模型表现之间的平衡。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









