







一、获取页面
我们要爬取数据,就需要先去找到数据来源,即找到数据所在的页面,本节内容总结了利用Requests获取页面的方法。这种方法基本适合于所有静态页面(数据全部存储在静态html标签中,直接解析网页即可)和部分动态页面(只存有部分数据,更多其他数据需要在此页面下进一步动态加载。例如:AJAX局部动态更新)。
我们暂时先研究静态页面,即默认只要获取了页面,就可以得到我们所需的所有数据内容。
二、基本流程
首先我们需要用到爬虫所必备的第三方库Requests。顾名思义,Requests库的作用就是发送http请求指令,从而获取我们想要爬取的目标页面。我们通过在终端中输入一下命令来安装Requests
pip install requests
requests库中所提供了发送http请求最重要的两个请求方式,get请求和post请求,我们可以根据需要自身需要来使用,一般来说,大多数网页的获取都采用的是get请求
//get请求和post请求,其中get分为有参数和无参数
key-value-dict = {'key1':'value1','key2':'value2'}
res1 = requests.get("url")
res2 = requests.get("url",""params=key-value-dict) //参数加载在URL中
res3 = requests.post("url",data=key-value-dict)
返回的res对象即包含了我们所请求的目标网页内容,同时还包含了其他response请求信息,我们可以通过以下方法查看
r.text //查看网页HTML
r.encoding //查看网页编码格式
r.status_code //查看响应的状态码
此外requests还有一些其他的参数,从而对请求做更高级的规定处理
三、设置请求头(Headers)
设置请求Headers:http协议中要求每一个请求都需要加一个Headers内容,其中封装了请求访问方式的参数,用于区分不同的请求内容。我们用浏览器上网也是如此,只不过Headers中的内容是浏览器自动帮助我们填充的。很多网站通过查询Headers中的user-agent来来判断一个请求是来着一个爬虫的还是来自一个浏览器的,所以,为了更好的隐藏我们爬虫的身份,我们需要手动填充一些内容,以使服务器认为这是一条正常的浏览器访问请求。
首先我们需要获取正确的Headers,以Chrome浏览器为例,我们在打开一个网站之前,先右键->检查,然后在工具列表中选择Network,然后打开我们想要访问的网页,可以在Network中看见加载此页面中的所有数据流
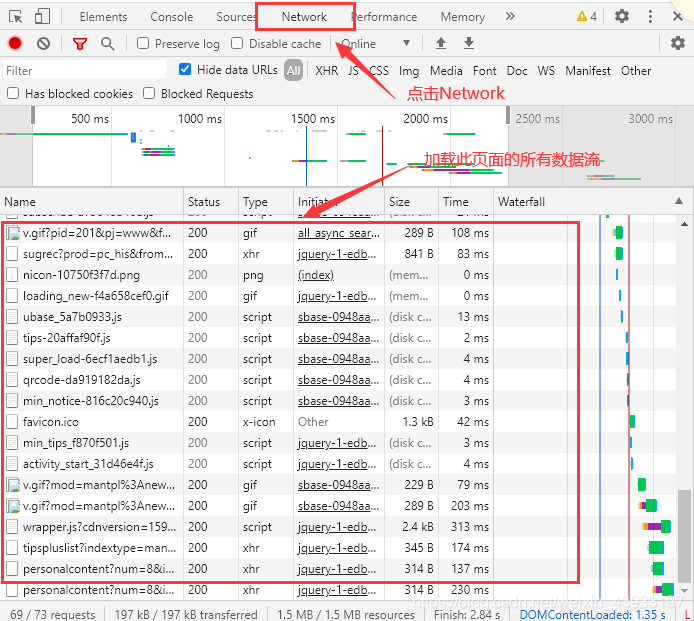
然后我们找到当前页面的数据流,点击之后在右侧就可以找到此次的requests请求的headers了
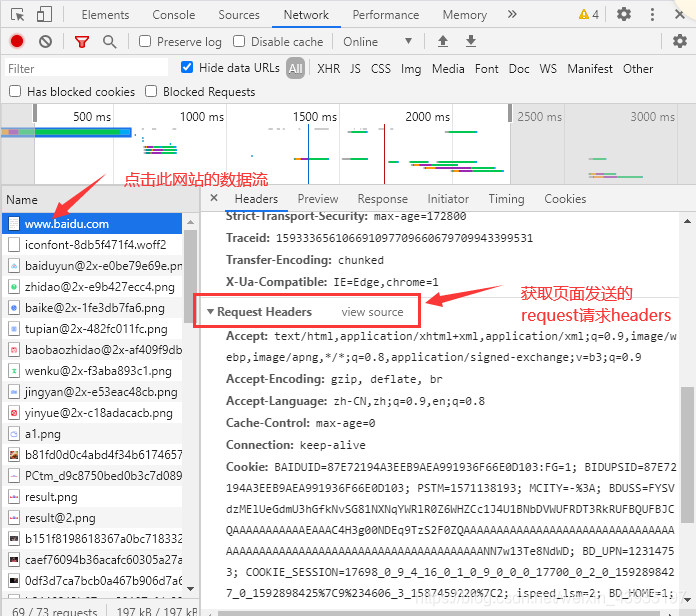
可以看到headers中定义了很多的参数,这些参数都是通过key-value对的形式进行声明。所有的参数中,最重要的两个是user-agent和host
//自定义一个headers
headers =
{
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/83.0.4103.116 Safari/537.36',
'Host': 'www.baidu.com'
}
//带自定义Headers的请求
res = requests.get("url", headers = headers)
其中user-agent用于标明此次请求是从哪里发起,如果我们不加的话,python会自动帮我们填上“python-requests/版本号”。一些严格的网页为了防止爬虫大量进入会禁止来自不明地方的请求,有时候为了能够顺利获取页面信息,我们需要窃取浏览器的外衣,把自己包裹在浏览器的皮囊下进入。
host是用来标注此次请求申请的是哪个网站,一般和我们get中写的url主域名保持一致,不然可能会出现异常。
四、超时响应
有时候爬虫遇到服务器长时间无返回的情况下,可能会出现死等的现象,从而影响了后序进程的运行。为了避免这样的事情发生,我们需要设置timeout参数来规定在发送request后等待的时长,如果到时间后没有收到response,就返回一个异常。
//设置此次访问的超时时长
res = requests.get("url",timeout=20)
以上就是爬虫的第一步-------获取页面。此时我们已经可以将远在服务器中的数据源下载到我们本地了,接下来就是如何从这个数据源中提取出我们要的数据内容。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









