




分区表

1. 什么场景的数据需要分区
- 表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他均为历史数据。
- 分区表的数据更加容易维护。例如,想批量删除大量数据可以使用清除整个分区的方式。还可以对一个独立分区进行优化、检查、修复等操作。
- 分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。
- 可以使用分区表来避免某些特殊的瓶颈,例如
InnoDB的单个索引互斥访问。 - 如果需要,还可以备份和恢复独立的分区,这在非常大的数据集的场景下效果极好。
2. 分区的限制
- 一个表最多只能有1024个分区。
- 如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来。
- 分区表无法使用外键约束。
3. 分区表的原理
分区表由多个相关的底层表实现,这些底层表也是由句柄对象(Handler object)表示,所以我们可以直接访问各个分区。从存储引擎的角度来看,底层表和一个普通的表没有如何不同,存储引擎也无须知道这是要给普通表还是一个分区表的一部分。
- SELECT 查询
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断是否可以过滤部分分区,然后再调用对应的存储引擎接口访问各个分区的数据。 - INSERT 操作
当写入一条记录时,分区层先打开并锁住所有的底层表,然后确定哪个分区接收这条记录,再将记录写入对应底层表。 - DELETE 操作
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定数据对应的分区,最后对相应的底层表进行删除操作。 - UPDATE 操作
当更新一条记录时,分区层先打开并锁住所有的底层表,MySQL先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据应该放在哪个分区,最后对底层表进行写入操作,并对原数据所在的底层表进行删除操作。
虽然每个操作都会“先打开并锁住所有的底层表”,但这并不是说分区表在处理过程中是锁住全表的。如果存储引擎能够自己实现行级锁,例如InnoDB,则会在分区层释放对应表锁。这个加锁和解锁过程与普通InnoDB上的查询类似。
4.1 分区表的应用
CREATE TABLE T (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY(`ftime`)
)ENGINE = INNODB DEFAULT CHARSET = latin1
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = INNODB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = INNODB,
PARTITION P_2019 VALUES LESS THAN (2019) ENGINE = INNODB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = INNODB);
INSERT INTO T VALUES ('2017-4-1',1),('2018-4-1',1);
图1

图1表t的磁盘文件
我在表中初始化插入了两条记录,按照定义的分区规则,这两行记录分别落在 p_2018 和 p_2019 这两个分区上。
可以看到,这个表包含了一个.frm文件和 4 个.ibd文件,每个分区对应一个.ibd文件。也就是说:
- 对于引擎层来说,这是 4 个表。
- 对于
Server层来说,这是 1 个表。
4.2 分区表的引擎层行为
首先举个分区表加间隙锁的例子,目的是说明对于InnoDB来说,这是 4 个表。
图2
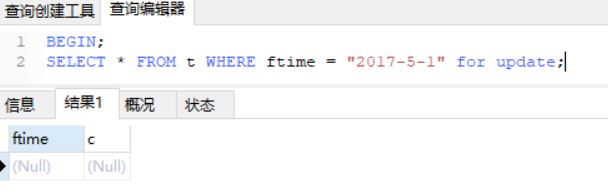
图3
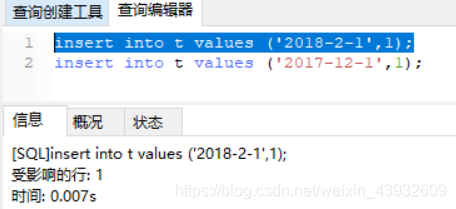
图4
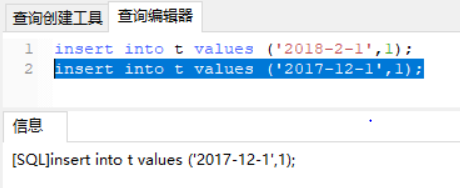
图5
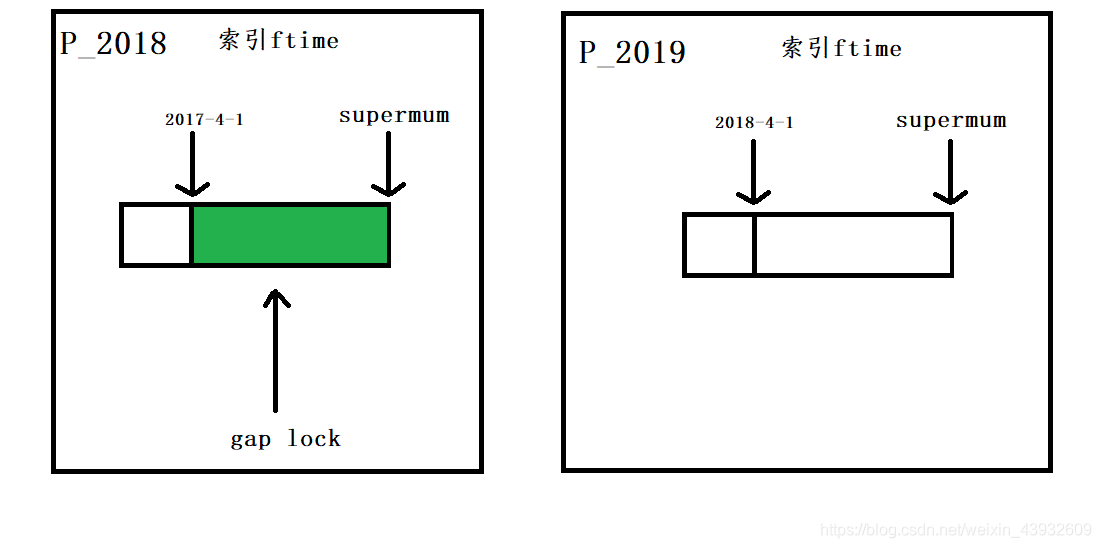
我们初始化表 t 的时候,只插入了两行数据,ftime的值分别是,2017-4-1和2018-4-1。图1的 SELECT语句对索引ftime上这两个记录的间隙加了锁。如果是一个普通的表,那么此时,在表 t 的ftime索引上,间隙锁和加锁状态应该是下面示意图相同。
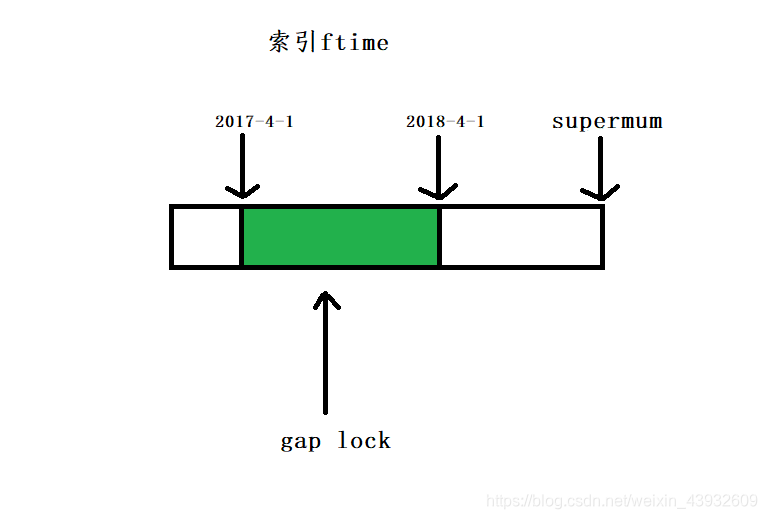
也就是说,“2017-4-1” 和 “2018-4-4”这两个记录之间的间隙是会被锁住的。那么,图3和图4的两条插入语句应该都要进入锁等待状态。
但是,从上面的实验效果可以看出,图3的insert语句是可以执行成功的。这是因为,对于引擎来说,P_2018和P_2019是两个不同的表,也就是说2017-4-1的下一个记录并不是2018-4-1,而是P_2018的分区的supermum。所以图2时刻,在表 t 的ftime索引上,间隙和枷锁的状态其实是这样的:
图6


















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











