







神经网络和多层感知机MLP
文章内容和代码可由此处查看或下载:
https://github.com/WangXinyuanCSU/DeepLearning-Concepts-and-Implementation
参考:
https://www.cnblogs.com/pinard/p/6422831.html
https://zhuanlan.zhihu.com/p/73214810
https://blog.youkuaiyun.com/tyhj_sf/article/details/79932893
1. 感知机到神经网络,神经网络的基本结构
1.1 感知机
感知机模型是将若干输入加权求和并通过激活函数后输出的模型:

感知机可以表示为线性变换+非线性激活函数:
z=∑i=1mwixi+bz=∑_{i=1}^{m}w_ix_i+bz=∑i=1mwixi+b
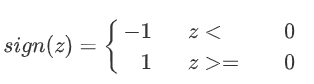
上述模型是一个二分类器,由于其过于简单,无法拟合复杂的非线性任务。
1.2 神经网络及其基本结构
神经网络则是基于这样的简单模型,将多个神经元逐层堆叠,由此形成我们的深度模型:
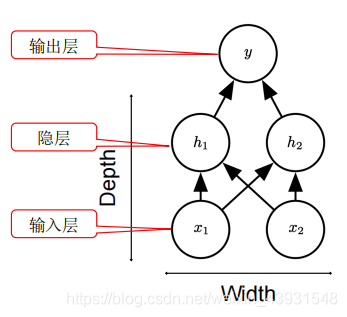
上图是一个最简单的神经网络,它包含神经网络的最基本结构:
输入层:对应输入向量的大小
输出层:对应模型任务,可以是二分类,多分类,也可以是回归任务等等
隐层:由多个感知机,即神经元组成,每个神经元对上层的所有输入做线性变换与非线性激活。
1.3 神经网络参数的定义
神经网络的隐层可以不止一层,宽度也可以很宽,一般来说,我们计算网络层数时不考虑输入层,所以下图是一个4层的神经网络,由于每层神经元连接到上层的所有输入,这个网络也叫做全连接网络,或多层感知机:

由于网络中每层都有参数www和bbb,所以我们需要特定的方式进行定义:以下图一个三层的DNN为例,第二层的第4个神经元到第三层的第2个神经元的线性系数定义为w243w^3_{24}w243。上标3代表线性系数www所在的层数,而下标对应的是输出的第三层索引2和输入的第二层索引4。这样定义,每层进行的矩阵运算都可以表示为wTx+bw^Tx+bwTx+b。

类似的偏置bbb,第二层的第三个神经元对应的偏倚定义为b32b^2_3b32。

2. 前向传播
2.1 前向传播原理
上面讲到网络每层从输入到输出都可以表示为线性变换z=wTx+bz=w^Tx+bz=wTx+b与激活函数σ(z)\sigma(z)σ(z),前向传播顾名思义就是从输入层开始,逐层计算输出,最终得到输出层的输出后结束。

例如第二层的输出a12,a22,a32a^2_1,a^2_2,a^2_3a12,a22,a32,我们有:
a12=σ(z12)=σ(w112x1+w122x2+w132x3+b12)a^2_1=σ(z^2_1)=σ(w^2_{11}x^1+w^2_{12}x^2+w^2_{13}x^3+b^2_1)a12=σ(z12)=σ(w112x1+w122x2+w132x3+b12)
a22=σ(z22)=σ(w212x1+w222x2+w232x3+b22)a^2_2=σ(z^2_2)=σ(w^2_{21}x^1+w^2_{22}x^2+w^2_{23}x^3+b^2_2)a22=σ(z22)=σ(w212x1+w222x2+w232x3+b22)
a32=σ(z32)=σ(w312x1+w322x2+w332x3+b32)a^2_3=σ(z^2_3)=σ(w^2_{31}x^1+w^2_{32}x^2+w^2_{33}x^3+b^2_3)a32=σ(z32)=σ(w312x1+w322x2+w332x3+b32)
对于第三层的的输出a13a^3_1a13,我们有:
a13=σ(z13)=σ(w113x1+w123x2+w133x3+b13)a^3_1=σ(z^3_1)=σ(w^3_{11}x^1+w^3_{12}x^2+w^3_{13}x^3+b^3_1)a13=σ(z13<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3463
3463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









