









一、背景
由于需要用到用java生成hdfs文件并上传到指定目录中,在Hive中即可查询到数据,基于此背景,开发此工具类
ORC官方网站:https://orc.apache.org/
二、支持数据类型
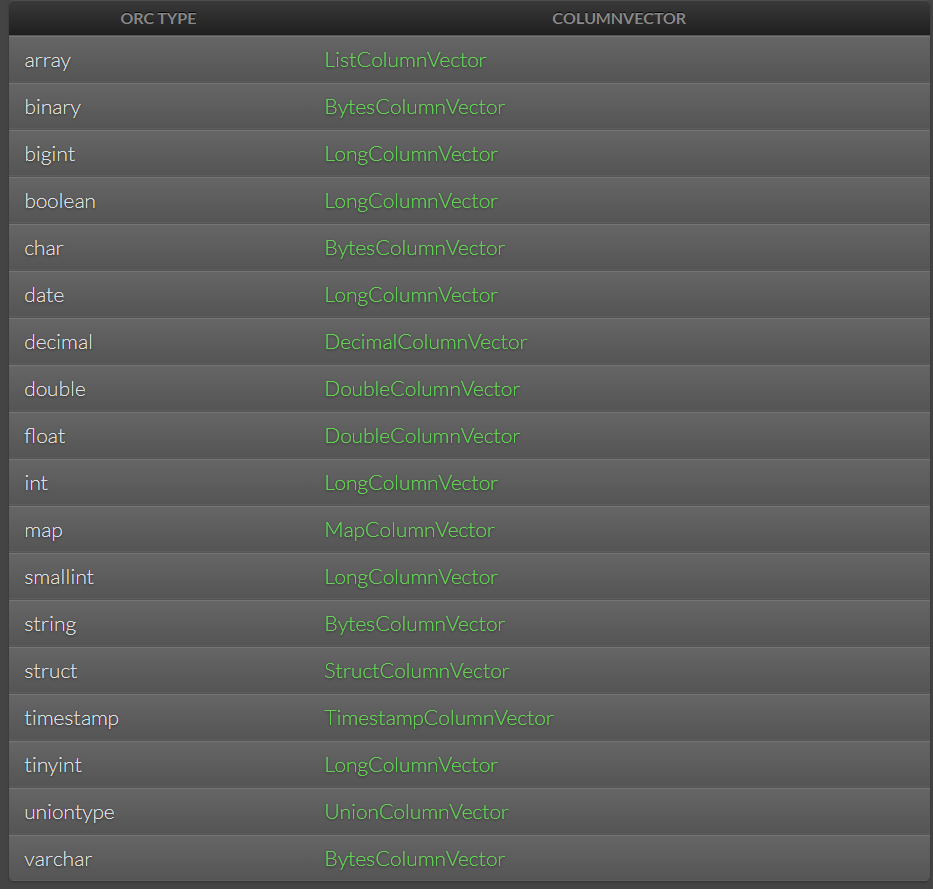
三、工具开发
package com.xx.util;
import com.alibaba.fastjson2.JSON;
import com.alibaba.fastjson2.JSONArray;
import com.alibaba.fastjson2.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.ql.exec.vector.BytesColumnVector;
import org.apache.hadoop.hive.ql.exec.vector.VectorizedRowBatch;
import org.apache.orc.OrcFile;
import org.apache.orc.TypeDescription;
import org.apache.orc.Writer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Slf4j
public class ORCUtil {
/**
* 将JSON数据转换成ORC文件并上传到HDFS中
*
* @param source json串,必须是和数据表顺序一致的json串
* @param dbFields 存在数据库中的Hive表元数据字段
* @param target 目标文件路径,包含文件名和.orc后缀
* @throws IOException
*/
public static void write(String source, List<String> dbFields, String target) throws IOException {
long start = System.currentTimeMillis();
Configuration conf = new Configuration();
TypeDescription schema = TypeDescription.createStruct();
JSONArray datas = JSONArray.parseArray(source);
ArrayList<String> keys = new ArrayList<>(datas.getJSONObject(0).keySet());
for (String flied : dbFields) {
schema.addField(flied, TypeDescription.createString());
}
Writer writer = OrcFile.createWriter(new Path(target),
OrcFile.writerOptions(conf)
.setSchema(schema).stripeSize(67108864)
.bufferSize(64 * 1024)
.blockSize(128 * 1024 * 1024)
.rowIndexStride(10000)
.blockPadding(true));
VectorizedRowBatch batch = schema.createRowBatch();
ArrayList<BytesColumnVector> bytesColumnVectors = new ArrayList<>();
for (int i = 0; i < batch.numCols; i++) {
bytesColumnVectors.add((BytesColumnVector) batch.cols[i]);
}
for (Object data : datas) {
JSONObject dataObj = (JSONObject) data;
int row = batch.size++;
for (int i = 0; i < dbFields.size(); i++) {
// 数据对象上的字段
if(keys.contains(dbFields.get(i))){
bytesColumnVectors.get(i).setVal(row, dataObj.getString(dbFields.get(i)).getBytes());
}else{
bytesColumnVectors.get(i).setVal(row, "".getBytes());
}
}
}
long stop = System.currentTimeMillis();
log.info("将json转换为orc文件花费的时间是 " + (stop - start) / 1000 + "秒");
if (batch.size != 0) {
writer.addRowBatch(batch);
batch.reset();
}
writer.close();
}
}
四、总结
基于此可以根据实际业务场景可以生成数据并上传到HDFS上提供Hive查询




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











