







 该博客介绍了如何利用Selenium进行网页登录,并结合BeautifulSoup抓取携程酒店页面的用户评论。在登录过程中,代码会检查是否需要输入验证码,如果需要则提示用户手动输入。然后,提取评论的房间类型、入住时间等信息,并保存评论内容和图片链接到CSV文件。整个过程涉及网页自动化、HTML解析和数据存储。
该博客介绍了如何利用Selenium进行网页登录,并结合BeautifulSoup抓取携程酒店页面的用户评论。在登录过程中,代码会检查是否需要输入验证码,如果需要则提示用户手动输入。然后,提取评论的房间类型、入住时间等信息,并保存评论内容和图片链接到CSV文件。整个过程涉及网页自动化、HTML解析和数据存储。
登录
browser.get('https://passport.ctrip.com/user/login')
browser.maximize_window()
browser.find_element_by_id("nloginname").send_keys(ACCOUNT)
browser.find_element_by_id("npwd").send_keys(PASSWORD)
browser.find_element_by_id("nsubmit").click()
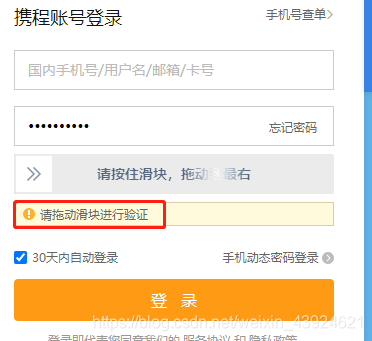
登录的时候要检测需不需要验证码,需要的话要手动输入。
try:
wrong = timeout.until(EC.presence_of_element_located((By.NAME, 'nav-bar-d-info')))
if (wrong.text == None):
print("wrong.text None")
else:
pass
except:
code = timeout.until(EC.presence_of_element_located((By.ID, 'nerr')))
if(code.text != None):
print(code.text)
input("请手动输入验证码后按回车继续")
browser.find_element_by_id("nsubmit").click()
爬取评论
只做了爬取评论 没做提取酒店信息,酒店信息应该更简单。
评论用BeautifulSoup,提取p标签和span标签。
保存用pandas保存为csv
一个评论的div:
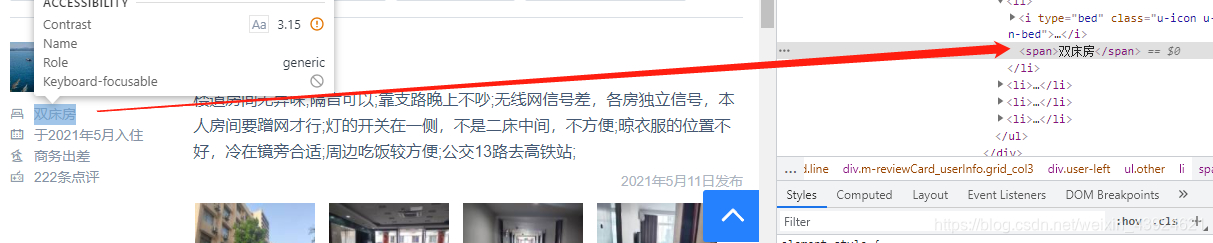
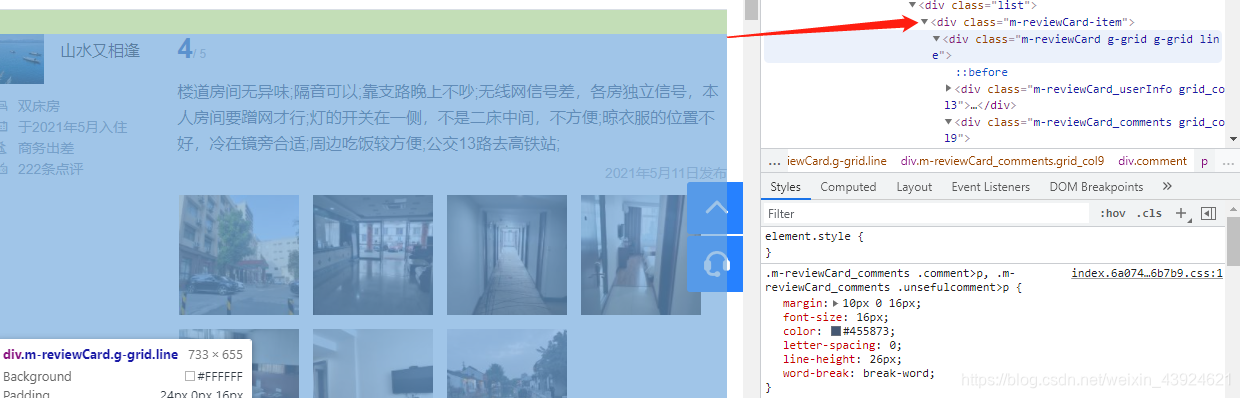 评论详情:
评论详情:
评论内容:
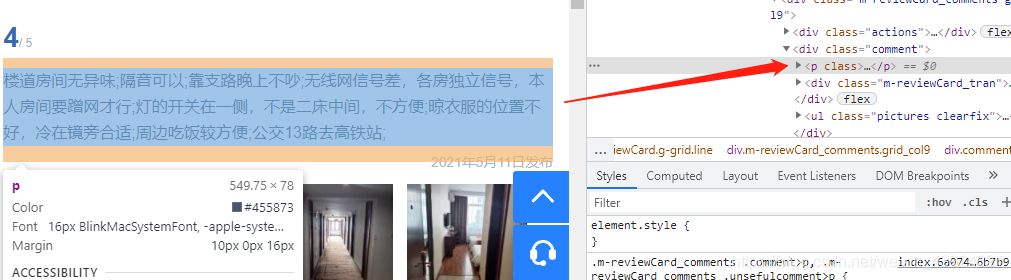
评论图片直接找img标签,找到的第一个是头像,判断找到的img的数量再保存即可。
所有代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : exp3.py
@Contact : nickdlk@outlook.com
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/6/12 22:30 Nick 1.0 None
'''
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
ACCOUNT = ""
PASSWORD = ""
if(ACCOUNT=="" or PASSWORD==""):
exit("请输入账号密码")
options = webdriver.ChromeOptions()
prefs = {
'profile.default_content_setting_values':
{
'notifications': 2
}
}
options.add_experimental_option('prefs', prefs) # 关掉浏览器左上角的通知提示
options.add_argument("disable-infobars") # 关闭'chrome正受到自动测试软件的控制'提示
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(10)#隐性等待 只需设置一次
timeout = WebDriverWait(browser, 10)
#############
browser.get('https://passport.ctrip.com/user/login')
browser.maximize_window()
browser.find_element_by_id("nloginname").send_keys(ACCOUNT)
browser.find_element_by_id("npwd").send_keys(PASSWORD)
browser.find_element_by_id("nsubmit").click()
try:
wrong = timeout.until(EC.presence_of_element_located((By.NAME, 'nav-bar-d-info')))
if (wrong.text == None):
print("wrong.text None")
else:
pass
except:
code = timeout.until(EC.presence_of_element_located((By.ID, 'nerr')))
if(code.text != None):
print(code.text)
input("请手动输入验证码后按回车继续")
browser.find_element_by_id("nsubmit").click()
browser.implicitly_wait(5)
browser.get('https://hotels.ctrip.com/hotels/detail/?hotelId=5276576')#跳转到酒店页面
def get_comment(browser):
soup = BeautifulSoup(browser.page_source, "lxml")
review = soup.find_all("div", attrs={'class': 'm-reviewCard-item'})
reviewlist = []
for r in review:
span = r.find_all("span")
rvw = r.find_all("p")
img = r.find_all("img")
_r = {
"房间类型": span[0].text,
"入住时间": span[1].text,
"出游类型": span[2].text,
"总评论数": span[3].text,
"用户名称": rvw[0].text,
"评论内容": rvw[1].text,
"图片": ""
}
if (len(img) > 1):
for i in img[1:]:
_r["图片"] = _r["图片"] + ";" + str(i.attrs["src"]) # 取图片地址
reviewlist.append(_r)
return reviewlist
browser.get('https://hotels.ctrip.com/hotels/detail/?hotelId=5276576')
browser.implicitly_wait(10)
time.sleep(0.1)
# 设置爬取的评论页数
pagenum = 360
reviewlistAll = []
for n in range(pagenum):
_reviewlist = get_comment(browser)#爬取评论数据
reviewlistAll = reviewlistAll+_reviewlist
browser.find_element_by_xpath('//i[@class="u-icon u-icon-arrowRight"]').click()
# 隐式等待方式,10秒
browser.implicitly_wait(10)
# 强制等待0.1秒,保险起见
print("第{}页".format(n))
time.sleep(0.1)
import pandas as pd
df_write = pd.DataFrame(reviewlistAll)
df_write.to_csv('review.csv', index=False, encoding="utf_8_sig")
结果:



















 1689
1689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











