







概念理解
事务隔离级别(数据库层面)和传播机制(代码层面spring框架)的区别?
事务隔离级别和事务传播机制都是对事务行为的规范,但二者描述的侧重点却不同。本文这里所说的事务隔离级别和事务传播机制指的是 Spring 框架中的机制。
1、事务隔离级别
事务隔离级别是对事务 4 大特性中隔离性的具体体现,使用事务隔离级别可以控制并发事务在同时执行时的某种行为。
比如,有两个事务同时操作同一张表,此时有一个事务修改了这张表的数据,但尚未提交事务,那么在另一个事务中,要不要(或者说能不能)看到其他事务尚未提交的数据呢?
这个问题的答案就要看事务的隔离级别了,不同的事务隔离级别,对应的行为模式也是不一样的(有些隔离级别可以看到其他事务尚未提交的数据,有些事务隔离级别看不到其他事务尚未提交的数据),这就是事务隔离级别的作用。
Sping 中的事务隔离级别有 5 种,它们分别是:
DEFAULT:Spring 中默认的事务隔离级别,以连接的数据库的事务隔离级别为准;
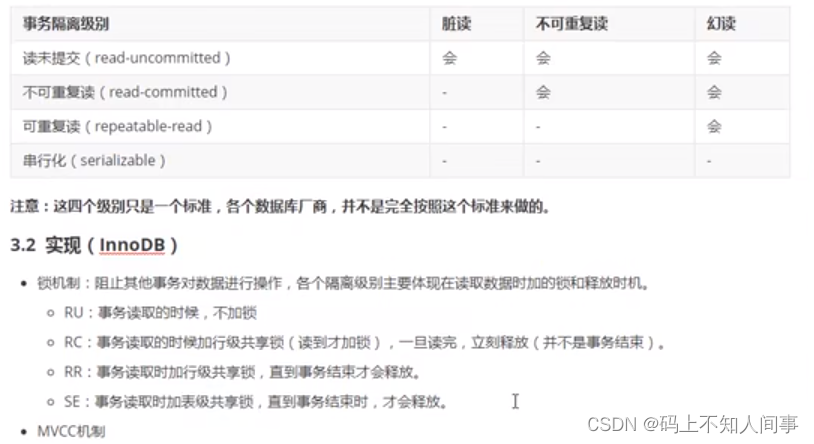
READ_UNCOMMITTED:读未提交,也叫未提交读,该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以读取到其他事务中未提交的数据,而未提交的数据可能会发生回滚,因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读;
READ_COMMITTED:读已提交,也叫提交读,该隔离级别的事务能读取到已经提交事务的数据,因此它不会有脏读问题。但由于在事务的执行中可以读取到其他事务提交的结果,所以在不同时间的相同 SQL 查询中,可能会得到不同的结果,这种现象叫做不可重复读;
REPEATABLE_READ:可重复读,它能确保同一事务多次查询的结果一致。但也会有新的问题,比如此级别的事务正在执行时,另一个事务成功的插入了某条数据,但因为它每次查询的结果都是一样的,所以会导致查询不到这条数据,自己重复插入时又失败(因为唯一约束的原因)。明明在事务中查询不到这条信息,但自己就是插入不进去,这就叫幻读
(Phantom Read);
SERIALIZABLE:串行化,最高的事务隔离级别,它会强制事务排序,使之不会发生冲突,从而解决了脏读、不可重复读和幻读问题,但因为执行效率低,所以真正使用的场景并不多。
所以,相比于 MySQL 的事务隔离级别,Spring 中多了一种 DEFAULT 的事务隔离级别。事务隔离级别与问题的对应关系如下:
脏读:一个事务读取到了另一个事务修改的数据之后,后一个事务又进行了回滚操作,从而导致第一个事务读取的数据是错误的。
不可重复读:一个事务两次查询得到的结果不同,因为在两次查询中间,有另一个事务把数据修改了。
幻读:一个事务两次查询中得到的结果集不同,因为在两次查询中另一个事务有新增了一部分数据。
Spring 中,事务隔离级别可以通过 @Transactional(isolation = Isolation.DEFAULT) 来设置。
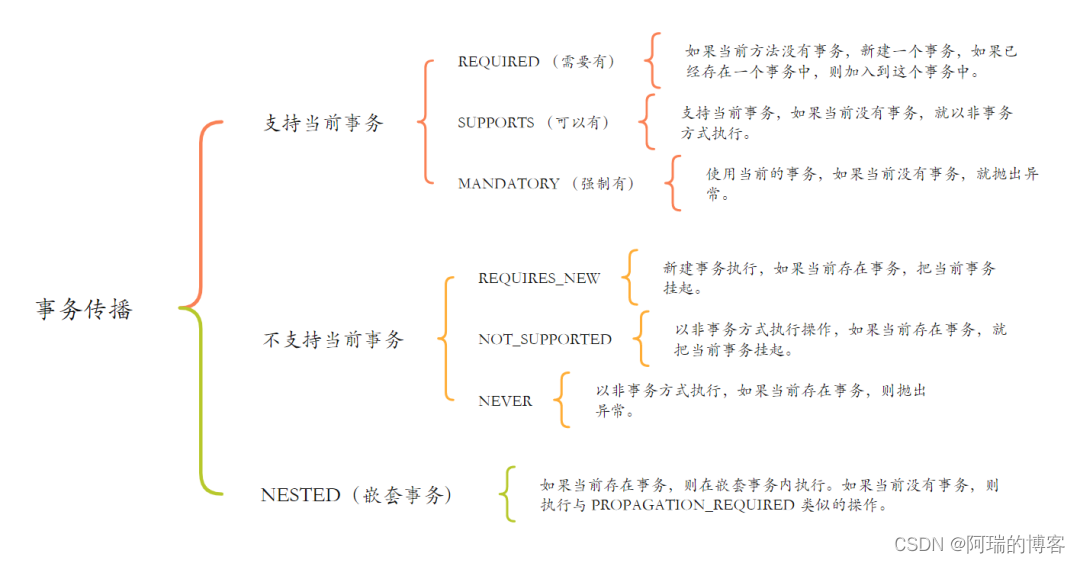
2、事务传播机制
Spring 事务传播机制是指,包含多个事务的方法在相互调用时,事务是如何在这些方法间传播的。Spring 事务传播机制可使用 @Transactional(propagation=Propagation.REQUIRED) 来设置,Spring 事务传播机制的级别包含以下 7 种:
Propagation.REQUIRED:默认的事务传播级别,它表示如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
Propagation.SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
Propagation.MANDATORY:(mandatory:强制性)如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
Propagation.REQUIRES_NEW:表示创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务, Propagation.REQUIRES_NEW 修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
Propagation.NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
Propagation.NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
Propagation.NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED。
以上 7 种传播机制,可分为以下 3 类:
偏本质认识

分布式事务
当系统采用分布式部署,数据就会分散在各个子系统的数据库。在一个子系统中保证数据要么全部提交,要么全部失败的操作叫本地事务。在分布式系统中,分布式事务就是指各个子系统的数据要么全部提交成功,要么全部提交失败。比如用户下单,需要订单系统生成订单、付款系统向用扣款成功、库存系统扣减商品库存等操作,如果已生成订单并付款成功,库存系统扣减商品数量失败,就会产生脏数据。
分布式事务通过引入协调者的角色,对各个子系统状态进行统一。
5.1 CAP理论
一个经典的分布式系统理论。CAP理论告诉我们:一个分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最多只能同时满足其中两项。
5.1.1 一致性
在分布式环境下,一致性是指数据在多个副本之间能否保持一致的特性。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一直的状态。
对于一个将数据副本分布在不同分布式节点上的系统来说,如果对第一个节点的数据进行了更新操作并且更新成功后,却没有使得第二个节点上的数据得到相应的更新,于是在对第二个节点的数据进行读取操作时,获取的依然是老数据(或称为脏数据),这就是典型的分布式数据不一致的情况。在分布式系统中,如果能够做到针对一个数据项的更新操作执行成功后,所有的用户都可以读取到其最新的值,那么这样的系统就被认为具有强一致性
5.1.2 可用性
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里的重点是"有限时间内"和"返回结果"。
"有限时间内"是指,对于用户的一个操作请求,系统必须能够在指定的时间内返回对应的处理结果,如果超过了这个时间范围,那么系统就被认为是不可用的。另外,"有限的时间内"是指系统设计之初就设计好的运行指标,通常不同系统之间有很大的不同,无论如何,对于用户请求,系统必须存在一个合理的响应时间,否则用户便会对系统感到失望。
"返回结果"是可用性的另一个非常重要的指标,它要求系统在完成对用户请求的处理后,返回一个正常的响应结果。正常的响应结果通常能够明确地反映出队请求的处理结果,即成功或失败,而不是一个让用户感到困惑的返回结果。
5.1.3 分区容错性
分区容错性约束了一个分布式系统具有如下特性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
网络分区是指在分布式系统中,不同的节点分布在不同的子网络(机房或异地网络)中,由于一些特殊的原因导致这些子网络出现网络不连通的状况,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干个孤立的区域。需要注意的是,组成一个分布式系统的每个节点的加入与退出都可以看作是一个特殊的网络分区。
既然一个分布式系统无法同时满足一致性、可用性、分区容错性三个特点,所以我们就需要抛弃一样:
选 择 说 明
CA 放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择
AP 放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多NoSQL系统就是如此
CP 放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用
5.2 BASE理论
5.2.1 基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性----注意,这绝不等价于系统不可用。比如:
1.响应时间上的损失。正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒
2.系统功能上的损失:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面
5.2.2 软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
5.2.3 最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
总的来说,BASE理论面向的是大型高可用可扩展的分布式系统,和传统的事物ACID特性是相反的,它完全不同于ACID的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态。但同时,在实际的分布式场景中,不同业务单元和组件对数据一致性的要求是不同的,因此在具体的分布式系统架构设计过程中,ACID特性和BASE理论往往又会结合在一起。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









