







 本文介绍了解决Gplearn在使用n_jobs>1进行并行训练时遇到的1MB内存限制问题。通过在fit方法中添加max_nbytes参数为'50M',有效避免了内存溢出。
本文介绍了解决Gplearn在使用n_jobs>1进行并行训练时遇到的1MB内存限制问题。通过在fit方法中添加max_nbytes参数为'50M',有效避免了内存溢出。
主要原因是在训练的时候设置n_jobs>1,进行并行运算。而joblib默认每一个worker的最大内存是1M,当数据较大时,就会超过该限制,发生错误。
解决方法:
直接在gplearn的fit方法中找到调用Parallel方法的位置,添加max_nbytes=‘50M’
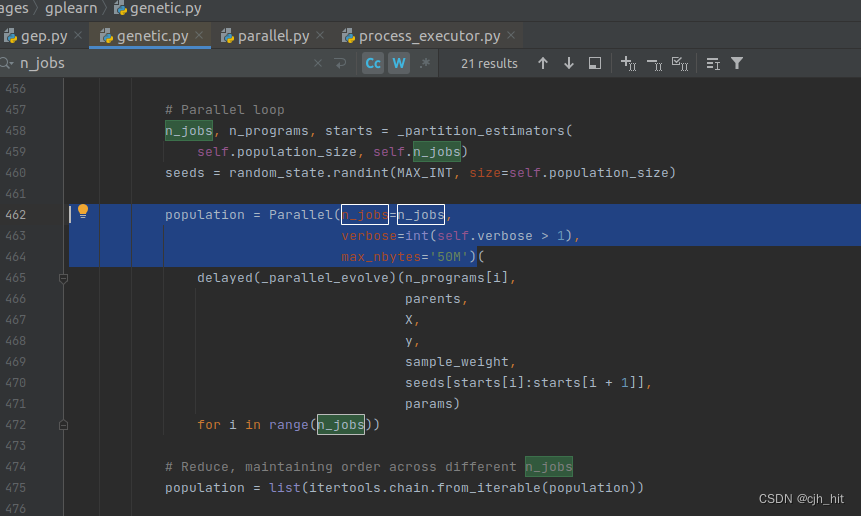
主要原因是在训练的时候设置n_jobs>1,进行并行运算。而joblib默认每一个worker的最大内存是1M,当数据较大时,就会超过该限制,发生错误。
解决方法:
直接在gplearn的fit方法中找到调用Parallel方法的位置,添加max_nbytes=‘50M’
 340
2615
370
857
976
340
2615
370
857
976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























