







了解ForkJoin之前,先来了解一下stream()方法。
ArrayList<String> strings = new ArrayList<String>();
Stream<String> stream = strings.stream();
Stream<String> stringStream = strings.parallelStream();
上面的代码有着parallelStream()、stream()两个方法。他们分别代表着可多线程遍历,单线程遍历。而他们的底层均是ForkJoin实现。主要看parallelStream()的使用。
import java.util.ArrayList;
import java.util.stream.Stream;
/**
* @author 龙小虬
* @date 2021/5/6 16:45
*/
public class Main {
public static void main(String[] args) {
ArrayList<String> strings = new ArrayList<String>();
for (int i = 0; i < 10; i++) {
strings.add("i:"+i);
}
Stream<String> stringStream = strings.parallelStream();
stringStream.forEach((k)->{
System.out.println(Thread.currentThread().getName()+","+k);
});
}
}
运行结果:
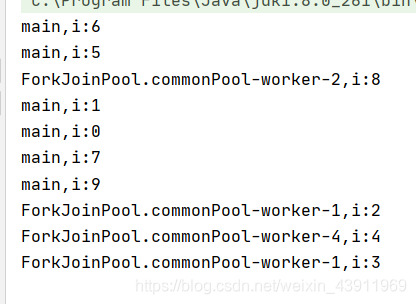
使用了多个线程去遍历。
可以看到它使用的是线程池,那么我们可以利用ForkJoin做一个简单的累加
代码:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
/**
* @author 龙小虬
* @date 2021/5/6 16:54
*/
public class ForkJoinDemo extends RecursiveTask<Long> {
private long max = 200;
private long start;
private long end;
public ForkJoinDemo(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0L;
if (end - start < max) {
System.out.println(Thread.currentThread().getName() + ",start:" + start + ",end:" + end);
for (long i = start; i <= end; i++) {
sum += i;
}
} else {
long l = (end + start) / 2;
ForkJoinDemo left = new ForkJoinDemo(start, l);
left.fork();
ForkJoinDemo rigt = new ForkJoinDemo(l + 1, end);
rigt.fork();
left.join();
rigt.join();
try {
sum = left.get() + rigt.get();
} catch (Exception e) {
e.printStackTrace();
}
}
return sum;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinDemo forkJoinDemo = new ForkJoinDemo(1L, 400L);
ForkJoinTask<Long> submit = forkJoinPool.submit(forkJoinDemo);
System.out.println(submit.get());
}
}
写出来,优点类似于递归,但是不同的是,他是多个线程组合而成的,这样利用可以大幅度的提升运行时间,但是经过测试,只有在end数据过大并且粒度大的情况下,使用ForkJoin才能比单线程效率高,当然,不同的场景不同,但是,粒度大师主要问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











