







本文主要介绍Transformer的核心Self-Attention的原理。
目录
第1章 向量点积
1.1 Self-Attention公式
Transformer原论文中将核心部分称为Scaled Dot-Product Attention,缩放点积注意力,最核心的公式为:
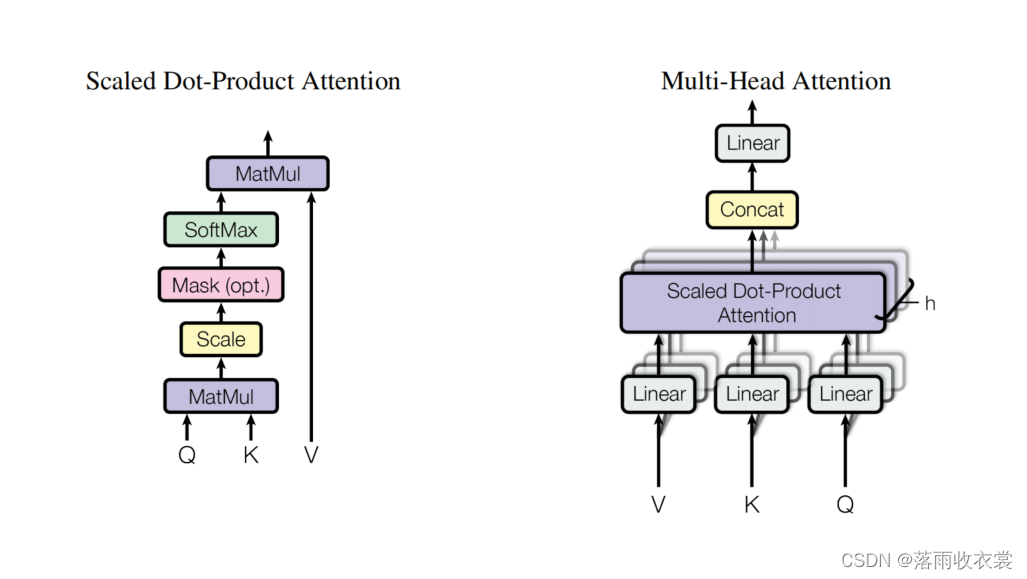
Q:Query,查询,由输入矩阵变换而来;
K:key,键,由输入矩阵变换而来;
V:value,值,由输入矩阵变换而来。
1.2 向量点积
对于给定的一组向量与
,点积表示为:
本文主要介绍Transformer的核心Self-Attention的原理。
目录
Transformer原论文中将核心部分称为Scaled Dot-Product Attention,缩放点积注意力,最核心的公式为:
Q:Query,查询,由输入矩阵变换而来;
K:key,键,由输入矩阵变换而来;
V:value,值,由输入矩阵变换而来。
对于给定的一组向量与
,点积表示为:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























