







文章目录
Java I/O系统
对于程序语言设计者来说,设计一个令人满意的I/O(输入输出)系统,是件艰巨的任务
摘自《Thinking in Java》
File类
- 一个File类的对象,表示了磁盘上的文件或目录
- File类提供了与平台无关的方法来对磁盘上的文件或目录进行操作
- File类直接处理文件和文件系统。
- File类没有指定信息怎样从文件读取或向文件存储
- File类描述了文件本身的属性
- File对象用来获取或处理与磁盘文件相关的信息,例如权限,时间,日期和目录路径
- File类还可以浏览子目录层次结构
- java.io包中的File类提供了与具体平台无关的方式来描述目录和文件对象的属性功能。 其中包含大量的方法可用来获取路径、 目录和文件的相关信息, 并对它们进行创建、 删除、 改名等管理工作。 因为不同的系统平台, 对文件路径的描述不尽相同。 为做到平台无关, 在Java语言中, 使用抽象路径等概念。 Java自动进行不同系统平台的文件路径描述与抽象文件路径之间的转换。
- File类的直接父类是Object类。
- 下面的构造方法可以用来生成File 对象:
– File(String directoryPath)
File(String directoryPath, String filename)
File(File dirObj, String filename)
• 这里, directoryPath是文件的路径名,filename 是文件名, dirObj 是一个指定目录的File 对象
路径分隔符
在windows系统上路径分隔符为\但是Java中\后面跟的是转义字符,所以我们要用\或/,推荐使用正斜杠/因为这样你的class文件不仅可以在windows系统上运行还可以在其他系统上运行。
package JavaBase.IO;
import java.io.File;
import java.io.IOException;
public class FileTest1 {
public static void main(String[] args){
File file = new File("D:/test.txt");//指定文件的路径和文件名
try {
System.out.println(file.createNewFile());//创建文件如果成功返回true
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果是:
true

separator
separator表示路径分隔符,你在哪个系统他就会根据你的系统形成分隔符,如果你光写File.separator,它会给你分配你当前文件的根目录。
package JavaBase.IO;
import java.io.File;
import java.io.IOException;
public class FileTest8 {
public static void main(String[] args) {
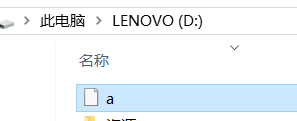
File file = new File("D:" + File.separator + "a");
try {
System.out.println(file.createNewFile());
} catch (IOException e) {
e.printStackTrace();
}
}
}
结果
package JavaBase.IO;
import java.io.File;
import java.io.IOException;
public class FileTest2 {
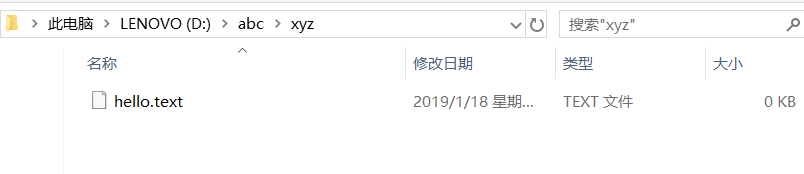
public static void main(String[] args) {
File file = new File("D:/abc");
File file1 = new File(file, "xyz/hello.text");
try {
file1.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果没有在系统上建好路径,则会创建失败并报错。
java.io.IOException: 系统找不到指定的路径。
at java.io.WinNTFileSystem.createFileExclusively(Native Method)
at java.io.File.createNewFile(File.java:1012)
at JavaBase.IO.FileTest2.main(FileTest2.java:13)
如果建好路径则会成功:
举例说明:
File myFile = new File(" myfile. txt");
File myDir = new File(" MyDocs");
File myFile = new File( myDir, “myfile.txt”);
这些构造方法取决于访问文件的方式。例如,若在应用程序里只用一个文件,第一种创建文件的结构是最容易的。但若在同一目录里打开数个文件,则后种方法更好一些。
目录管理
– 目录操作的主要方法为:
– public boolean mkdir() 根据抽象路径名创建目录。
– public String[] list() 返回抽象路径名表示路径中的文件名和目录名。
文件管理
– 在进行文件操作时, 常需要知道一个关于文件的信息。Jave的File类提供了方法来操纵文件和获得一个文件的信息。 另外, File类还可以对目录和文件进行删除、属性修改等管理工作
package JavaBase.IO;
import java.io.File;
public class FileTest3 {
public static void main(String[] args) {
File file = new File("D:/abc/xyz/hello");
System.out.println(file.mkdir());//如果创建的最后一级目录的上一级目录也不存在则会创建失败
System.out.println(file.mkdirs());//创建所有的目录
}
}
我们先删除之间创建的abc文件夹运行结果为
false
true

System.out.println(file.isDirectory());//判断是否是目录
System.out.println(file.isFile());//判断是否是文件
输出
true
false
目录是一个包含其他文件和路径列表的File类。
当你创建一个File 对象且它是目录时,isDirectory( ) 方法返回ture。这种情况下,可以调用该对象的list( )方法来提取该目录内部其他文件和目录的列表。
package JavaBase.IO;
import java.io.File;
public class FileTest4 {
public static void main(String[] args) {
File file = new File("D:/abc");
/* //获取当前目录的所有文件名以字符串数组的形式返回
String[] names = file.list();
for (String name : names) {
System.out.println(name);
}*/
File[] files = file.listFiles();
for (File f : files) {
System.out.println(f.getName());
System.out.println(f.getParent());
}
}
}
结果是:
xyz
D:\abc
File 类定义了很多获取File对象标准属性的方法。例如getName( )返回文件名,getParent( )返回父目录名, exists( )在文件存在的情况下返回true,反之返回false。然而File类是不对称的。说它不对称,意思是虽然存在允许验证一个简单文件对象属性的很多方法,但是没有相应的方法来改变这些属性
- File类中的常用方法
String getName()
String getPath()
String getAbsolutePath()
String getParent()
boolean renameTo( File newName)
long length()
boolean delete()
boolean mkdir()
String[] list()
– boolean exists()
– boolean canWrite()
– boolean canRead()
– boolean isFile()
– boolean isDirectory()
package JavaBase.IO;
import java.io.File;
public class FileTest5 {
public static void main(String[] args) {
File file = new File("D:/abc/xyz/hello");
file.delete();
}
}
结果是刚刚创建的hello文件夹消失了,并不是放到回收站中,而是彻底删除。
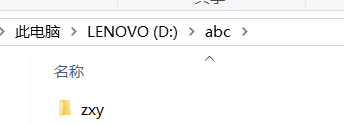
public class FileTest5 {
public static void main(String[] args) {
File file = new File("D:/abc/xyz");
// file.delete();
File file1 = new File("D:/abc/zxy");
file.renameTo(file1);
}
}
结果是
使用FilenameFilter
– 希望能够限制由list( )方法返回的文件数目,使它仅返回那些与一定的文件名方式或者过滤(filter)相匹配的文件。为达到这样的目的,必须使用list( )的第二种形式 (方法重载)
– String[ ] list(FilenameFilter FFObj)
– 该形式中, FFObj是一个实现FilenameFilter接口的类的对象
package JavaBase.IO;
import java.io.File;
public class FileTest6 {
public static void main(String[] args) {
File file = new File("D:/abc/zxy");
String[] names = file.list();
for (String name : names) {
if(name.endsWith(".java")){//判断文件是否以.java结尾
System.out.println(name);
}
}
}
}
结果是:
a - 副本 (2).java
a - 副本 (3).java
a - 副本 (4).java
a - 副本.java
a.java
FilenameFilter仅定义了一个方法, accept( )。该方法被列表中的每个文件调用一次。它的通常形式如下:
boolean accept(File directory, String filename)
当被directory 指定的目录中的文件(也就是说,那些与filename 参数匹配的文件)包含在列表中时, accept( )方法返回true ,当这些文件没有包括在列表中时, accept( )返回false。
package JavaBase.IO;
import java.io.File;
import java.io.FilenameFilter;
public class FileTest7 {
public static void main(String[] args) {
File file = new File("D:/abc/zxy");
String[] names = file.list(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
if (name.endsWith(".java")) {
return true;
}
return false;
}
});
for (String name : names) {
System.out.println(name);
}
}
}
利用匿名内部类,和策略模式实现
a - 副本 (2).java
a - 副本 (3).java
a - 副本 (4).java
a - 副本.java
a.java
listFiles()方法
File[ ] listFiles( )
File[ ] listFiles(FilenameFilter FFObj)
File[ ] listFiles(FileFilter FObj)
上述三种形式以File对象数组的形式返回文件列表,而不是用字符串形式返回。第一种形式返回所有的文件,第二种形式返回满足指定FilenameFilter接口的文件。除了返回一个File 对象数组,这两个listFiles( )方法就像list( )方法一样工作。
第三种listFiles( )形式返回满足指定FileFilter的路径名的文件。 FileFilter只定义了一个 accept( )方法,该方法被列表中的每个文件调用一次。它的通常形式如下:boolean accept(File path)如果文件被包括在列表中(即与path参数匹配的文件), accept( )方法返回true,如果不被包括,则返回false。
流类
流的概念
– Java程序通过流来完成输入/输出。流是生产或消费信息的抽象。流通过Java的输入/输出系统与物理设备链接。尽管与它们链接的物理设备不尽相同,所有流的行为具有同样的方式。这样,相同的输入/输出类和方法适用于所有类型的外部设备。这意味着一个输入流能够抽象多种不同类型的输入:从磁盘文件,从键盘或从网络套接字。同样,一个输出流可以输出到控制台,磁盘文件或相连的网络。流是处理输入/输出的一个洁净的方法,例如它不需要代码理解键盘和网络的不同。 Java中流的实现是在java.io包定义的类层次结构内部的。
输入/输出流概念
- 输入/输出时, 数据在通信通道中流动。 所谓“数据流(stream)”指的是所有数据通信通道之中,数据的起点和终点。 信息的通道就是一个数据流。只要是数据从一个地方“流” 到另外一个地方,这种数据流动的通道都可以称为数据流。
- 输入/输出是相对于程序来说的。 程序在使用数据时所扮演的角色有两个:一个是源, 一个是目的。若程序是数据流的源, 即数据的提供者, 这个数据流对程序来说就是一个“输出数据流” (数据从程序流出)。 若程序是数据流的终点, 这个数据流对程序而言就是一个“输入数据流” ( 数据从程序外流向程序)输入/输出是相对于程序来说的。 程序在使用数据时所扮演的角色有两个:一个是源, 一个是目的。若程序是数据流的源, 即数据的提供者, 这个数据流对程序来说就是一个“输出数据流” (数据从程序流出)。 若程序是数据流的终点, 这个数据流对程序而言就是一个“输入数据流” ( 数据从程序外流向程序)
输入/输出类
- 在java.io包中提供了60多个类(流) 。
- 从功能上分为两大类:输入流和输出流。
- 从流结构上可分为字节流(以字节为处理单位或称面向字节) 和字符流(以字符为处理单位或称面向字符)。
- 字节流的输入流和输出流基础是InputStream和OutputStream这两个抽象类, 字节流的输入输出操作由这两个类的子类实现。 字符流是Java 1.1版后新增加的以字符为单位进行输入输出处理的流, 字符流输入输出的基础是抽象类Reader和Writer
字节流和字符流
- Java 2 定义了两种类型的流:字节流和字符流。字节流(byte stream)为处理字节的输入和输出提供了方便的方法。例如使用字节流读取或写入二进制数据。字符流(character stream)为字符的输入和输出处理提供了方便。它们采用了统一的编码标准,因而可以国际化。当然,在某些场合,字符流比字节流更有效。
- Java的原始版本(Java 1.0)不包括字符流,因此所有的输入和输出都是以字节为单位的。 Java 1.1中加入了字符流的功能
- 需要声明: ==在最底层,所有的输入/输出都是字节形式的。==基于字符的流只为处理字符提供方便有效的方法
- 字节流类(Byte Streams) 字节流类用于向字节流读写8位二进制的字节。一般地,字节流类主要用于读写诸如图象或声音等的二进制数据。
- 字符流类(Character Streams) 字符流类用于向字符流读写16位二进制字符。

流的分类
两种基本的流是:输入流(Input Stream)和输出流(Output Stream)。可从中读出一系列字节的对象称为输入流。而能向其中写入一系列字节的对象称为输出流。
输入流
读数据的逻辑为:
open a stream
while more information
read information
close the stream
输出流
写数据的逻辑为:
open a stream
while more information
write information
close the stream
- 节点流:从特定的地方读写的流类,例如:磁盘或一块内存区域。
- 过滤流:使用节点流作为输入或输出。过滤流是使用一个已经存在的输入流或输出流连接创建的。
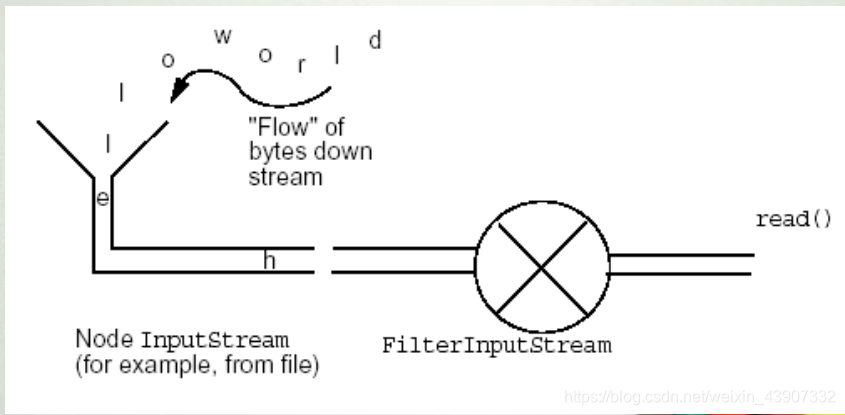
字节流
- 字节流类为处理字节式输入/输出提供了丰富的环境。一个字节流可以和其他任何类型的对象并用,包括二进制数据。这样的多功能性使得字节流对很多类型的程序都很重要。
- 字节流类以InputStream 和OutputStream为顶层类,他们都是抽象类(abstract)
- 抽象类InputStream 和 OutputStream定义了实现其他流类的关键方法。最重要的两种方法是read()和write(),它们分别对数据的字节进行读写。两种方法都在InputStream 和OutputStream中被定义为抽象方法。 它们被派生的流类重写。每个抽象类都有多个具体的子类,这些子类对不同的外设进行处理,例如磁盘文件,网络连接,甚至是内存缓冲区。要使用流类,必须导入java.io包
InputStream
- 三个基本的读方法
abstract int read() : 读取一个字节数据,并返回读到的数据,如果返回-1,表示读到了输入流的末尾。
int read(byte[] b) : 将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。
int read(byte[] b, int off, int len) : 将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。 off指定在数组b中存放数据的起始偏移位置; len指定读取的最大字节数。 - 思考:为什么只有第一个read方法是抽象的,而其余两个read方法都是具体的?
• 因为第二个read方法依靠第三个read方法来实现,而第三个read方法又依靠第一个read方法来实现,所以说只有第一个read方法是与具体的I/O设备相关的,它需要InputStream的子类来实现。 - 其它方法
long skip(long n) : 在输入流中跳过n个字节,并回实际跳过的字节数。
int available() : 返回在不发生阻塞的情况下,可取的字节数。
void close() : 关闭输入流,释放和这个流相关的统资源。
void mark(int readlimit) : 在输入流的当前位置置一个标记,如果读取的字节数多于readlimit设置的则流忽略这个标记。
void reset() : 返回到上一个标记。
boolean markSupported() : 测试当前流是否mark和reset方法。如果支持,返回true,否则返回false。 - 该类的所有方法在出错条件下引发一个IOException 异常。
通过打开一个到数据源(文件、内存或网络端口上的数据)的输入流,程序可以从数据源上顺序读取数据。
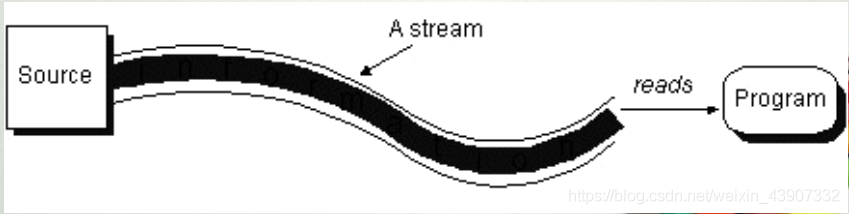
java.io包中InputStream的类层次
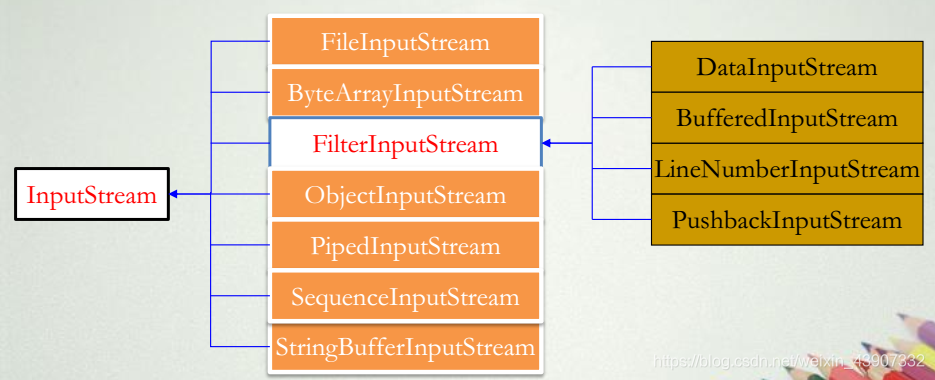
- InputStream中包含一套字节输入流需要的方法,可以完成最基本的从输入流读入数据的功能。 当Java程序需要外设的数据时, 可根据数据的不同形式, 创建一个适当的InputStream子类类型的对象来完成与该外设的连接, 然后再调用执行这个流类对象的特定输入方法来实现对相应外设的输入操作。
- InputStream 类 子 类 对 象 自 然 也 继 承 了InputStream类的方法。 常用的方法有:读数据的方 法 read() , 获 取 输 入 流 字 节 数 的 方 法available(), 定位输入位置指针的方法skip()、reset()、 mark()等。
OutputStream
- 三个基本的写方法
abstract void write(int b) : 往输出流中写入一个字节。
void write(byte[] b) : 往输出流中写入数组b中的所有字节。
void write(byte[] b, int off, int len) : 往输出流中写入数组b中从偏移量off开始的len个字节的数据 - 其它方法
void flush() : 刷新输出流,强制缓冲区中的输出字节被写出。
void close() : 关闭输出流,释放和这个流相关的系统资源。 - OutputStream是定义了流式字节输出模式的抽象类。该类的所有方法返回一个void 值并且在出错情况下引发一个IOException异常。
- 通过打开一个到目标的输出流,程序可以向外部目标顺序写数据
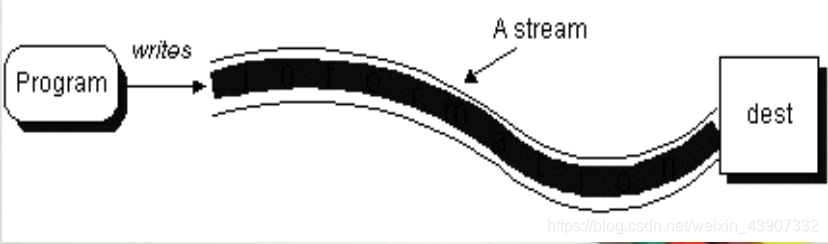
java.io包中OutputStream的类层次
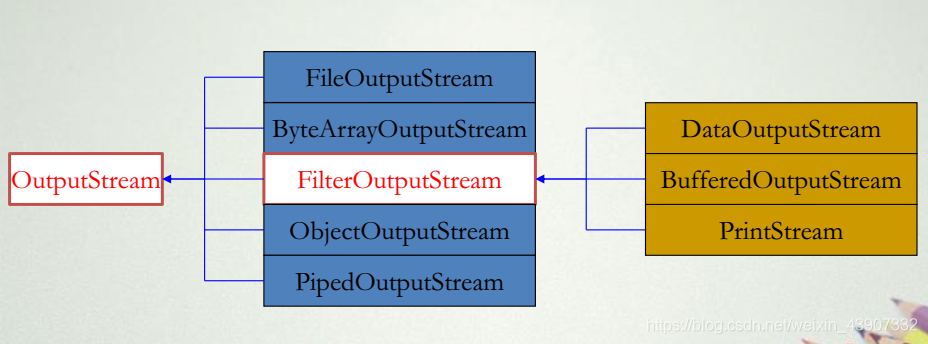
- OutputStream中包含一套字节输出流需要的方法,可以完成最基本的输出数据到输出流的功能。 当Java程序需要将数据输出到外设时, 可根据数据的不同形式, 创建一个适当的OutputStream子类类型的对象来完成与该外设的连接, 然后再调用执行这个流类对象的特定输出方法来实现对相应外设的输出操作。
- OutputStream类子类对象也继承了OutputStream类的方法。 常用的方法有:写数据的方法write(),关闭流方法close()等。
过滤流
- 在InputStream类和OutputStream类子类中,FilterInputStream 和 FilterOutputStream过滤流抽象类又派生出DataInputStream和DataOutputStream数据输入输出流类等子类。
- 过滤流的主要特点是在输入输出数据的同时能对所传输的数据做指定类型或格式的转换, 即可实现对二进制字节数据的理解和编码转换。
- 数据输入流DataInputStream中定义了多个针对不同类型数 据 的 读 方 法 , 如 readByte() 、readBoolean() 、readShort() 、 readChar() 、 readInt() 、 readLong() 、readFloat()、 readDouble()、 readLine()等。
- 数据输出流DataOutputStream中定义了多个针对不同类型数 据 的 写 方 法 , 如 writeByte() 、 writeBoolean() 、writeShort()、 writeChar()、 writeInt()、 writeLong()、writeFloat()、 writeDouble()、 writeChars()等。
- 过滤流在读/写数据的同时可以对数据进行处理,它提供了同步机制,使得某一时刻只有一个线程可以访问一个I/O流,以防止多个线程同时对一个I/O流进行操作所带来的意想不到的结果。
- 类FilterInputStream和FilterOutputStream分别作为所有过滤输入流和输出流的父类。
ByteArrayInputStream(字节数组输入流)
ByteArrayInputStream是把字节数组当成源的输入流。该类有两个构造方法,每个构造方法需要一个字节数组提供数据源
– ByteArrayInputStream(byte array[ ])
– ByteArrayInputStream(byte array[ ], int start, int numBytes)
– 这里, array是输入源。第二个构造方法创建了一个InputStream类,该类从字节数组的子集生成,以start指定索引的字符为起点,长度由numBytes决定
下面的例子创建了两个ByteArrayInputStream,用字母表的字节表示初始化它们
import java.io.*;
class ByteArrayInputStreamDemo {
public static void main(String args[]) throws IOException {
String tmp = "abcdefghijklmnopqrstuvwxyz";
byte b[] = tmp.getBytes();
ByteArrayInputStream input1 = new ByteArrayInputStream(b);
ByteArrayInputStream input2 = new ByteArrayInputStream(b, 0, 3);
} }
input1对象包含整个字母表中小写字母, input2仅包含开始的三个字母。
package JavaBase.IO;
import java.io.ByteArrayInputStream;
public class ByteArrayInputStreamTest1 {
public static void main(String[] args) {
String temp = "abcdefg";
byte[] bytes = temp.getBytes();
ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);
for (int i = 0; i < 2; i++) {
int c;
//read每次读一个字节,虽然read返回的是,但是只取低8位Byte,前面24个忽略掉
while (-1 != (c = inputStream.read())) {
if (0 == i) {
System.out.println((char) c);
}
else{
System.out.println(Character.toUpperCase((char) c));
}
}
System.out.println();
//重新回到最开始的位置
inputStream.reset();
}
}
}
结果是:
a
b
c
d
e
f
g
A
B
C
D
E
F
G
ByteArrayInputStream实现mark( )和reset( )方法。然而,如果 mark( )不被调用, reset( )在流的开始设置流指针——该指针是传递给构造方法的字节数组的首地址
该例先从流中读取每个字符,然后以小写字母形式打印。然后重新设置流并从头读起,这次在打印之前先将字母转换成大写字母
ByteArrayOutputStream(字符数组输出流)
- ByteArrayInputStream实现mark( )和reset( )方法。然而,如果 mark( )不被调用, reset( )在流的开始设置流指针——该指针是传递给构造方法的字节数组的首地址
- 该例先从流中读取每个字符,然后以小写字母形式打印。然后重新设置流并从头读起,这次在打印之前先将字母转换成大写字母
- ByteArrayOutputStream是一个把字节数组当作输出流的实现。 ByteArrayOutputStream 有两个构造方法
– ByteArrayOutputStream( )
– ByteArrayOutputStream(int numBytes)
– 在第一种形式里,一个32位字节的缓冲区被生成。第二个构造方法生成一个numBytes大小的缓冲区。缓冲区保存在ByteArrayOutputStream的受保护的buf 成员里。缓冲区的大小在需要的情况下会自动增加。缓冲区保存的字节数是由ByteArrayOutputStream的受保护的count域保存的
package JavaBase.IO;
import java.io.ByteArrayOutputStream;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class ByteArrayOutputStreamTest1 {
public static void main(String[] args) throws Exception{
ByteArrayOutputStream f = new ByteArrayOutputStream();
String string = "hello world welcome";
byte[] buffer = string.getBytes();
//不管是什么输出流都继承OutputStream,自然write也继承过来了
f.write(buffer);
//把数组从流中取出
byte[] result = f.toByteArray();
for (int i = 0; i < result.length; i++) {
System.out.println((char)result[i]);
}
OutputStream outputStream = new FileOutputStream("text.txt");
f.writeTo(outputStream);
f.close();
outputStream.close();
}
}
结果是:
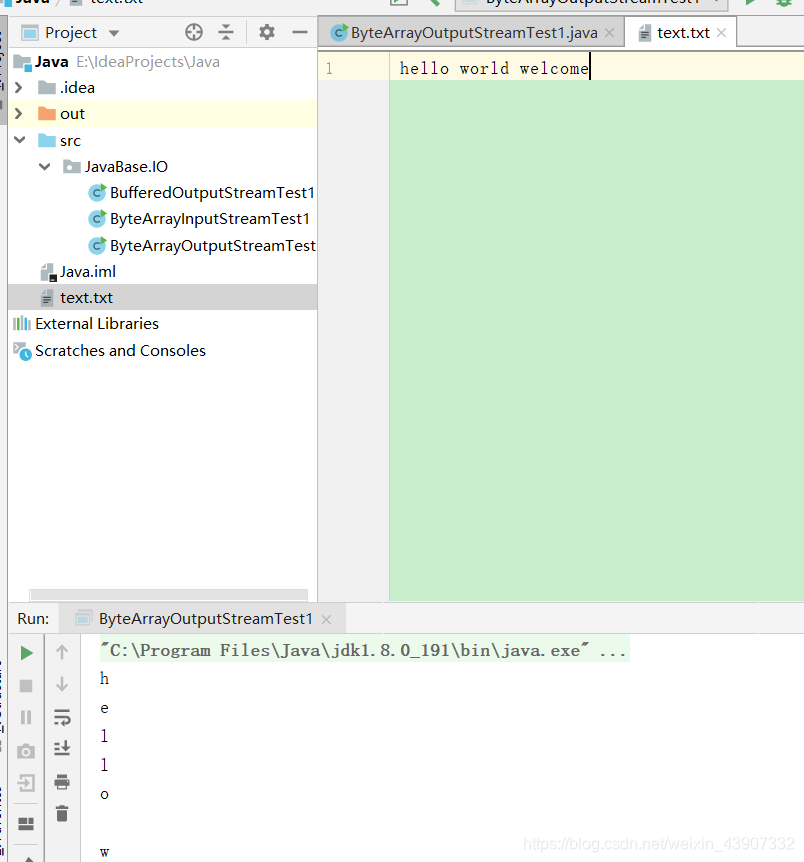
该例用 writeTo( )这一便捷的方法将f 的内容写入test.txt
– writeTo:将此字节数组输出流的全部内容写入到指定的输出流参数中
– reset:将此字节数组输出流的 count 字段重置为零,从而丢弃输出流中目前已累积的所有输出。通过重新使用已分配的缓冲区空间,可以再次使用该输出流
缓冲字节流
- 若处理的数据量较多,为避免每个字节的读写都对流进行,可以使用过滤流类的子类缓冲流。缓冲流建立一个内部缓冲区,输入输出数据先读写到缓冲区中进行操作,这样可以提高文件流的操作效率。
BufferedInputStream(缓冲输入流)
- 缓冲输入/输出是一个非常普通的性能优化。 Java的BufferedInputStream 类允许把任何InputStream类“包装” 成缓冲流并使它的性能提高
BufferedInputStream 有两个构造方法
– BufferedInputStream(InputStream inputStream)
– BufferedInputStream(InputStream inputStream, int bufSize)
– 第一种形式创建BufferedInputStream流对象并为以后的使用保存InputStream参数in,并创建一个内部缓冲区数组来保存输入数据。
– 第二种形式用指定的缓冲区大小size创建BufferedInputStream流对象,并为以后的使用保存InputStream参数in。 - 缓冲一个输入流同样提供了在可用缓冲区的流内支持向后移动的必备基础。除了在任何InputStream类中执行的read( )和skip( )方法外,BufferedInputStream 同样支持mark( ) 和reset( )方法。
BufferedInputStream.markSupported( )返回true是这一支持的体现。 - 当创建缓冲输入流BufferedInputStream时,一个输入缓冲区数组被创建,来自流的数据填入缓冲区,一次可填入许多字节
参见程序 BufferedInputStream1.java
– public void mark(int readlimit) :在此输入流中标记当前的位置。对 reset 方法的后续调用会在最后标记的位置重新定位此流,以便后续读取重新读取相同的字节
– public void reset() :将此流重新定位到对此输入流最后调用 mark 方法时的位置
BufferOutputStream(缓冲输出流)
- 缓冲输出流BufferedOutputStream类提供和FileOutputStream类同样的写操作方法,但所有输出全部写入缓冲区中。当写满缓冲区或关闭输出流时,它再一次性输出到流,或者用flush()方法主动将缓冲区输出到流。
- BufferedOutputStream与任何一个OutputStream相同,除了用一个另外的flush( ) 方法来保证数据缓冲区被写入到实际的输出设备。BufferedOutputStream通过减小系统写数据的时间而提高性能不像缓冲输入,缓冲输出不提供额外的功能, Java中输出缓冲区是为了提高性能的。下面是两个可用的构造方法
– BufferedOutputStream(OutputStream outputStream)
– BufferedOutputStream(OutputStream outputStream, int bufSize)
– 第一种形式创建了一个使用512字节缓冲区的缓冲流。
– 第二种形式,缓冲区的大小由bufSize参数传入。 - 用flush()方法更新流
- 要想在程序结束之前将缓冲区里的数据写入磁盘, 除了填满缓冲区或关闭输出流外,还可以显式调用flush()方法。 flush()方法的声明为:
– public void flush() throws IOException
package JavaBase.IO;
import java.io.BufferedOutputStream;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class BufferedOutputStreamTest1 {
public static void main(String[]args)throws Exception{
//在当前文件的空间创建一个1.txt的文件
OutputStream outputStream = new FileOutputStream("1.txt");
//用缓冲输出流进行包装
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(outputStream);
//先写到缓冲区,假设缓冲区存放50个字节,等50个字节写满后再写到文件上
bufferedOutputStream.write("htttp://www.google.com".getBytes());
//其实在close之前先调用了flush清空了缓冲区然后再关闭
bufferedOutputStream.close();
//最后一句可以不写
outputStream.close();
}
}
结果是
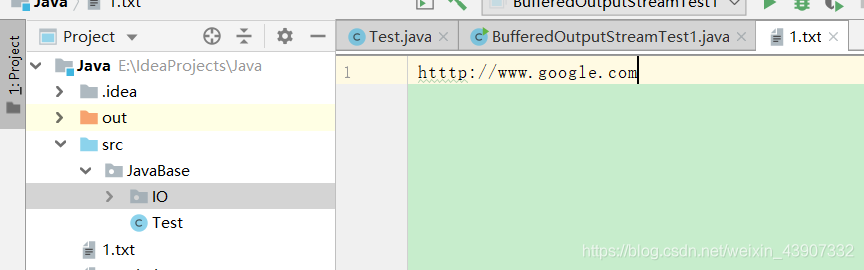
在调用完BufferedOutputStream后一定要flush或者将其close掉,否则缓冲区中的字节不会输出来。
DateInputStream与DateOutputStream
提供了允许从流读写任意对象与基本数据类型功能的方法。字节文件流FileInputStream 和FileOutputStream只能提供纯字节或字节数组的输入/输出,如果要进行基本数据类型如整数和浮点数的输入/输出。则要用到过滤流类的子类二进制数据文件流DataInputStream 和DataOutputStream类。这两个类的对象必须和一个输入类或输出类联系起来,而不能直接用文件名或文件对象建立
流类分层
流类分层:把两种类结合在一起从而构成过滤器流,其方法是使用一个已经存在的流来构造另一个流
(Pattern Of Decorator)
比如: FileInputStream fin = new FileInputStream(“employee.dat”);
DataInputStream din = new DataInputStream(fin);
double s = din.readDouble();
继承自FilterInputStream和FilterOutputStream的类,比如DataInputStream和BufferedInputStream,可以把它们进一个新的过滤流(也即继承自FilterInputStream和FilterOutputStream的类)中以构造要的流。如: DataInputStream din = new DataInputStream(new BufferedInputStream (new FileInputStream(“employee.dat”)));
上面的例子说明了我们需要使用DataInputStream的方法,并且这些方法还要使用缓冲的read方法。就如同上面的例子,可以分层构造流直到得到需要的访问功能为止。实际上这就是装饰模式的最佳实践
使用数据文件流的一般步骤
– (1)建立字节文件流对象;
– (2)基于字节文件流对象建立数据文件流对象;
– (3)用流对象的方法对基本类型的数据进行输入/输出。
DataInputStream类的构造方法如下
– DataInputStream(InputStream in)创建过滤流FilterInputStream对象并为以后的使用保存InputStream参数in。
DataOutputStream类的构造方法如下
– DataOutputStream(OutputStream out)创建输出数据流对象,写数据到指定的OutputStream
package JavaBase.IO;
import java.io.*;
public class DateStream1 {
public static void main(String[] args) throws Exception{
/**
* 过滤流包装节点流,过滤流包装过滤流
* FileOutputStream只能向文件内写数据
* BufferedOutputStream带缓冲的方式写数据
* DataOutputStream可以使用java数据类型的方式写数据
* 综合起来我们可以向文件中以缓冲的方式写入java的基本数据类型
*/
DataOutputStream dataOutputStream = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("data.txt")));
/**
* 输出是乱码因为,我们写入的不止是字符串,
* 还有他们的类型,以int举例,我们写入的是整形12,不是字符串12
*/
byte b = 3;
int i = 12;
char ch = 'a';
float f = 3.3f;
dataOutputStream.writeByte(b);
dataOutputStream.writeInt(i);
dataOutputStream.writeChar(ch);
dataOutputStream.writeFloat(f);
dataOutputStream.close();
DataInputStream dataInputStream = new DataInputStream(new BufferedInputStream(new FileInputStream("data.txt")));
//读的顺序要和写的顺序一致
System.out.println(dataInputStream.readByte());
System.out.println(dataInputStream.readInt());
System.out.println(dataInputStream.readChar());
System.out.println(dataInputStream.readFloat());
}
}
结果是: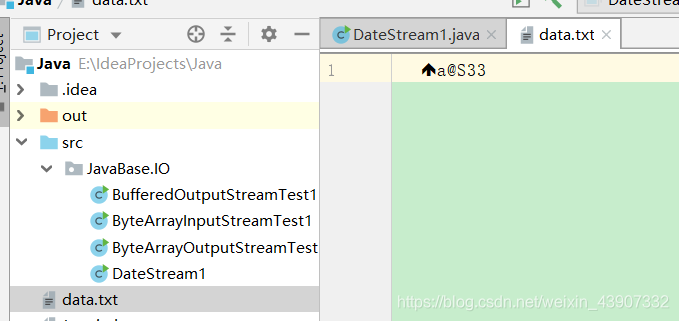
3
12
a
3.3
– 由于DataOutputStream写入的为二进制信息,所以我们无法使用记事本查看内容
实现我们自己的I/O流
-
观察InputStream抽象类, 它所定义的唯一抽象方法便是
– public abstract int read() throws IOException;而其它相关用以读取的方法还有(它们不是抽象的, 也就是说事实上InputStream已提供了实现
– public int read(byte b[]) throws IOException;
public int read(byte b[], int off, int len) throws IOException;
这两个同名异式的版本(方法重载),前者用來从此InputStream中读取最多b.length bytes的 数据储存于b中,并且返回所读取的数目;而后者則用來从此InputStream中读取最多len bytes的数据,並且从b这个byte数组索引值为off之处开始儲存起, 同樣返回所讀取的數目很显然的, InputStream把如何提取数据給读取者的实现部份加以抽离,不同的InputStream实现可能都有不同的实现方式。 -
先让我提一个问题。那为什么InputStream的设计者不將所有的read()方法皆 定义為抽象,而单单只將int read()這一個版本定义為抽象呢?
因为没有意义,父类定义成抽象的子类才能根据自己的需求实现,读文件和读电影的方式肯定不一样。 -
很显然的,這三個版本的read()方法其实是可以互相利用 彼此來实现的。比方說, int read(byte b[])的实现其实就可以写成 return read(b, 0, b.length);
事实上,在Sun所提供的原始程序中,我们也是看到同样的結果。使用第 三個版本read(byte b[], int off, int len)來加以实现;而第三個版本还可以使用第 一個版本的read()來实现自己。我们也不是不可以用第二個版本或是第三個版 本來实现第一個版本,例如
byte b[] = new byte[1];
if( read(b) < 0 ) return –1;
return b[0];
但是,显然InputStream的設計者,选择让int read()成為最後被抽離的對象。而 讓第二版本的read()依赖第三個版本的read(),而讓第三個版本的read()建构在 第一個版本的read()之上。所以,第一個版本的read()就成了此抽象類別唯一的 抽象方法。在某種程度上來說,它是唯一和具体实现會有相关的部份。
动手写一个InputStream
- 我們知道有個名为java.io.ByteArrayInputStream的類別,它允許我們以流 (stream)的方式依序地讀取一個byte array中的內容。假設,我們現在要实现 自己的ByteArrayInputStream,那麼因為它勢必继承Inputstream類別,所以免 不了要实现那唯一的抽象方法: int read()。
- 先來看看构造方法(constructor),假設我們可以在构造它時傳入一個byte array
(java.io.ByteArrayInputStream提供的是更強的功能,在此处我們先只要实现这樣子就好了):
– public MyByteArrayInputStream(byte b[]) - 那麼我們使用一個名为data的成員变量來儲存傳入的byte array。 並且因為串流的性質,我們必須記錄目前已讀取到的位置,所以用int ptr這個 成員变量來加以表示。因此,到目前為止,除了int read()之外,我們已有的实现大概會像是這樣:
public class MyByteArrayInputStream
extends java.io.InputStream
{ protected byte data[];
protected int ptr = 0;
public MyByteArrayInputStream(byte b[])
{
data = b;
}
}
那int read()又該如何实现呢?
public int read()
{
return (ptr < data.length) ? (data[ptr++]) : -1;
}
package JavaBase.IO;
import java.io.IOException;
import java.io.InputStream;
public class MyOwnStream1 {
public static void main(String[] args) throws Exception{
byte[] b = new byte[16];
for (int i = 0; i < b.length; i++) {
b[i] = (byte)i;
}
MyByteArrayInputStream myByteArrayInputStream = new MyByteArrayInputStream(b);
while (true) {
int c = myByteArrayInputStream.read();
if (c < 0) {
break;
}
System.out.print(c + " ");
}
System.out.println();
}
}
class MyByteArrayInputStream extends InputStream{
protected byte[] data;
protected int ptr = 0;
public MyByteArrayInputStream(byte[] b) {
this.data = b;
}
@Override
public int read() throws IOException {
return (ptr < data.length) ? (data[ptr++]) : -1;
}
}
结果是:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
可以看到,不管是直接通过我們所实现的int read()來加以读取,或者是通过InputStream本 身对第二個版本之read()的实现(第二個版本调用第三個版本,而第三個版本 再调用第一個版本),我們都順利地读取到所传入byte array的值
这样子來实现,的确使得MyByteArrayInputStream看起來运作的很顺畅。但是 似乎就是有一些事情不太对劲。比方說,我們在程序中先以byte b[]來构造MyByteArrayInputStream的对象,並由mbais指向該对象。然後依序地以一個 循环读取其中的內容。因為串流的性質,當我們讀取完所有的內容時,我們若 是再调用read()將會得到-1,因為实现中的ptr值已经大于等于data.length的值 了。所以在上述的程序中,我們重新以byte b[]构造了一個新的 MyByteArrayInputStream的对象,並且还是以mbais指向該对象,以供我們下 一次的讀取。
而事实上, InputStream中提供了reset()這個方法,使调用可以重設此 InputStream中的讀取位置。當然,前提是,這個InputStream要能夠被重設讀取位置。而在上述的实现中,我們完全沒有覆写(override)掉所继承自InputStream 中的reset()方法,因而,它所表現出來的行为便是InputSteram之reset()預設的 行为,那么也就是什么都不做。事实上,我們所欠缺的還不只是reset()方法。 以下列出在InputStream的定义中,我們還需要再加以实现的方法。除了抛出 IOException 之外,类 InputStream 的方法 reset 不执行任何操作。
public int available() throws IOException;
public void close() throws IOException;
public synchronized void mark(int
readlimit);
public synchronized void reset() throws
IOException
public boolean markSupported();
所以,我们应该为我们的MyByteArrayInputStream补足这些部份,才可以让 它成为一個完备的InputStream子类
package JavaBase.IO;
import java.io.IOException;
import java.io.InputStream;
public class MyOwnStream2 extends InputStream {
protected byte[] data;
protected int ptr = 0;
protected int mark = 0;
public MyOwnStream2(byte[] data) {
this.data = data;
}
@Override
public int read() throws IOException {
return (ptr < data.length) ? (data[ptr++]) : -1;
}
//还剩多少了字节没有读
@Override
public int available() throws IOException {
return data.length - ptr;
}
@Override
public void close() throws IOException {
ptr = data.length;
}
@Override
public synchronized void mark(int readlimit) {
this.mark = readlimit;
}
@Override
public synchronized void reset() throws IOException {
if (mark < 0 || mark >= data.length) {
throw new IOException("the position is not valid");
}
ptr = mark;
}
//下面的方法返回true说明支持标记mark
@Override
public boolean markSupported() {
return true;
}
@Override
public int read(byte[] b, int off, int len) throws IOException {
if (this.ptr >= data.length || len < 0) {
return -1;
}
if ((this.ptr + len) > data.length) {
len = data.length - this.ptr;
}
if (len == 0) {
return 0;
}
System.arraycopy(data, ptr, b, off, len);
ptr += len;
return len;
}
}
字符流
- 尽管字节流提供了处理任何类型输入/输出操作的足够的功能,它们不能直接操作Unicode字符。既然Java的一个主要目的是支持“只写一次,到处运行” 的哲学,包括直接的字符输入/输出支持是必要的。本节将讨论几个字符输入/输出类。字符流层次结构的顶层是Reader 和Writer 抽象类。我们将从它们开始
- 字符输入/输出类是在java 的1.1版本中新加的。由此,你仍然可以发现遗留下的程序代码在应该使用字符流时却使用了字节流。当遇到这种代码,最好更新它
字符流Reader和Writer类
- 由于Java采用16位的Unicode字符,因此需要基于字符的输入/输出操作。从Java1.1版开始,加入了专门处理字符流的抽象类Reader和Writer,前者用于处理输入,后者用于处理输出。这两个类类似于InputStream和OuputStream,也只是提供一些用于字符流的规定,本身不能用来生成对象.
- Reader和Writer类也有较多的子类,与字节流类似,它们用来创建具体的字符流对象进行I/O操作。字符流的读写等方法与字节流的相应方法都很类似,但读写对象使用的是字符。
- Reader中包含一套字符输入流需要的方法,可以完成最基本的从输入流读入数据的功能。当Java程序需要外设的数据时,可根据数据的不同形式,创建一个适当的Reader子类类型的对象来完成与该外设的连接,然后再调用执行这个流类对象的特定输入方法,如read(),来实现对相应外设的输入操作
- Writer中包含一套字符输出流需要的方法,可以完成最基本的输出数据到输出流的功能。当Java程序需要将数据输出到外设时,可根据数据的不同形式,也要创建一个适当的Writer子类类型的对象来完成与该外设的连接,然后再调用执行这个流类对象的特定输出方法,如write(),来实现对相应外设的输出操作
- Reader是定义Java的流式字符输入模式的抽象类。该类的所有方法在出错情况下都将引发IOException 异常
- Writer 是定义流式字符输出的抽象类。所有该类的方法都返回一个void 值并在出错条件下引发IOException 异常
java.io包中Reader的类层次
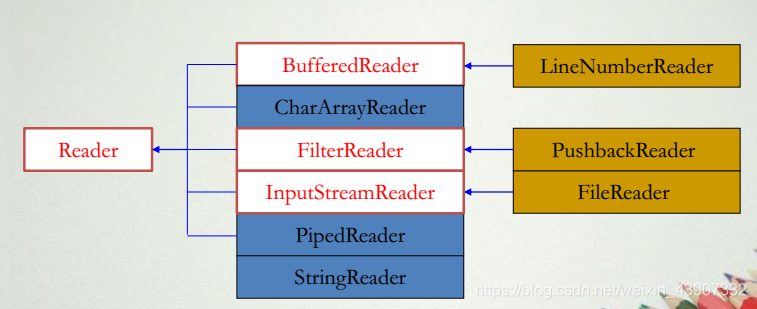
java.io包中Writer的类层次
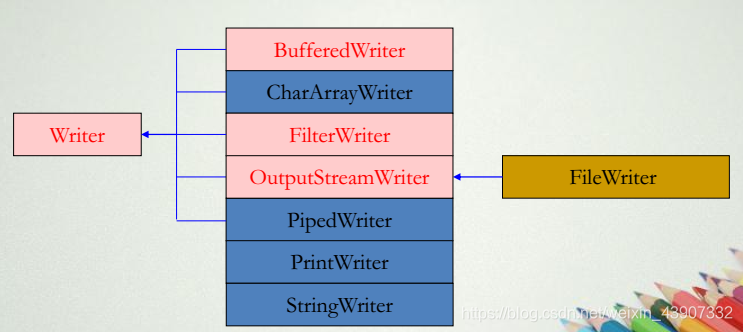
- Java程序语言使用Unicode来表示字符串和字符,Unicode使用两个字节来表示一个字符,即一个字符占16位。
InputStreamReader和OutputStreamWriter类
- 这是java.io包中用于处理字符流的基本类,用来在字节流和字符流之间搭一座“桥”。这里字节流的编码规范与具体的平台有关,可以在构造流对象时指定规范,也可以使用当前平台的缺省规范。
- InputStreamReader和OutputStreamWriter类的主要构造方法如下
– public InputSteamReader(InputSteam in)
– public InputSteamReader(InputSteam in,String enc)
– public OutputStreamWriter(OutputStream out)
– public OutputStreamWriter(OutputStream out,String enc) - 其中in和out分别为输入和输出字节流对象,enc为指定的编码规范(若无此参数,表示使用当前平台的缺省规范,可用getEncoding()方法得到当前字符流所用的编码方式)。读写字符的方法read()、 write(),关闭流的方法close()等与Reader和Writer类的同名方法用法都是类似的。
package JavaBase.IO.stringStream;
import java.io.*;
public class StreamTest {
public static void main(String[] args) throws Exception{
//写入文件
FileOutputStream fileOutputStream = new FileOutputStream("file.txt");
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream);
BufferedWriter bufferedWriter = new BufferedWriter(outputStreamWriter);
bufferedWriter.write("http://www.google.com");
bufferedWriter.write("\n");
bufferedWriter.write("http://www.baidu.com");
bufferedWriter.close();
//读出文件内容
FileInputStream fileInputStream = new FileInputStream("file.txt");
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
//运行一次读一行,回车不算一行所以读2次就行,如果继续读就会返回空
/* System.out.println(bufferedReader.readLine());
System.out.println(bufferedReader.readLine());
System.out.println(bufferedReader.readLine());*/
//用循环重新实现
String s = bufferedReader.readLine();
while (null != s) {
System.out.println(s);
s = bufferedReader.readLine();
}
}
}
结果是

该程序将两行字符串写入文本中,并从中读取出来显示在命令行上
package JavaBase.IO.stringStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class StreamTest2 {
public static void main(String[] args) throws IOException {
//in是输入设备,out是输出设备
InputStreamReader inputStreamReader = new InputStreamReader(System.in);
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String string;
while (null != (string = bufferedReader.readLine())){
System.out.println(string);
}
bufferedReader.close();
}
}
结果是:
hello
hello
hah
hah
jsjdsj soad
jsjdsj soad
该程序将来自标准输入的字符串显示在标准输出上
FileReader
FileReader类创建了一个可以读取文件内容的Reader类。 FileReader继承于
InputStreamReader。 它最常用的构造方法显示如下
– FileReader(String filePath)
– FileReader(File fileObj)
– 每一个都能引发一个FileNotFoundException异常。这里, filePath是一个文件的完整路径,fileObj是描述该文件的File 对象
package JavaBase.IO.stringStream;
import java.io.BufferedReader;
import java.io.FileReader;
public class FileReader1 {
public static void main(String[] args) throws Exception{
FileReader fileReader = new FileReader("E:\\IdeaProjects\\Java\\src\\JavaBase\\IO\\stringStream\\FileReader1.java");
BufferedReader bufferedReader = new BufferedReader(fileReader);
String string;
while (null != (string = bufferedReader.readLine())) {
System.out.println(string);
}
bufferedReader.close();
}
}
结果是:
package JavaBase.IO.stringStream;
import java.io.BufferedReader;
import java.io.FileReader;
public class FileReader1 {
public static void main(String[] args) throws Exception{
FileReader fileReader = new FileReader(“E:\IdeaProjects\Java\src\JavaBase\IO\stringStream\FileReader1.java”);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String string;
while (null != (string = bufferedReader.readLine())) {
System.out.println(string);
}
bufferedReader.close();
}
}
该例子演示了怎样从一个文件逐行读取并把它输出到标准输出流。例子读它自己的源文件。
FIleWriter
- FileWriter 创建一个可以写文件的Writer类。 FileWriter继承于OutputStreamWriter.它最常用的构造方法如下:
– FileWriter(String filePath)
– FileWriter(String filePath, boolean append)
– FileWriter(File fileObj)
– append :如果为 true,则将字节写入文件末尾处,而不是写入文件开始处 - 它们可以引发IOException或SecurityException异常。这里, filePath是文件的完全路径, fileObj是描述该文件的File对象。如果append为true,输出是附加到文件尾的。FileWriter类的创建不依赖于文件存在与否。在创建文件之前, FileWriter将在创建对象时打开它来作为输出。如果你试图打开一个只读文件,将引发一个IOException异常。
package JavaBase.IO.stringStream;
import java.io.FileReader;
import java.io.FileWriter;
public class FileWriter1 {
public static void main(String[] args) throws Exception{
String str = "你好";
char[] buffer = new char[str.length()];
//范围包含开头不包含结尾,所以从0到str.length,目标数组buffer,从第0位开始考
str.getChars(0, str.length(), buffer, 0);
FileWriter fileWriter = new FileWriter("file.txt");
for (int i = 0; i < buffer.length; i++) {
fileWriter.write(buffer[i]);
}
fileWriter.close();
}
}
结果是:
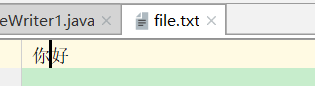
该例子是前面讨论FileOutputStream时用到例子的字符流形式的版本,可以输出汉字。
CharArrayReader
CharArrayReader 是一个把字符数组作为源的输入流的实现。该类有两个构造方法,每一个都需要一个字符数组提供数据源。
– CharArrayReader(char array[ ])
– CharArrayReader(char array[ ], int start, int numChars)
– 这里, array是输入源。第二个构造方法从你的字符数组的子集创建了一个Reader,该子集以start指定的索引开始,长度为numChars。
package JavaBase.IO.stringStream;
import java.io.CharArrayReader;
public class CharArrayReader1 {
public static void main(String[] args) throws Exception{
String tmp = "abcdefg";
char[] chars = new char[tmp.length()];
tmp.getChars(0, tmp.length(), chars, 0);
CharArrayReader input = new CharArrayReader(chars);
int i;
while (-1 != (i = input.read())) {
System.out.println((char)i);
}
}
}
结果是:
a
b
c
d
e
f
g
该例子用到了上述CharArrayReader的两个构造方法
– public void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
• 将字符从此字符串复制到目标字符数组。 要复制的第一个字符在索引 srcBegin 处;要复制的最后一个字符在索引 srcEnd-1 处(因此要复制的字符总数是srcEnd-srcBegin)。要复制到 dst 子数组的字符从索引 dstBegin 处开始,并结束于索引:dstbegin + (srcEnd-srcBegin) - 1
CharArrayWriter
- CharArrayWriter 实现了以数组作为目标的输出流。 CharArrayWriter 有两个构造方法
– CharArrayWriter( )
– CharArrayWriter(int numChars)
– 第一种形式,创建了一个默认长度的缓冲区。
– 第二种形式,缓冲区长度由numChars指定。缓冲区保存在CharArrayWriter的buf 成员中。缓冲区大小在需要的情况下可以自动增长。缓冲区保持的字符数包含在CharArrayWriter的count 成员中。 buf 和count 都是受保护的域(protected)
BufferedWriter
- BufferedReader 通过缓冲输入提高性能。它有两个构造方法
– BufferedReader(Reader inputStream)
– BufferedReader(Reader inputStream, int bufSize)
– 第一种形式创建一个默认缓冲区长度的缓冲字符流。
第二种形式, 缓冲区长度由bufSize传入和字节流的情况相同, 缓冲一个输入字符流同样提供支持可用缓冲区中流内反向移动的基础。 为支持这点, BufferedReader 实现了mark( )和reset( )方法, 并且BufferedReader.markSupported( ) 返回true - BufferedWriter是一个增加了flush( )方法的Writer。 flush( )方法可以用来确保数据缓冲区确实被写到实际的输出流。用BufferedWriter 可以通过减小数据被实际的写到输出流的次数而提高程序的性能。
- BufferedWriter有两个构造方法:
– BufferedWriter(Writer outputStream)
– BufferedWriter(Writer outputStream, int
bufSize)
– 第一种形式创建了使用默认大小缓冲区的缓冲流。第二种形式中,缓冲区大小是由bufSize参数传入的
PushbackReader
• PushbackReader 提供了unread( )方法。该方法返回一个或多个字符到调用的输入流。它有下面的三种形式
– void unread(int ch)
– void unread(char buffer[ ])
– void unread(char buffer[ ], int offset, int
numChars)
– 第一种形式推回ch传入的字符。它是被并发调用的read( )返回的下一个字符。第二种形式返回buffer中的字符。第三种形式推回buffer中从offset开始的numChars个字符。如果在推回缓冲区为满的条件下试图返回一个字符,一个IOException异常将被引发
字符集的编码
- ASCII(American Standard Code for InformationInterchange,美国信息互换标准代码),是基于常用的英文字符的一套电脑编码系统。我们知道英文中经常使用的字符、数字符号被计算机处理时都是以二进制码的形式出现的。这种二进制码的集合就是所谓的ASCII码。每一个ASCII码与一个8位(bit)二进制数对应。其最高位是0,相应的十进制数是0-127。如,数字“0” 的编码用十进制数表示就是48。另有128个扩展的ASCII码,最高位都是1,由一些制表符和其它符号组成。 ASCII是现今最通用的单字节编码系统。
- GB2312: GB2312码是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集-基本集》 。主要用于给每一个中文字符指定相应的数字,也就是进行编码。一个中文字符用两个字节的数字来表示, 为了和ASCII码有所区别,将中文字符每一个字节的最高位置都用1来表示。
- GBK:为了对更多的字符进行编码,国家又发布了新的编码系统GBK(GBK的K是“扩展”的汉语拼音第一个字母)。在新的编码系统里,除了完全兼容GB2312 外,还对繁体中文、一些不常用的汉字和许多符号进行了编码。
- ISO-8859-1:是西方国家所使用的字符编码集,是一种单字节的字符集 ,而英文实际上只用了其中数字小于128的部分。
- Unicode:这是一种通用的字符集,对所有语言的文字进行了统一编码,对每一个字符都用2个字节来表示,对于英文字符采取前面加“0”字节的策略实现等长兼容。如 “a” 的ASCII码为0x61,UNICODE就为0x00, 0x61。 (在internet上传输效率较低)
- UTF-8: Eight-bit UCS TransformationFormat, (UCS, Universal Character Set,通用字符集, UCS 是所有其他字符集标准的一个超集)。一个7位的ASCII码值,对应的UTF码是一个字节。如果字符是0x0000,或在0x0080与0x007f之间,对应的UTF码是两个字节,如果字符在0x0800与0xffff之间,对应的UTF码是三个字节(汉字为3个字节)。
package JavaBase.IO.stringStream;
import java.util.Properties;
public class CharSet {
public static void main(String[] args) {
Properties properties = System.getProperties();
properties.list(System.out);
}
}
该程序返回了在当前系统中所有可用的字符集
我们可以查看到输出该行结果:file.encoding=GBK,这说明在该系统上采用的字符编码方式为GBK
package JavaBase.IO.stringStream;
import java.nio.charset.Charset;
import java.util.*;
public class CharSetTest {
public static void main(String[] args) {
//获取当前程序字符集,Charset字符集,availableCharsets方法表示的是存在的字符集
//返回SortMap,继承了Map,带排序,key是String,value是Charset
SortedMap<String, Charset> map = Charset.availableCharsets();
Set set = map.entrySet();
for (Iterator iterator = set.iterator(); iterator.hasNext(); ) {
Map.Entry entry = (Map.Entry)iterator.next();
System.out.println(entry.getKey());
}
}
}
查看当前程序字符集
RandomAccessFile(随机访问文件类)
- RandomAccessFile包装了一个随机访问的文件。它不是派生于InputStream和OutputStream,而是实现定义了基本输入/输出方法的DataInput和DataOutput接口。它支持定位请求——也就是说,可以在文件内部放置文件指针。它有两个构造方法:
RandomAccessFile(File fileObj, String access) throws FileNotFoundException
RandomAccessFile(String filename, String access) throws FileNotFoundException
第一种形式, fileObj指定了作为File 对象打开的文件的名称。
第二种形式,文件名是由filename参数传入的。两种情况下, access 都决定允许访问何种文件类型。如果是“r”,那么文件可读不可写,如果是“rw”,文件以读写模式打开
new RandomAccessFile(“test.txt", “r”);
new RandomAccessFile(“test.txt", “rw”); - RandomAccessFile类同时实现了DataInput和DataOutput接口,提供了对文件随机存取的功能,利用这个类可以在文件的任何位置读取或写入数据。RandomAccessFile类提供了一个文件指针,用来标志要进行读写操作的下一数据的位置。
- 常用方法:
– public long getFilePointer()
– 返回到此文件开头的偏移量(以字节为单位),在该位置发生下一个读取或写入操作
– public void seek(long pos)
– 设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作。偏移量的设置可能会超出文件末尾。偏移量的设置超出文件末尾不会改变文件的长度。 只有在偏移量的设置超出文件末尾的情况下对文件进行写入才会更改其长度 - 常用方法:
– public long length()
– 返回此文件的长度
– public int skipBytes(int n)
– 尝试跳过输入的 n 个字节以丢弃跳过的字节
package JavaBase.IO.stringStream;
import java.io.RandomAccessFile;
public class RandomAccessFile1 {
public static void main(String[] args) throws Exception{
Person person = new Person(1, "hello", 5.42);
RandomAccessFile randomAccessFile = new RandomAccessFile("text.txt", "rw");
person.write(randomAccessFile);
//让读的位置重回文件开头
randomAccessFile.seek(0);
Person person1 = new Person();
person1.read(randomAccessFile);
System.out.println(person1.getId() + "," + person1.getName() + "," + person1.getHeight());
}
}
class Person{
private int id;
private String name;
private double height;
public double getHeight() {
return height;
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public Person(){
}
public Person(int id, String name, double height) {
this.id = id;
this.name = name;
this.height = height;
}
public void write(RandomAccessFile randomAccessFile) throws Exception{
randomAccessFile.writeInt(this.id);
randomAccessFile.writeUTF(this.name);
randomAccessFile.writeDouble(this.height);
}
public void read(RandomAccessFile randomAccessFile) throws Exception{
this.id = randomAccessFile.readInt();
this.name = randomAccessFile.readUTF();
this.height = randomAccessFile.readDouble();
}
}
结果是:
1,hello,5.42
序列化
- 将对象转换为字节流保存起来,并在以后还原这个对象,这种机制叫做对象序列化。
- 将一个对象保存到永久存储设备上称为持久化。
- 一个对象要想能够实现序列化,必须实现Serializable接口或Externalizable接口。将一个对象保存到永久存储设备上称为持久化。一个对象要想能够实现序列化,必须实现Serializable接口或Externalizable接口。
- == 一个类若想被序列化,则需要实现 java.io.Serializable 接口,该接口中没有定义任何方法,是一个标识性接口(Marker Interface),当一个类实现了该接口,就表示这个类的对象是可以序列化的。==
- 序列化(serialization)是把一个对象的状态写入一个字节流的过程。当你想要把你的程序状态存到一个固定的存储区域例如文件时,它是很管用的。稍后一点时间,你就可以运用序列化过程存储这些对象。
- 假设一个被序列化的对象引用了其他对象,同样,其他对象又引用了更多的对象。这一系列的对象
和它们的关系形成了一个顺序图表。在这个对象图表中也有循环引用。也就是说,对象X可以含有一个对象Y的引用,对象Y同样可以包含一个对象X的引用。对象同样可以包含它们自己的引用。对象序列化和反序列化的工具被设计出来并在这一假定条件下运行良好。如果你试图序列化一个对象图表中顶层的对象,所有的其他的引用对象都被循环的定位和序列化。同样,在反序列化过程中,所有的这些对象以及它们的引用都被正确的恢复 - 当一个对象被序列化时,只保存对象的非静态成员变量,不能保存任何的成员方法和静态的成员变量。如果一个对象的成员变量是一个对象,那么这个对象的数据成员也会被保存。如果一个可序列化的对象包含对某个不可序列化的对象的引用,那么整个序列化操作将会失败,并且会抛出一个NotSerializableException。我们可以将这个引用标记为transient,那么对象仍然可以序列化。
- 在序列化时, static 变量是无法序列化的;如果 A 包含了对 B 的引用,那么在序列化A 的时候也会将 B 一并地序列化;如果此时 A 可以序列化, B 无法序列化,那么当序列化 A 的时候就会发生异常,这时就需要将对 B 的引用设为 transient,该关键字表示变量不会被序列化。
Serializable接口
- 只有一个实现Serializable接口的对象可以被序列化工具存储和恢复。 Serializable接口没有定义任何成员。它只用来表示一个类可以被序列化。如果一个类可以序列化,它的所有子类都可以序列化。
- 声明成transient的变量不被序列化工具存储。同样, static变量也不被存储
ObjectOutput接口
- ObjectOutput 继承DataOutput接口并且支持对象序列化。特别注意writeObject( )方法,它被称为序列化一个对象。所有这些方法在出错情况下引发IOException 异常
ObjectOutputStream类
- ObjectOutputStream类继承OutputStream 类和实现ObjectOutput 接口。它负责向流写入对象。该类的构造方法如下:
– ObjectOutputStream(OutputStream outStream) throws IOException
– 参数outStream 是序列化的对象将要写入的输出流
ObjectInput
- ObjectInput 接口继承DataInput接口。它支持对象序列化。特别注意 readObject( )方法,它叫反序列化对象。所有这些方法在出错情况下引发IOException 异常
ObjectInputStream
- ObjectInputStream 继承InputStream 类并实现ObjectInput 接口。ObjectInputStream 负责从流中读取对象。
该类的构造方法如下:
– ObjectInputStream(InputStream inStream) throws IOException,StreamCorruptedException
– 参数inStream 是序列化对象将被读取的输入流。
package JavaBase.IO.Serializable;
import java.io.FileOutputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class SerializableTest1 {
public static void main(String[] args) throws Exception{
Person p1 = new Person(20, "zhangsan", 4.55);
Person p2 = new Person(50, "lisi", 4.67);
Person p3 = new Person(10, "wangwu", 17.78);
FileOutputStream fileOutputStream = new FileOutputStream("Person.txt");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(p1);
objectOutputStream.writeObject(p2);
objectOutputStream.writeObject(p3);
objectOutputStream.close();
}
}
//要序列化一个类必须实现Serializable接口,只是一个表示,里面没有方法
class Person implements Serializable {
int age;
String name;
double height;
public Person(int age, String name, double height) {
this.age = age;
this.name = name;
this.height = height;
}
}
结果是:
�� sr JavaBase.IO.Serializable.Person���Ѿ*� I ageD heightL namet Ljava/lang/String;xp @333333t zhangsansq ~ 2@�z�G�t lisisq ~
@1Ǯz�Ht wangwu
当我们做了如下改动后
transient String name;
static double height;
结果是:
�� sr JavaBase.IO.Serializable.Personر��I~:� I agexp sq ~ 2sq ~
反序列化
FileInputStream fileInputStream = new FileInputStream("Person.txt");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
Person person = null;
for (int i = 0; i < 3; i++) {
person = (Person)objectInputStream.readObject();
System.out.println(person.age + "," + person.name + "," + person.height);
}
objectInputStream.close();
结果是:
20,zhangsan,4.55
50,lisi,4.67
10,wangwu,17.78
反序列化时不会调用对象的任何构造方法,仅仅根据所保存的对象状态信息,在内存中重新构建对象
在序列化和反序列化进程中需要特殊处理的 Serializable 类应该实现以下方法:
private void writeObject(java.io.ObjectOutputStream stream) throws IOException;
private void readObject(java.io.ObjectInputStream stream) throws IOException, ClassNotFoundException;
这两个方法不属于任何一个类和任何一个接口,是非常特殊的方法.
Classes that require special handling during the serialization and deserialization process must implement special methods with these exact signatures:
(在序列化和反序列化过程中需要特殊处理的类必须使用这些精确签名实现特殊方法:)
private void writeObject(java.io.ObjectOutputStream out) throws IOException
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
private void readObjectNoData() throws ObjectStreamException;
package JavaBase.IO.Serializable;
import java.io.*;
public class SerializableTest2 {
public static void main(String[] args) throws Exception{
Person2 p1 = new Person2(20, "zhangsan", 4.55);
Person2 p2 = new Person2(50, "lisi", 4.67);
Person2 p3 = new Person2(10, "wangwu", 17.78);
//序列化
FileOutputStream fileOutputStream = new FileOutputStream("Person.txt");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);
objectOutputStream.writeObject(p1);
objectOutputStream.writeObject(p2);
objectOutputStream.writeObject(p3);
objectOutputStream.close();
//反序列化
FileInputStream fileInputStream = new FileInputStream("Person.txt");
ObjectInputStream objectInputStream = new ObjectInputStream(fileInputStream);
Person2 person = null;
for (int i = 0; i < 3; i++) {
person = (Person2)objectInputStream.readObject();
System.out.println(person.age + "," + person.name + "," + person.height);
}
objectInputStream.close();
}
}
//要序列化一个类必须实现Serializable接口,只是一个表示,里面没有方法
class Person2 implements Serializable {
int age;
/*transient */String name;
/*static */double height;
public Person2(int age, String name, double height) {
this.age = age;
this.name = name;
this.height = height;
}
//
private void writeObject(java.io.ObjectOutputStream outputStream) throws IOException{
System.out.println("write object");
}
private void readObject(java.io.ObjectInputStream inputStream) throws IOException, ClassNotFoundException{
System.out.println("read object");
}
}
结果是:
write object
write object
write object
read object
0,null,0.0
read object
0,null,0.0
read object
0,null,0.0
我们继续改写writeObject和readObject方法
private void writeObject(java.io.ObjectOutputStream outputStream) throws IOException{
outputStream.writeInt(age);
outputStream.writeUTF(name);
outputStream.writeDouble(height);
System.out.println("write object");
}
private void readObject(java.io.ObjectInputStream inputStream) throws IOException, ClassNotFoundException{
age = inputStream.readInt();
name = inputStream.readUTF();
height = inputStream.readDouble();
System.out.println("read object");
}
结果是:
write object
write object
write object
read object
20,zhangsan,4.55
read object
50,lisi,4.67
read object
10,wangwu,17.78
当我们在一个待序列化/反序列化的类中实现了以上两个 private 方法(方法声明要与上面的保持完全的一致),那么就允许我们以更加底层、更加细粒度的方式控制序列化/反序列化的过程。

















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









