






《OpenShift / RHEL / DevSecOps 汇总目录》
已在 InstructLab 0.24.1 验证
Granite 和 InstructLab 是什么?
Granite 是 IBM 推出的大语言模型,旨在为企业和开发者提供强大的自然语言处理能力。Granite 模型专注于生成高质量的文本、支持多语言处理,并能够适应诸如内容生成、问答系统、代码生成等多种应用场景。
InstructLab 是 IBM 推出的一个开源工具和框架,旨在帮助开发者和研究人员更高效地训练、微调和优化大语言模型。它是 IBM 在生成式 AI 和自然语言处理领域的最新成果之一,专注于通过指令(Instruction)驱动的方式提升模型的能力。
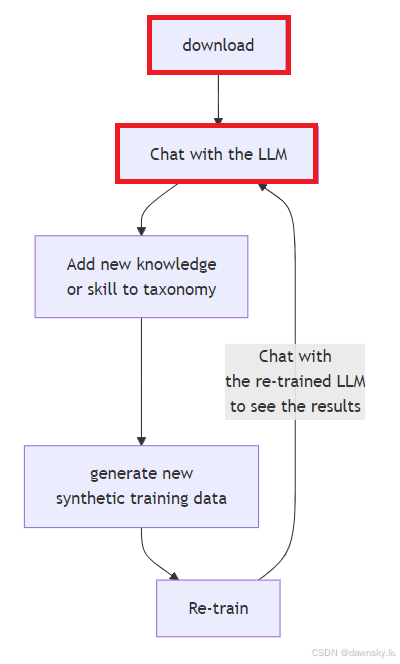
使用 InstructLab 运行和训练 Granite 模型的迭代过程如下图,本文实现的是红色部分的操作。
安装 InstructLab
注意:本文使用的是社区版 InstructLab。虽然 RHEL AI 中也包含 InstructLab 但其安装方式和使用的模型有别于社区版。
环境说明:
- 运行环境:RHEL 9.4
- 登录用户:lab-user
- 硬件:
- GPU:可无 ,但在运行、生成训练数据、训练模型时会比较慢
- 内存:64G
- 先安装必要的依赖环境,再进入 Python 的 venv 环境。
$ sudo dnf install gcc gcc-c++ make git python3.11 python3.11-devel
$ python3.11 -m venv --upgrade-deps venv
$ source venv/bin/activate
- 安装 instructlab。本文已验证过 0.24.1 和 0.23.2 两个版本。
(venv) [lab-user@rhel9 ~]$ pip install instructlab[mps]==0.24.1
说明:还可通过以下命令升级 ilab。
(venv) [lab-user@rhel9 ~]$ pip install instructlab --upgrade 'instructlab[mps]==0.24.1'
- 查看 ilab 系统运行环境信息。
(venv) [lab-user@rhel9 ~]$ ilab system info
Platform:
sys.version: 3.11.7 (main, Aug 23 2024, 00:00:00) [GCC 11.4.1 20231218 (Red Hat 11.4.1-3)]
sys.platform: linux
os.name: posix
platform.release: 5.14.0-427.33.1.el9_4.x86_64
platform.machine: x86_64
platform.node: bastion.mhf94.internal
platform.python_version: 3.11.7
os-release.ID: rhel
os-release.VERSION_ID: 9.4
os-release.PRETTY_NAME: Red Hat Enterprise Linux 9.4 (Plow)
memory.total: 60.21 GB
memory.available: 57.90 GB
memory.used: 1.60 GB
InstructLab:
instructlab.version: 0.24.0
instructlab-dolomite.version: 0.2.0
instructlab-eval.version: 0.5.1
instructlab-quantize.version: 0.1.0
instructlab-schema.version: 0.4.2
instructlab-sdg.version: 0.7.1
instructlab-training.version: 0.7.0
Torch:
torch.version: 2.5.1+cu124
torch.backends.cpu.capability: AVX2
torch.version.cuda: 12.4
torch.version.hip: None
torch.cuda.available: True
torch.backends.cuda.is_built: True
torch.backends.mps.is_built: False
torch.backends.mps.is_available: False
torch.cuda.bf16: True
torch.cuda.current.device: 0
torch.cuda.0.name: NVIDIA L4
torch.cuda.0.free: 21.9 GB
torch.cuda.0.total: 22.0 GB
torch.cuda.0.capability: 8.9 (see https://developer.nvidia.com/cuda-gpus#compute)
llama_cpp_python:
llama_cpp_python.version: 0.3.6
llama_cpp_python.supports_gpu_offload: False
- 安装后初始化 instructlab。注意:选择不同的硬件生成的 profile 中包含的参数有所差异,本演示先选择 NO SYSTEM PROFILE。
(venv) [lab-user@rhel9 ~]$ ilab config init
----------------------------------------------------
Welcome to the InstructLab CLI
This guide will help you to setup your environment
----------------------------------------------------
Please provide the following values to initiate the environment [press 'Enter' for default options when prompted]
Path to taxonomy repo [/home/lab-user/.local/share/instructlab/taxonomy]:
`/home/lab-user/.local/share/instructlab/taxonomy` seems to not exist or is empty.
Should I clone https://github.com/instructlab/taxonomy.git for you? [Y/n]:
Cloning https://github.com/instructlab/taxonomy.git...
Path to your model [/home/lab-user/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf]:
Generating config file:
/home/lab-user/.config/instructlab/config.yaml
WARNING 2025-02-13 01:00:28,785 instructlab.config.init:125: ilab is only officially supported on Linux and MacOS with M-Series Chips
Please choose a system profile.
Profiles set hardware-specific defaults for all commands and sections of the configuration.
First, please select the hardware vendor your system falls into
[0] NO SYSTEM PROFILE
[1] AMD
[2] APPLE
[3] INTEL
[4] NVIDIA
Enter the number of your choice [0]:
No profile selected - ilab will use generic code defaults - these may not be optimized for your system.
--------------------------------------------
Initialization completed successfully!
You're ready to start using `ilab`. Enjoy!
--------------------------------------------
说明:以下是初始化后的默认目录。
| 默认文件或目录 | 说明 |
|---|---|
| ~/.cache/instructlab/models/ | 下载的模型 |
| ~/.cache/instructlab/datasets/ | 生成的合成数据 |
| ~/.cache/instructlab/taxonomy/ | 用来训练模型的技能或知识数据 |
| ~/.cache/instructlab/checkpoints/ | 训练结果 |
| ~/.config/instructlab/config.yaml | 配置文件 |
- 可以查看和修改 instructlab 的配置,包括 serve、chat、evaluate、generate、rag、train 等子命令用到的缺省参数。
(venv) [lab-user@rhel9 ~]$ ilab config show
(venv) [lab-user@rhel9 ~]$ ilab config edit
下载 Granite 模型
为了运行模型,可以直接下载模型文件,也可以下载模型的镜像。
下载模型文件
- 下载默认需要的模型文件。
(venv) [lab-user@rhel9 ~]$ ilab model download
INFO 2025-02-20 09:05:53,665 instructlab.model.download:77: Downloading model from Hugging Face:
Model: instructlab/granite-7b-lab-GGUF@main
Destination: /home/lab-user/.cache/instructlab/models
Downloading 'granite-7b-lab-Q4_K_M.gguf' to '/home/lab-user/.cache/instructlab/models/.cache/huggingface/download/cBHY6fAjnFSRbyeHvtiPqRVG_SE=.6adeaad8c048b35ea54562c55e454cc32c63118a32c7b8152cf706b290611487.incomplete'
INFO 2025-02-20 09:05:53,728 huggingface_hub.file_download:1540: Downloading 'granite-7b-lab-Q4_K_M.gguf' to '/home/lab-user/.cache/instructlab/models/.cache/huggingface/download/cBHY6fAjnFSRbyeHvtiPqRVG_SE=.6adeaad8c048b35ea54562c55e454cc32c63118a32c7b8152cf706b290611487.incomplete'
granite-7b-lab-Q4_K_M.gguf: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████▉| 4.08G/4.08G [00:04<00:00, 817MB/s]
Download complete. Moving file to /home/lab-user/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf
INFO 2025-02-20 09:05:58,774 huggingface_hub.file_download:1556: Download complete. Moving file to /home/lab-user/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf
INFO 2025-02-20 09:05:58,776 instructlab.model.download:288:
ᕦ(òᴗóˇ)ᕤ instructlab/granite-7b-lab-GGUF model download completed successfully! ᕦ(òᴗóˇ)ᕤ
。。。
。。。
INFO 2025-02-20 09:06:08,031 instructlab.model.download:302: Available models (`ilab model list`):
+--------------------------------------------+---------------------+----------+-------------------------------------------------------------------------------+
| Model Name | Last Modified | Size | Absolute path |
+--------------------------------------------+---------------------+----------+-------------------------------------------------------------------------------+
| granite-7b-lab-Q4_K_M.gguf | 2025-02-20 09:05:58 | 3.8 GB | /home/lab-user/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf |
| merlinite-7b-lab-Q4_K_M.gguf | 2025-02-20 09:06:02 | 4.1 GB | /home/lab-user/.cache/instructlab/models/merlinite-7b-lab-Q4_K_M.gguf |
| mistral-7b-instruct-v0.2.Q4_K_M.gguf | 2025-02-20 09:06:05 | 4.1 GB | /home/lab-user/.cache/instructlab/models/mistral-7b-instruct-v0.2.Q4_K_M.gguf |
| ibm-granite/granite-embedding-125m-english | 2025-02-20 09:06:08 | 479.2 MB | /home/lab-user/.cache/instructlab/models/ibm-granite |
+--------------------------------------------+---------------------+----------+-------------------------------------------------------------------------------+
说明:在下载的模型中前三个是 GGUF 类型模型,而 granite-embedding-125m-english 是为运行 RAG 而用的 Safetensor 类模型。另外训练使用的 Safetensor 类模型会在后文下载。
| LLM | Format | Description | Purpose | Access |
|---|---|---|---|---|
| Granite-7b-lab-GGUF | GGUF | Quantized version of the granite-7b-lab model | Default chat model | Downloads with default ilab model download command |
| Merlinite-7b-lab-GGUF | GGUF | Quantized version of the Merlinite-7b-lab model | Teacher model with SDG simple pipeline | Downloads with default ilab model download command |
| Mistral-7B-Instruct-v0.2-GGUF | GGUF | Quantized version of the Mistral-7B-Instruct-v0.2 model | Teacher model for SDG full pipeline | Downloads with default ilab model download command |
| ibm-granite/granite-embedding-125m-english | Safetensor | Model for running RAG | for running RAG | Downloads with default ilab model download command |
| Granite-7b-lab | Safetensor | Lab fine-tuned Granite model | Default student model | Manual download |
| Merlinite-7b-lab | Safetensor | Lab fine-tuned Merlinite-7b model | Student modell | Manual download |
| Prometheus-8x7b-v2.0 | Safetensor | Evaluation model | Judge model | Manual download |
下载模型镜像
注意:granite-7b-redhat-lab 模型需要 GPU 才能运行。
- 从 RedHat 下载模型镜像。注意:镜像下载完会将解析出的模型存放到由 Absolute path 指定的目录中。
(venv) [lab-user@rhel9 ~]$ sudo yum install podman skopeo
(venv) [lab-user@rhel9 ~]$ podman login registry.redhat.io
(venv) [lab-user@rhel9 ~]$ ilab model download --repository docker://registry.redhat.io/rhelai1/granite-7b-redhat-lab --release latest
Downloading model from OCI registry:
Model: docker://registry.redhat.io/rhelai1/granite-7b-redhat-lab@latest
Destination: /home/lab-user/.cache/instructlab/models
Copying blob cfc7749b96f6 done |
Copying blob 2b58ec4b44df done |
Copying blob eaa62cf55e39 done |
Copying blob 95567d271e42 done |
Copying blob be86b2904489 done |
Copying blob 4dc608e8fa2c done |
Copying blob 9b8ae2592b2f done |
Copying blob 0e06d282498e done |
Copying blob 9cf0240b4192 done |
Copying blob c276dd82d13b done |
Copying config 44136fa355 done |
Writing manifest to image destination
INFO 2025-02-13 01:13:15,394 instructlab.model.download:288:
ᕦ(òᴗóˇ)ᕤ docker://registry.redhat.io/rhelai1/granite-7b-redhat-lab model download completed successfully! ᕦ(òᴗóˇ)ᕤ
INFO 2025-02-13 01:13:15,394 instructlab.model.download:302: Available models (`ilab model list`):
+------------------------------+---------------------+---------+----------------------------------------------------------------+
| Model Name | Last Modified | Size | Absolute path |
+------------------------------+---------------------+---------+----------------------------------------------------------------+
| models/granite-7b-redhat-lab | 2025-02-13 01:13:15 | 12.6 GB | /home/lab-user/.cache/instructlab/models/granite-7b-redhat-lab |
+------------------------------+---------------------+---------+----------------------------------------------------------------+
运行 Granite 模型
- 执行命令,运行默认的 granite-7b-lab-Q4_K_M 模型。
(venv) [lab-user@rhel9 ~]$ ilab model serve
INFO 2025-02-12 08:52:32,733 instructlab.model.serve_backend:54: Setting backend_type in the serve config to llama-cpp
INFO 2025-02-12 08:52:32,764 instructlab.model.serve_backend:60: Using model '/home/lab-user/.cache/instructlab/models/granite-7b-lab-Q4_K_M.gguf' with -1 gpu-layers and 4096 max context size.
llama_new_context_with_model: n_ctx_pre_seq (4096) > n_ctx_train (2048) -- possible training context overflow
INFO 2025-02-12 08:52:45,044 instructlab.model.backends.llama_cpp:306: Replacing chat template:
{% set eos_token = "<|endoftext|>" %}
{% set bos_token = "<|begginingoftext|>" %}
{% for message in messages %}{% if message['role'] == 'pretraining' %}{{'<|pretrain|>' + message['content'] + '<|endoftext|>' + '<|/pretrain|>' }}{% elif message['role'] == 'system' %}{{'<|system|>'+ '
' + message['content'] + '
'}}{% elif message['role'] == 'user' %}{{'<|user|>' + '
' + message['content'] + '
'}}{% elif message['role'] == 'assistant' %}{{'<|assistant|>' + '
' + message['content'] + '<|endoftext|>' + ('' if loop.last else '
')}}{% endif %}{% if loop.last and add_generation_prompt %}{{ '<|assistant|>' + '
' }}{% endif %}{% endfor %}
INFO 2025-02-12 08:52:45,060 instructlab.model.backends.llama_cpp:233: Starting server process, press CTRL+C to shutdown server...
INFO 2025-02-12 08:52:45,060 instructlab.model.backends.llama_cpp:234: After application startup complete see http://127.0.0.1:8000/docs for API.
对话 Granite 模型
- 在一个新窗口启动与默认的 granite-7b-lab-Q4_K_M 模型进行对话。
[lab-user@rhel9 ~]$ source venv/bin/activate
(venv) [lab-user@rhel9 ~]$ ilab model chat
╭──────────────────────────────────────────────────────────── system ────────────────────────────────────────────────────────────╮
│ Welcome to InstructLab Chat w/ GRANITE-7B-LAB-Q4_K_M.GGUF (type /h for help) │
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
>>>
- 在提示符后输入对话即可。
>>> What is openshift in 20 words or less? [S][default]
╭─────────────────────────────────────────────────────────── granite-7b-lab-Q4_K_M.gguf ────────────────────────────────────────────────────────────╮
│ OpenShift: A container application platform for efficient, scalable, and secure deployment of applications in a hybrid cloud environment. │
╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── elapsed 2.699 seconds ─╯
参考
https://developers.redhat.com/learning/learn:download-serve-and-interact-llms-rhel-ai/resource/learn:rhel:download-serve-and-interact-llms-rhel-ai-prerequisites-and-step-step-guide
https://developers.redhat.com/blog/2024/06/12/getting-started-instructlab-generative-ai-model-tuning
https://github.com/instructlab/instructlab?tab=readme-ov-file
https://github.com/instructlab/instructlab/blob/main/docs/user/instructlab_models.md
https://redhat-scholars.github.io/instructlab-tutorial/instructlab-tutorial/index.html
https://www.redhat.com/en/blog/instructlab-tutorial-installing-and-fine-tuning-your-first-ai-model-part-1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









