






《OpenShift / RHEL / DevSecOps 汇总目录》
HA的相关概念
高可用性的不同实现模式
- 双活(主动 / 主动): 发往故障节点的流量要么被转至现有节点,要么在其余节点间实现负载均衡。这通常只有在各节点采用同质软件配置时才有可能实现。
- 主备(主动 / 被动):为每个节点提供一个完全冗余的实例,只有当与之关联的主节点发生故障时,该冗余实例才会上线。[2] 这种配置通常需要最多的额外硬件。
- N + 1: 提供一个额外的节点,当有节点发生故障时,该节点上线接管故障节点的角色。如果每个主节点采用异构软件配置,那么这个额外节点必须具备普遍承担其负责的主节点的任何角色的能力。这通常指的是同时运行多个服务的集群;在单服务的情况下,这种模式就退化为主动 / 被动模式。
- N + M:在单个集群管理众多服务的情况下,仅设置一个专用的故障转移节点可能无法提供足够的冗余。在这种情况下,会配备多个(M 个)备用服务器并使其处于可用状态。备用服务器的数量需要在成本和可靠性要求之间进行权衡。
- N 对 1: 允许故障转移备用节点暂时成为活动节点,直至原始节点能够恢复或重新上线,到那时,为了恢复高可用性,服务或实例必须回切到原始节点。
- N 对 N: 是主动 / 主动和 N + M 集群的组合,N 对 N 集群会将故障节点的服务、实例或连接在其余活动节点之间重新分配,这样就(如同主动 / 主动模式那样)无需设置 “备用” 节点,但要求所有活动节点具备额外的容量。
集群类型
高可用集群
高可用性集群有时也被称为故障转移集群。高可用集群可消除单点故障,并在一个节点无法运行时将服务从一个集群节点转移到另一个节点,而集群的客户端感知不到集群的节点故障。如果高可用集群的服务会读写数据(通过读写挂载文件系统),当集群从一个节点转移另一个节点接管服务控制权时,高可用集群必须保持数据的完整性。
- Failover:在高可用集群中,当主节点出现故障后,集群将使用备节点响应用户请求,这个过程称为故障转移。
- Failback:在高可用集群中,当主节点出现故障后再次恢复正常,集群将响应用户请求的节点从备节点切回到主节点,这个过程称为故障恢复。
负载均衡集群
负载均衡集群可将服务请求分派给多个集群节点,以平衡集群节点之间的请求负载。因为可以根据负载需求来匹配节点数量,因此负载均衡集群提供了经济高效的可扩展性。如果负载均衡集群中的一个节点无法运行,负载均衡软件会检测到故障并将请求重定向到其他集群节点,而集群的客户端感知不到集群的节点故障。
高性能集群
高性能集群也被称为计算集群或网格计算。高性能集群使用集群节点执行并发计算。高性能集群允许应用程序并行工作,从而提高应用程序的性能。
高可用集群特性
脑裂和仲裁
当集群出现无法相互通信的部分时,每部分都会以为集群的其他部分出现了故障。此时集群就出现了两个独立运行的部分,于是就产生了脑裂问题。脑裂可能会导致两个独立的部分都在运行,从而出现数据被破坏的情况。
集群通常可以使用仲裁(quorum) 的方法防止脑裂(split-brain)问题出现。当半数以上的集群节点在线时,集群就达到了法定的仲裁数,集群还可以继续运行在多数部分里。例如对于一个有 6 个节点集群,在至少有 4 个集群节点正常工作时就满足了仲裁量。如果集群没有达到法定的仲裁数,通常集群会停止所有资源运行。
隔离 Fencing
如果集群和某个节点的通信出现失败,不响应的节点可能仍然在访问数据。确定数据安全的唯一方法是使用隔离保护节点。为了确保数据安全和一致性,集群的其他节点必须能限制访问那些被故障节点访问的资源。由于故障节点已无法正常访问,因此必须提供一种外部方法来实现,该方法为称为隔离(fencing)。隔离设备是一个外部设备,集群使用它来限制错误节点对共享资源的访问,或对集群的节点执行重启。如果没有配置隔离,集群就无法知道出问题的节点使用的资源是否已被释放,这可能导致数据崩溃、数据丢失,无法保证数据完整性。
隔离代理(或设备)是允许群集关闭/打开电源并检查节点电源状态的脚本或程序,可以包括以下类型的隔离代理:
- 可物理移除电源(IPMI、APC 围栏设备)
- 可关闭虚拟节点(KVM、VMWare)
- 可关闭对存储的访问(SCSI 围栏)
- 可使用硬件 watchdog (SBD:Storage-Based Death 围栏)停止节点
RHEL HA Add-on 构成
RHEL High Availability Add-On 是由 Pacemaker、Coresync 等开源组件构成,他们提供以下整体的集群运行和管理功能:
- 集群基础结构 - 提供集群管理功能:配置文件管理、成员资格管理、锁管理和保护。
- 高可用性服务管理 - 提供当一个节点不可操作时,服务从一个集群节点切换到另外一个节点的功能。
- 集群管理工具 - 提供用于集群基础结构组件、高可用性和服务管理组件的配置和管理工具。
构成 RHEL HA add-on 的组件和架构见下图:
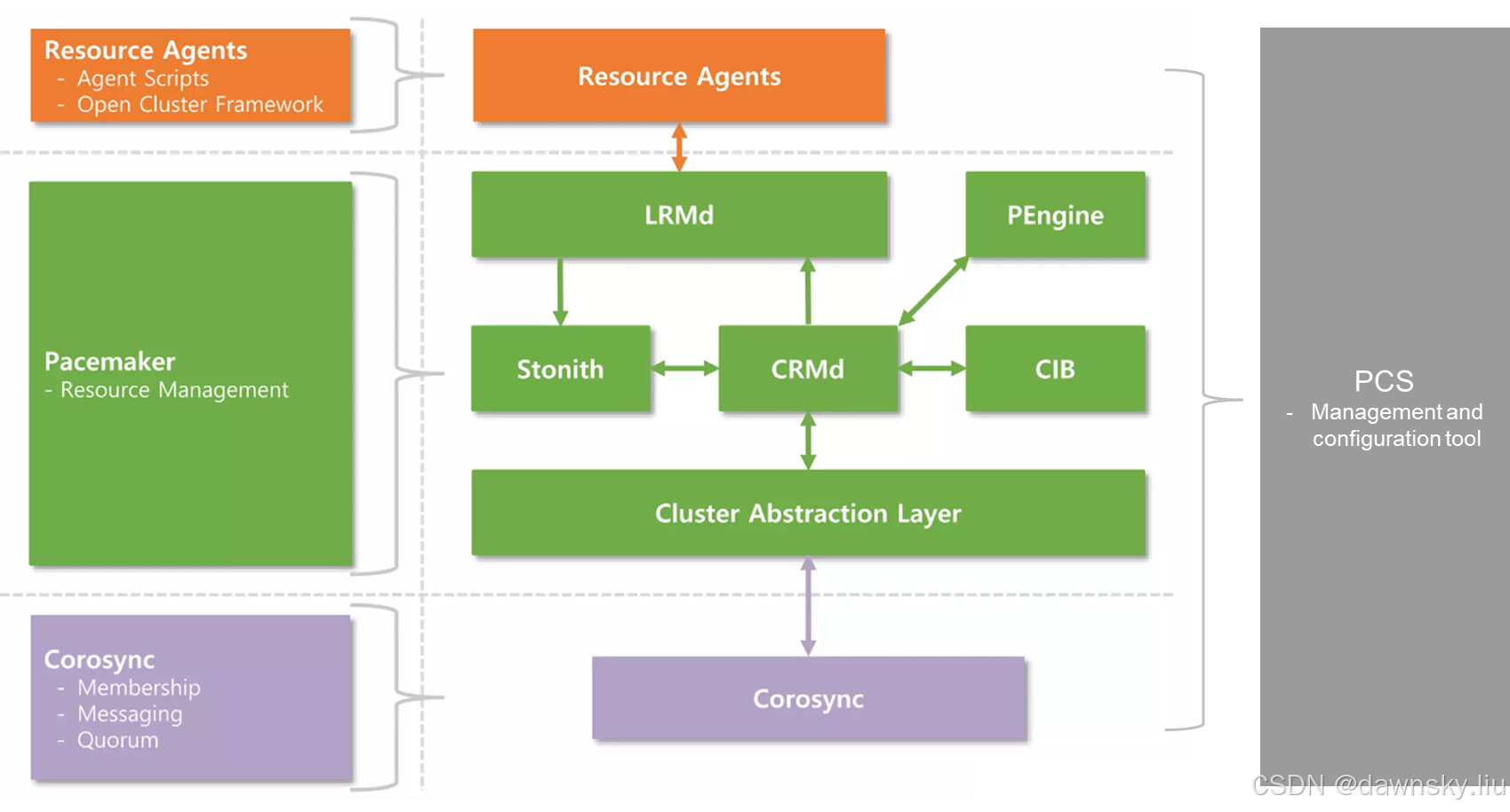
- 集群信息库 Cluster Information Base(CIB):CIB 使用 XML 来表示群集的配置和群集中所有资源的当前状态。Pacemaker 向所有集群节点分发和同步 CIB 的内容。
- 策略引擎 PEngine:PEngine 用来计算集群的理想状态以及应如何实现这一状态。
- 集群资源管理守护进程 Cluster Resource Manager daemon(CRMd):用来实现集群决策的集中化,并协调集群所有集群成员和组件保持一致的状态。在集群中会选举一个主 CRMd 节点作为指定的控制器 (Designated Controller - DC) 来集中负责所有集群的决策。如果当选的 DC 进程(或其所在的节点)发生故障,新的 DC 进程会迅速建立。DC 会按先后顺序来处理 PEngine 发出的指令列表。DC 处理指令的过程就是把指令发送给本地节点上的 LRMd,或者通过集群消息层将指令发送给其他节点上的 CRMd,然后这些节点上的 CRMd 再将指令转发给各自节点的 LRMd 去处理。当集群节点运行完指令后,CRMd 进程会把他们接收到的指令执行结果以及日志返回给 DC,然后将执行结果与预期的对比,从而决定当前节点是应该再进行下一步的操作,还是直接取消当前执行的操作并要求 PEngine 根据实际执行结果再重新规划集群的理想状态并发出操作指令。
- 本地资源管理器守护进程 Local Resource Manager deamon(LRMd):每个节点包括一个 LRMd,它充当 CRMd 和资源间的接口。LRMd 将命令从 CRMd 传递给资源代理,如启动和停止状态信息。
- 集群资源 Cluster resource 是一个由集群服务管理的程序或服务实例,Pacemaker 通过资源代理访问集群资源。集群资源可以包括一下特性:
- 资源组:需要放置在一起并按顺序启动并按反顺序停止的资源。
- 约束(constraint):约束用来决定集群中资源的特性和关系。其中位置约束(location constraint)决定资源可在哪个节点上运行。
- 排序约束(ordering constraint)决定资源运行的顺序;共同位置约束(colocation constraint)决定资源相对于其他资源的位置。
- STONITH(Shoot The Other Node In The Head deamon):即隔离。以在 Pacemaker 集群中为集群的节点配置隔离设备, STONITH设备被当成资源模块并被配置到集群信息 CIB中。而 STONITH 进程(STONITHd)能够很好地理解 STONITH 设备的拓扑情况,当集群管理器要隔离某个节点时,只需 STONITHd 的客户端发出 Fencing 某个节点的请求,STONITHd 就会自动完成全部剩下的工作,即配置为集群资源的 STONITH 设会响应这个请求,并对节点做出 Fenceing 操作。而在实际使用中,根据不同厂商的服务器类型以及节点是物理机还是虚拟机,用户需要选择不同的 STONITH 设备。
- corosync:在集群成员之间提供心跳信息的消息服务。
- pcs:Pacemaker 的配置和管理工具。
参考
https://www.slideshare.net/slideshow/pacemaker-20230703v11fpptx/258854494
https://access.redhat.com/solutions/15575
https://en.wikipedia.org/wiki/High-availability_cluster#Node_configurations

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









