









爬虫第一讲
一、爬虫定义
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
二、爬虫分类
- 通用爬虫 :通常指搜索引擎的爬虫,比如google, 百度,搜狗这样的爬取整个互联网
- 聚焦爬虫,针对特定网站进行爬取,比如获取上海市气象数据,或者获取全国城市的经纬度
三、HTTP协议和HTTPs协议
HTTP协议 (HyperText Transfer Protocol,超文本传输协议):使用明文数据传输的网络协议。一直以来HTTP协议都是最主流的网页协议,但是互联网发展到今天,HTTP协议的明文传输会让用户存在一个非常大的安全隐患,端口号为80 。
HTTPS (Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。即是在HTTP的基础上增加了数据加密,端口号为 443 。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
URL(Uniform / Universal Resource Locator的缩写):统一资源定位符,是因特网的万维网服务程序上用于指定信息位置的表示方法。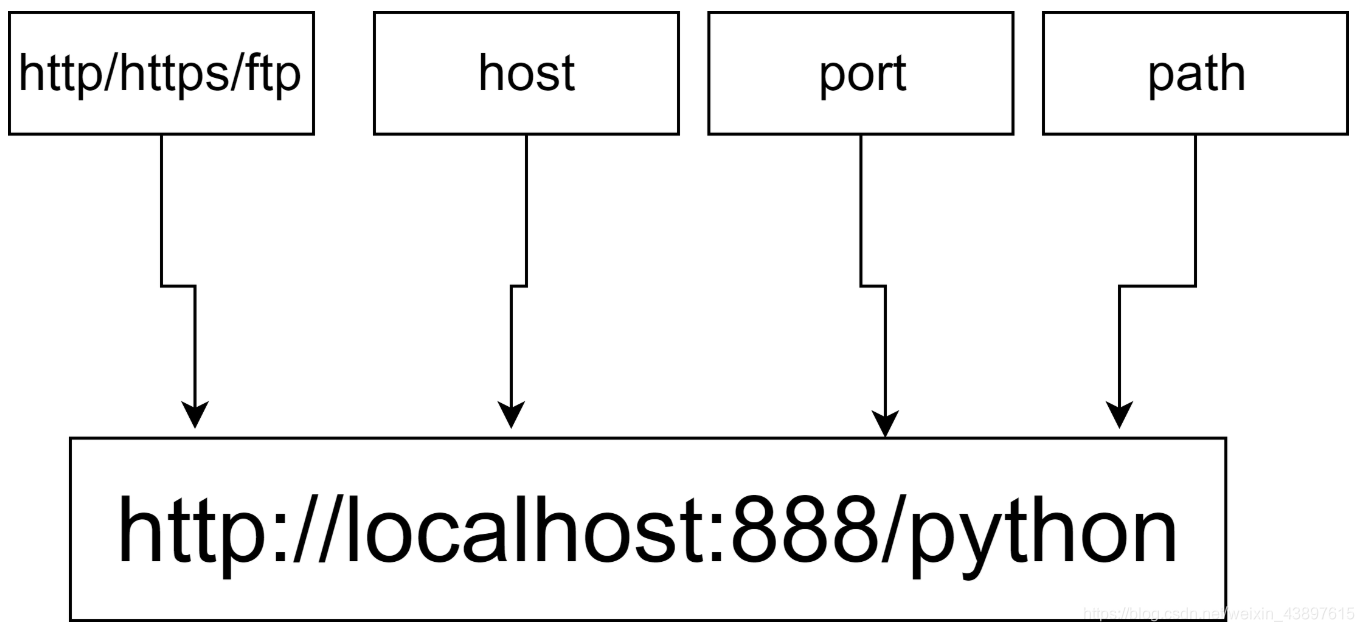
基本格式:scheme://host[:port#]/path/…/[?query-string][#anchor]
scheme:协议(例如:http, https, ftp)host:服务器的IP地址或者域名port#:服务器的端口(默认则端口号为80)path:访问资源的路径query-string:参数,发送给http服务器的数据anchor:锚(跳转到网页的指定锚点位置)
四、爬虫的一般流程
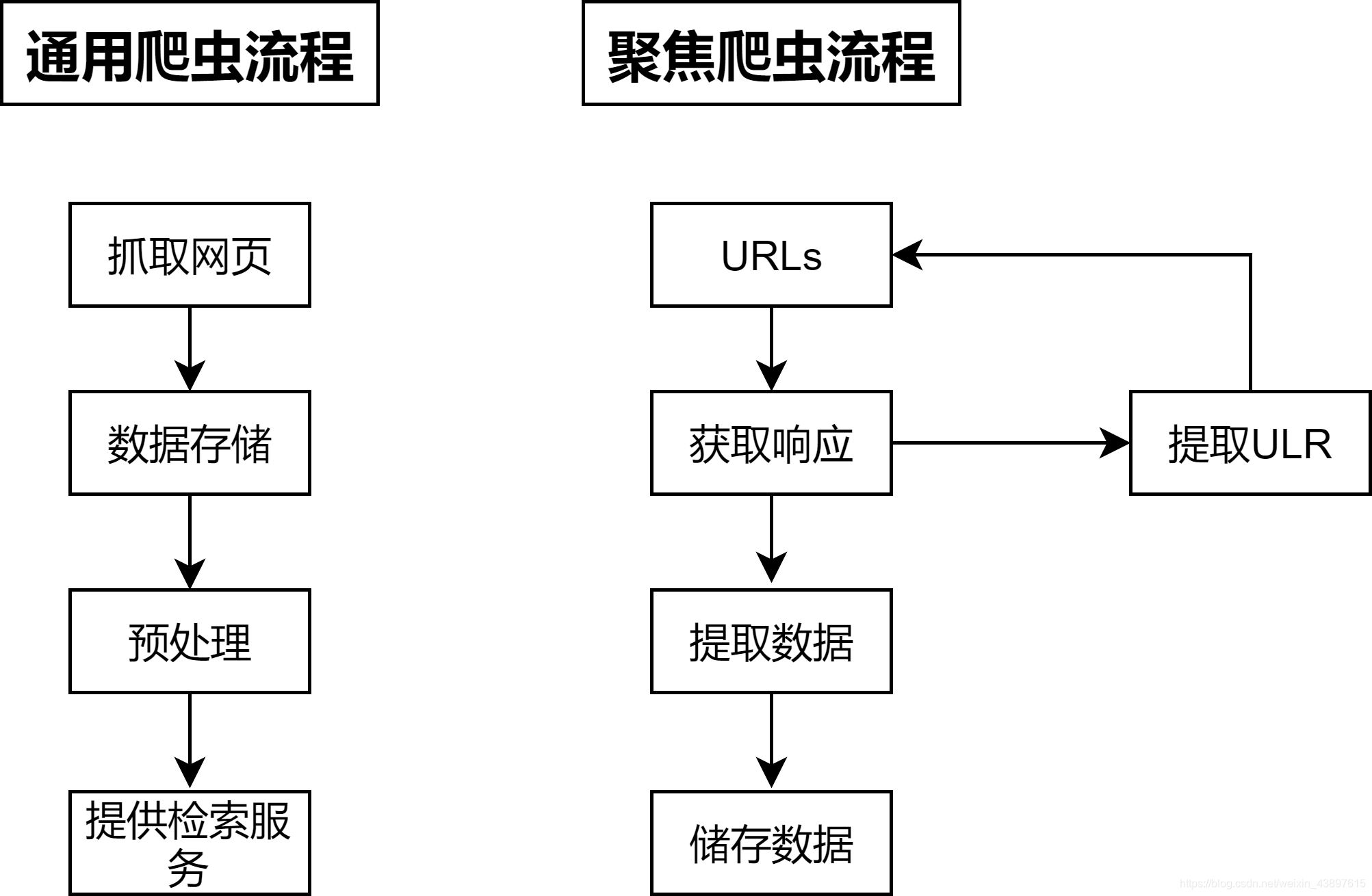
五、响应状态码
200:成功- 302:临时转移至新的url
- 307:临时转移至新的url
- 404:not found
- 500:服务器内部错误
如果你有问题,请随时发表评论。
码字不易,如果你觉得有用,请帮忙点个赞或者关注。

















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









