




|
SQL难点集
|
解决方案
|
|
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department 表包含公司所有部门的信息。
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
来源:力扣(LeetCode)
|
高版本的MySQL(8.x)版本或者Hive SQL有
窗口函数Dense_rank()可以满足此题的要求,
但问题是低版本的MySQL不支持窗口函数,所以只能寻求一般的方法进行解决。
#解法一:
SELECT t3.`Name` Department,t1.`Name` Employee,t2.Salary
FROM Employee t1
INNER
JOIN (
SELECT e1.DepartmentId,e1.Salary
FROM Employee e1
LEFT
JOIN Employee e2
ON e1.DepartmentId
= e2.DepartmentId
AND e1.Salary
< e2.Salary
GROUP
BY e1.DepartmentId,e1.Salary
HAVING
COUNT(
DISTINCT e2.Salary)
<=
2) t2
ON t1.DepartmentId
= t2.DepartmentId
AND t1.Salary
= t2.Salary
INNER
JOIN
Department t3
ON
t1.DepartmentId
=
t3.Id;
#解法二(常用):
SELECT d.
Name
AS
Department, e1.
Name
AS
Employee, e1.Salary
FROM Employee e1
JOIN Department d
ON e1.DepartmentId
= d.Id
WHERE
#工资级别数量小于等于3,即最多只有3个工资级别,也就是前三高
3
>=
(
SELECT
COUNT(
DISTINCT e2.Salary)
FROM Employee e2
WHERE
#e2的工资级别大于等于e1的工资级别
e2.Salary
>=
e1.Salary
AND e1.DepartmentId
= e2.DepartmentId)
ORDER
BY
e1.DepartmentId,e1.Salary
desc;
#解法三(同解法二):
SELECT
Department.NAME AS Department,
e1.NAME AS Employee,
e1.Salary AS Salary
FROM
Employee e1,Department d
WHERE
e1.DepartmentId = d.Id
AND 3 > (SELECT count(DISTINCT e2.Salary)
FROM Employee AS e2
WHERE e1.Salary < e2.Salary AND e1.DepartmentId = e2.DepartmentId)
ORDER BY d.NAME,Salary DESC;
#求部门最高工资
select
b.
Name
as
Department,a.
Name
Employee,a.Salary
from
Employee a
join
Department b
on
a.DepartmentId
=
b.Id
where
1
>=
(
select
count
(
distinct
Salary)
from
Employee c
where
c.Salary>=a.Salary
and
c.DepartmentId
=
a.DepartmentId);
PS:窗口函数整理
窗口函数的基本语法如下:
<窗口函数>
over
(
partition
by <用于分组的列名>
order
by <用于排序的列名>)
那么语法中的<窗口函数>都有哪些呢?
<窗口函数>的位置,可以放以下两种函数:
1)
专用窗口函数
,包括后面要讲到的
rank, dense_rank, row_number
等专用窗口函数。
2)
聚合函数
,如sum. avg, count, max, min,lag,lead等。
|
|
2.
体育馆的人流量
X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)。
请编写一个查询语句,找出人流量的高峰期。高峰期时,
至少连续三行记录中的人流量不少于100。
例如,表 stadium:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 1 | 2017-01-01 | 10 |
| 2 | 2017-01-02 | 109 |
| 3 | 2017-01-03 | 150 |
| 4 | 2017-01-04 | 99 |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-08 | 188 |
+------+------------+-----------+
每天只有一行记录,日期随着 id 的增加而增加。
体育馆并不是每天都开放的,所以记录中的日期可能会出现断层。
来源:力扣(LeetCode)
|
select
distinct
a.
*
from
stadium a,stadium b,stadium c
where
a.people
>=
100
and
b.people
>=
100
and
c.people
>=
100
and
((a.id
=
b.id
-
1
and
b.id
=
c.id
-
1
)
or
(a.id
=
c.id
-
1
and
c.id
=
b.id
-
1
)
or
(b.id
=
a.id
-
1
and
a.id
=
c.id
-
1
)
or
(b.id
=
c.id
-
1
and
c.id
=
a.id
-
1
)
or
(a.id
=
b.id
-
1
and
a.id
=
c.id
+
1
)
or
(a.id
=
b.id
+
1
and
b.id
=
c.id
+
1
))
order
by
a.id;
#
求相同的数据至少连续出现三次
select
distinct
a.Num
as
ConsecutiveNums
from
Logs
a,
Logs
b,
Logs
c
where
a.Num
=
b.Num
and
b.Num
=
c.Num
and
(
(a.id
=
b.id
-
1
and
b.id
=
c.id
-
1
)
or
(a.id
=
c.id
-
1
and
c.id
=
b.id
-
1
)
or
(b.id
=
a.id
-
1
and
a.id
=
c.id
-
1
)
or
(b.id
=
c.id
-
1
and
c.id
=
a.id
-
1
)
or
(a.id
=
b.id
-
1
and
a.id
=
c.id
+
1
)
or
(a.id
=
b.id
+
1
and
b.id
=
c.id
+
1
)
)
|
|
3.
行程和用户
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
+----+-----------+-----------+---------+--------------------+----------+
| Id | Client_Id | Driver_Id | City_Id | Status |Request_at|
+----+-----------+-----------+---------+--------------------+----------+
| 1 | 1 | 10 | 1 | completed |2013-10-01|
| 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01|
| 3 | 3 | 12 | 6 | completed |2013-10-01|
| 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01|
| 5 | 1 | 10 | 1 | completed |2013-10-02|
| 6 | 2 | 11 | 6 | completed |2013-10-02|
| 7 | 3 | 12 | 6 | completed |2013-10-02|
| 8 | 2 | 12 | 12 | completed |2013-10-03|
| 9 | 3 | 10 | 12 | completed |2013-10-03|
| 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03|
+----+-----------+-----------+---------+--------------------+----------+
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+
| Users_Id | Banned | Role |
+----------+--------+--------+
| 1 | No | client |
| 2 | Yes | client |
| 3 | No | client |
| 4 | No | client |
| 10 | No | driver |
| 11 | No | driver |
| 12 | No | driver |
| 13 | No | driver |
+----------+--------+--------+
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
取消率的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)
+------------+-------------------+
| Day | Cancellation Rate |
+------------+-------------------+
| 2013-10-01 | 0.33 |
| 2013-10-02 | 0.00 |
| 2013-10-03 | 0.50 |
+------------+-------------------+
来源:力扣(LeetCode)
|
SELECT DAY,
round( c1 / c2, 2 ) AS 'Cancellation Rate'
FROM
(
SELECT
t3.Request_at AS DAY,
sum( t3.num1 ) c1,
count( 0 ) c2
FROM
(
SELECT
t2.*,
CASE
WHEN t2.STATUS = 'cancelled_by_driver'
OR t2.STATUS = 'cancelled_by_client' THEN
1 ELSE 0
END AS num1
FROM
(
SELECT
t1.*,
c.Banned AS driver_Banned
FROM
(
SELECT
a.*,
b.Banned AS client_Banned
FROM
Trips a
JOIN Users b ON a.Client_Id = b.Users_Id
WHERE
b.Banned = 'No'
) t1
JOIN Users c ON t1.Driver_Id = c.Users_Id
WHERE
c.Banned = 'No'
) t2
) t3
GROUP BY
Request_at
) t4
ORDER BY
DAY;
(自己写出来的!但速度比较慢)---->类似的求一个比率的解法都与该题一样的思路。
|
|
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
例如上述 Employee 表,n=2 时,应返回第二高的薪水200。如果不存在第 n 高的薪水,应返回 null。
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
来源:力扣(LeetCode)
|
CREATE
FUNCTION
getNthHighestSalary(N
INT
)
RETURNS
INT
BEGIN
set
n
=
N
-
1
;
RETURN
(
# Write your MySQL query statement below.
select
ifnull
(
(
select
distinct
Salary getNthHighestSalary
from
Employee
order
by
Salary
desc
limit
n,
1
),
null
)
);
END
注:
(1)
ifnull() 函数
用于判断第一个表达式是否为NULL,若为NULL则返回第二个参数的值,若不为NULL则返回第一个参数的值。
(2)
isnull(expr)函数:
如expr 为null,那么isnull() 的返回值为 1,否则返回值为 0.
(3)
nullif()函数:nullif
(exp1,exp2):给定两个参数
exp1,exp2
,若
两个参数相等,则返回NULL;
否则就返回第一个参数。
(4)
coalesce()函数:返回一系列表达式中第一个非空数值。
(5)
nvl()函数(oracle):
Mysql 没有nvl()函数,却有一个类似功能的函数
ifnull()
。
|
|
5.
分数排名
如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
+-------+------+
|
select
a.Score
as
Score,
(
select
count
(
distinct
b.Score)
from
Scores b
where
b.Score
>=
a.Score)
as
'Rank'
from
Scores a
order
by
Score
DESC
;
|
|
6.考试分数中位数
牛客每次考试完,都会有一个成绩表(grade),如下:
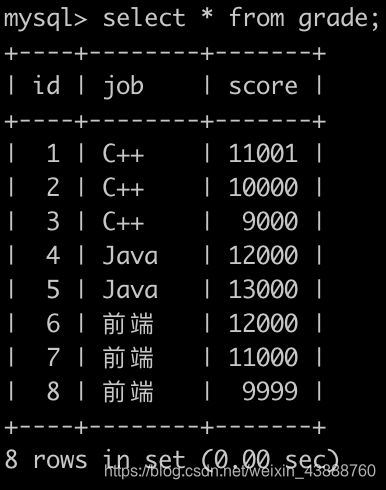
第1行表示用户id为1的用户选择了C++岗位并且考了11001分
第8行表示用户id为8的用户选择了前端岗位并且考了9999分
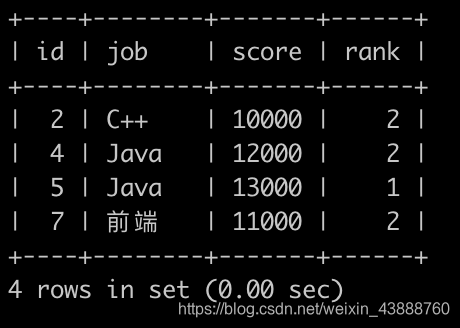
请你写一个sql语句查询各个岗位分数的中位数
位置上的所有grade信息
,并且按
id
升序排序,结果如下:
|
select B.* from
(select job, cast((count(id)+1)/2 AS INTEGER) as
'start'
, (cast((count(id)+1)/2 AS INTEGER)+(
case
when count(id)%2=1 then 0
else
1 end)) as
'end'
from grade
group by job) A
JOIN
(select g1.*, (
select count(distinct g2.score)
from grade g2
where g2.score>=g1.score and g1.job=g2.job) as rank
from grade g1 ) B
on (A.job=B.job and B.rank between A.start and A.end)
order by B.id
;
select id,job,score,rn from
(select *,
case
cn%
2
when
0
then cast(round(cn*
1.0
/
2
,
0
) as
int
)
when
1
then cast(round(cn*
1.0
/
2
,
0
) as
int
)
else
-
1
end as mid,
case
cn%
2
when
1
then
1
when
0
then
0
else
-
1
end as oe
from
(select *, count(*) over(partition by job) cn,
row_number() over(partition by job order by score desc) rn from grade
) t1
) t2
where (oe=
1
and rn=mid) or (oe=
0
and rn=mid) or (oe=
0
and rn=mid+
1
)
order by id;
#确定中位数位置
select job, case when num%2=1 then (num+1)/2 else num/2 end as start,
case when num%2=1 then (num+1)/2 else num/2+1 end as end
from (select job,count(id) num
from grade group by job) t order by job;
|
7、牛客每个人最近的登录日期
牛客每天有很多人登录,请你统计一下牛客每个日期新用户的次日留存率。
有一个登录(login)记录表,简况如下:
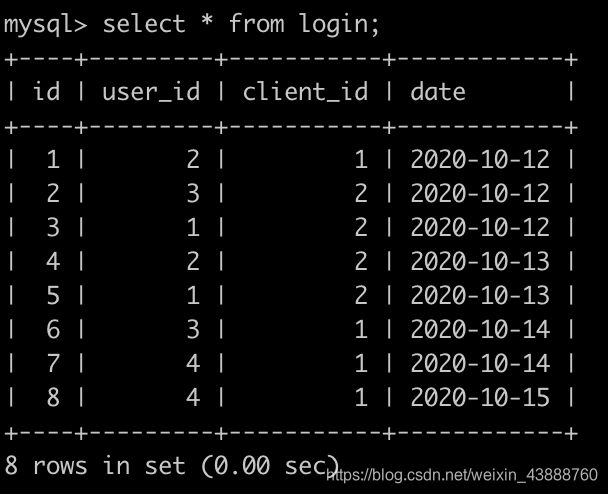
第1行表示id为2的用户在2020-10-12使用了客户端id为1的设备登录了牛客网,因为是第1次登录,所以是新用户
。。。
第4行表示id为2的用户在2020-10-13使用了客户端id为2的设备登录了牛客网,因为是第2次登录,所以是老用户
。。
第4行表示id为4的用户在2020-10-15使用了客户端id为1的设备登录了牛客网,因为是第2次登录,所以是老用户
请你写出一个sql语句查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序,上面的例子查询结果如下:
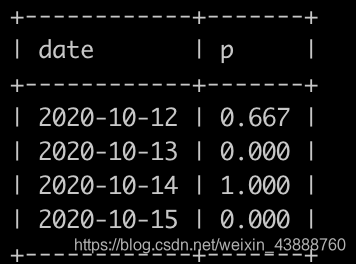
查询结果表明:
2020-10-12登录了3个(id为2,3,1)新用户,2020-10-13,只有2个(id为2,1)登录,故2020-10-12新用户次日留存率为2/3=0.667;
2020-10-13没有新用户登录,输出0.000;
2020-10-14登录了1个(id为4)新用户,2020-10-15,id为4的用户登录,故2020-10-14新用户次日留存率为1/1=1.000;
2020-10-15没有新用户登录,输出0.000;
(注意:sqlite里查找某一天的后一天的用法是:date(yyyy-mm-dd, '+1 day'),sqlite里1/2得到的不是0.5,得到的是0,只有1*1.0/2才会得到0.5)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
SQL
最新推荐文章于 2023-04-23 15:15:45 发布

















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









