






 本文讲述了搭建Spark环境后调测样例时出现初始作业未接受资源的错误,可通过spark - shell查看SparkContext上下文信息。经分析,问题是内存不足导致,修改集群环境中spark - env.sh文件的内存配置后,执行成功。
本文讲述了搭建Spark环境后调测样例时出现初始作业未接受资源的错误,可通过spark - shell查看SparkContext上下文信息。经分析,问题是内存不足导致,修改集群环境中spark - env.sh文件的内存配置后,执行成功。
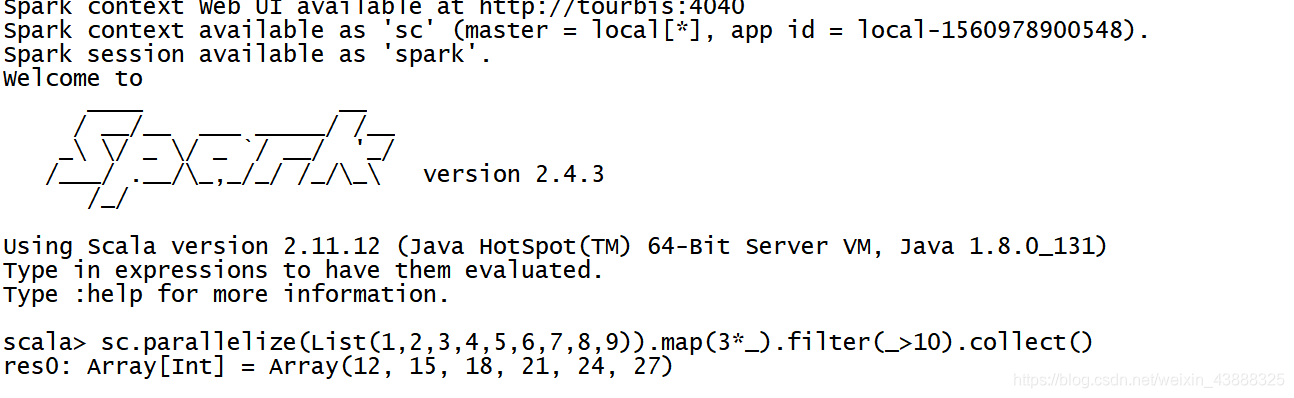
搭建Spark环境后,调测Spark样例(sc.parallelize(List(1,2,3,4,5,6,7,8,9)).map(3*).filter(>10).collect())
时出现下面的错误:
WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
同时可以通过spark-shell查看SparkContext获取的上下文信息, 如下操作:
[hadoop@gpmaster bin]$ ./spark-shell
…
scala> sc.getConf.getAll.foreach(println)
(spark.fileserver.uri,http://192.168.1.128:34634)
(spark.app.name,Spark shell)
(spark.driver.port,25392)
(spark.app.id,app-20151001090322-0001)
(spark.repl.class.uri,http://192.168.1.128:24988)
(spark.externalBlockStore.folderName,spark-1254a794-fbfa-4b4c-9757-b5a94dc26ffc)
(spark.jars,)
(spark.executor.id,driver)
(spark.submit.deployMode,client)
(spark.driver.host,192.168.1.128)
(spark.master,spark://192.168.1.128:7077)
scala> sc.getConf.toDebugString
res8: String =
spark.app.id=app-20151001090322-0001
spark.app.name=Spark shell
spark.driver.host=192.168.1.128
spark.driver.port=25392
spark.executor.id=driver
spark.externalBlockStore.folderName=spark-1254a794-fbfa-4b4c-9757-b5a94dc26ffc
spark.fileserver.uri=http://192.168.1.128:34634
spark.jars=
spark.master=spark://192.168.1.128:7077
spark.repl.class.uri=http://192.168.1.128:24988
spark.submit.deployMode=client
- 内存不足
我的环境就是因为内存的原因。
我集群环境中,spark-env.sh 文件配置如下:
export JAVA_HOME=/usr/java/jdk1.7.0_60
export SCALA_HOME=/usr/local/scala
export SPARK_MASTER_IP=192.168.1.128
export SPARK_WORKER_MEMORY=100m
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.0/etc/hadoop
export MASTER=spark://192.168.1.128:7077
修改后执行成功:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









