




SearXNG 是一个元搜索引擎,它聚合了其他搜索引擎的结果。通过SearXNG可以搭建自己的搜索工具,也可以在大模型编程中整合该工具,实现实时内容的查询。
SearXNG 不会像 Google 那样提供个性化结果,但它不会生成任何关于用户的个人资料;
SearXNG 不关心用户搜索什么,从不会向第三方分享搜索内容,不会对用户带来危害;
SearXNG 是免费软件,代码是 100% 开放的。
线上访问地址:SearXNG
通过docker搭建SearXNG环境
clone部署环境的配置
git clone https://github.com/searxng/searxng-docker.git
修改docker-compose.yml(可选)
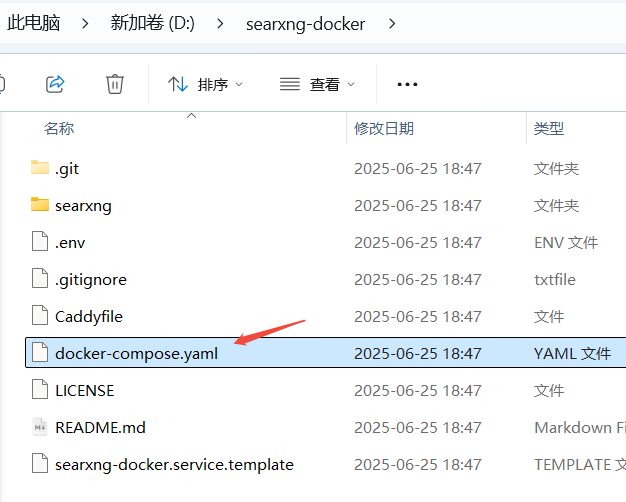
需要安装的容器:
Caddy:反向代理工具 (create a LetsEncrypt certificate automatically)
SearXNG:SearXNG工具
Valkey:内存数据库
为了避免冲突,本例仅修改searxng的映射端口号为8088。

修改setting.xml配置
# see https://docs.searxng.org/admin/settings/settings.html#settings-use-default-settings
use_default_settings: true
engines:
# enable engine
- name: baidu
engine: baidu
disabled: false
- name: 360search
engine: 360search
disabled: false
- name: sogou
engine: sogou
disabled: false
- name: bing
engine: bing
disabled: false
# disable engine
- name: archlinuxwiki
engine: archlinux
disabled: true
- name: duckduckgo
engine: duckduckgo
distabled: true
- name: github
engine: github
shortcut: gh
disabled: true
- name: wikipedia
engine: wikipedia
disabled: true
- name: google
engine: google
disabled: true
- name: youtube
engine: youtube_noapi
disabled: true
- name: duckduckgo
engine: duckduckgo
disabled: true
- name: qwant
engine: qwant
disabled: true
- name: brave
engine: brave
disabled: true
- name: startpage
engine: startpage
disabled: true
server:
# base_url is defined in the SEARXNG_BASE_URL environment variable, see .env and docker-compose.yml
secret_key: "werlwejFLWJqwqw334" # change this!
limiter: false # enable this when running the instance for a public usage on the internet
image_proxy: true
search:
formats:
- html
- json
ui:
static_use_hash: true
redis:
url: redis://redis:6379/0
engines配置用来设置启用和禁用的搜索工具,本例启用了百度、360搜索、搜狗搜索、bing搜索。
search.formats配置用于设置支持的格式,必须配置json,否则调用搜索的api接口时,会报403的错误。
运行容器

访问SearXNG
路径:http://127.0.0.1:8088


通过执行具体的搜索,可以看到内部使用的搜索引擎的情况。经过多次测试,searxng的搜索速度相对较慢,使用的搜索工具经常超时。
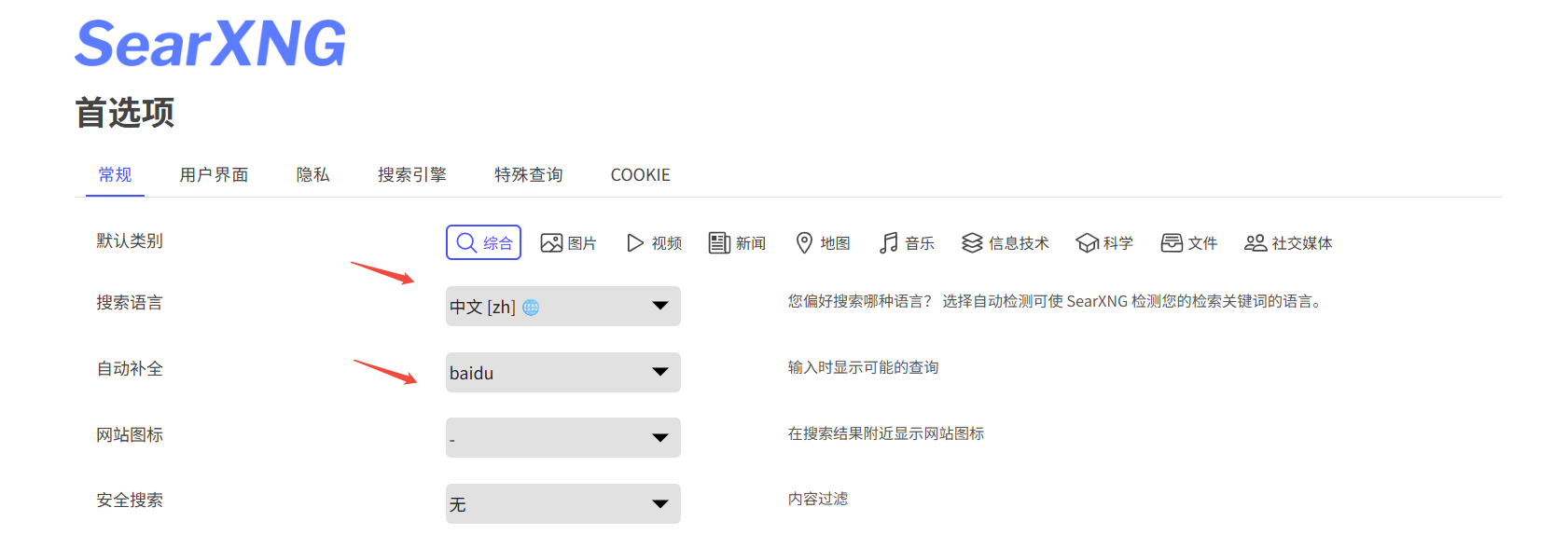
设置搜索语言和自动补全的方式:
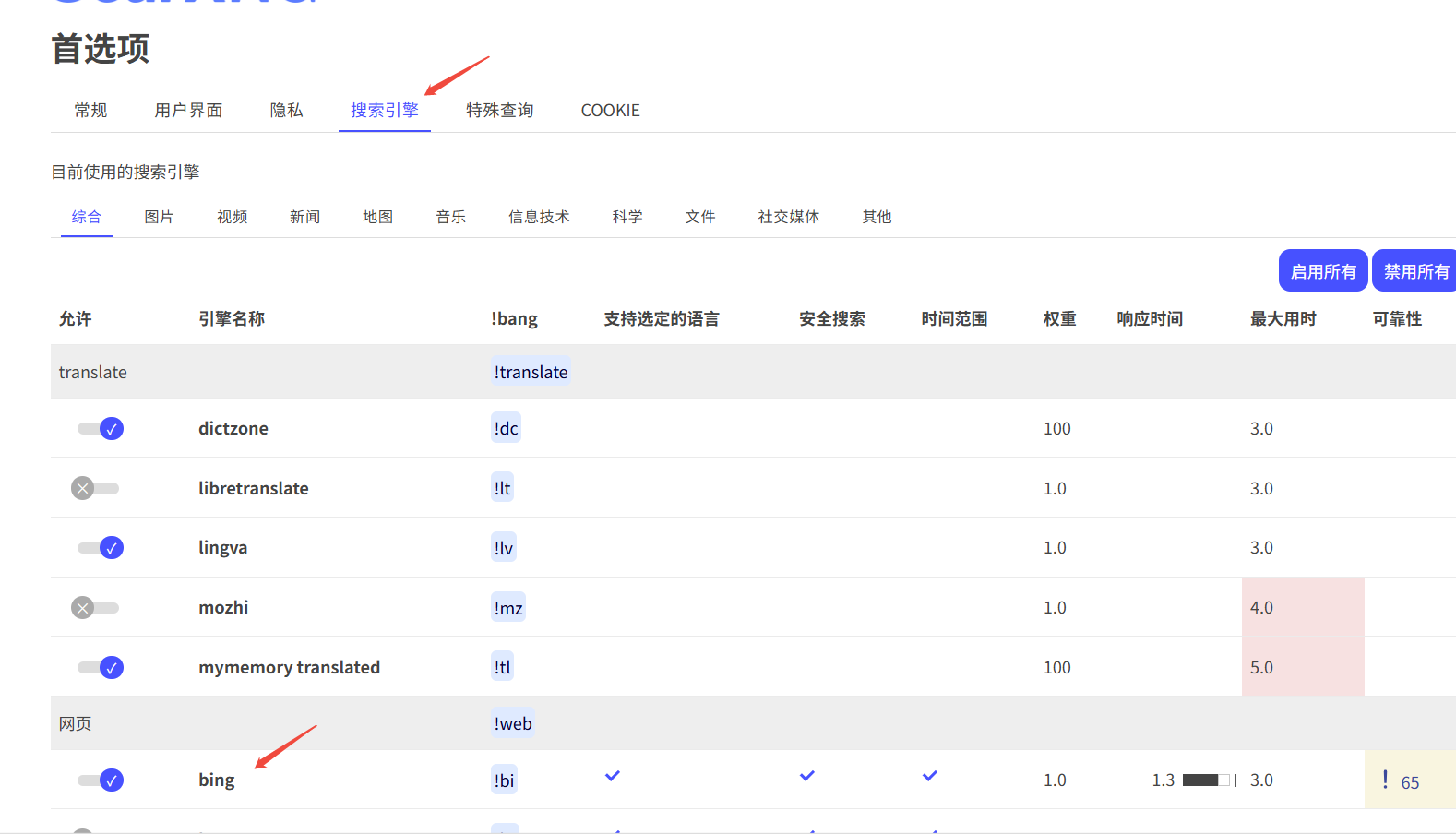
 通过搜索引擎标签可以查看支持的搜索工具:
通过搜索引擎标签可以查看支持的搜索工具:

LangChain4j中集成SearXNG
LangChain4j支持的搜索工具:
Google Custom Search:国内无法正常访问
SearchApi
SearXNG
Tavily:需要申请api key
额外导入searxng的jar
注意:其他需要导入的jar参考之前的博客
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-web-search-engine-searxng</artifactId>
<version>1.0.0-beta2</version>
</dependency>测试代码
LangChain4j中将搜索引擎作为检索工具使用。本例特意使用了两种ContentRetriver对象,用于检测Query Router的效果。
package com.renr.langchain4jnew.app5;
import com.renr.langchain4jnew.constant.CommonConstants;
import dev.langchain4j.community.model.zhipu.ZhipuAiChatModel;
import dev.langchain4j.community.web.search.searxng.SearXNGWebSearchEngine;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.embedding.onnx.bgesmallzhv15.BgeSmallZhV15EmbeddingModel;
import dev.langchain4j.rag.DefaultRetrievalAugmentor;
import dev.langchain4j.rag.RetrievalAugmentor;
import dev.langchain4j.rag.content.retriever.ContentRetriever;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.rag.content.retriever.WebSearchContentRetriever;
import dev.langchain4j.rag.query.router.LanguageModelQueryRouter;
import dev.langchain4j.rag.query.router.QueryRouter;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import dev.langchain4j.web.search.WebSearchEngine;
import java.net.URISyntaxException;
import java.net.URL;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.time.Duration;
import java.util.HashMap;
import java.util.Map;
public class AdvancedRAG06_WebSearch {
public static void main(String[] args) throws URISyntaxException {
// 获取待加载的文档路径
URL fileUrl = AdvancedRAG06_WebSearch.class.getClassLoader().getResource("document/医院.txt");
Path path = Paths.get(fileUrl.toURI());
// 指定文档解析器
DocumentParser documentParser = new TextDocumentParser();
// 加载文档数据
Document document = FileSystemDocumentLoader.loadDocument(path, documentParser);
EmbeddingModel embeddingModel = new BgeSmallZhV15EmbeddingModel();
EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(200, 0))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(3)
.minScore(0.6)
.build();
ChatLanguageModel chatModel = ZhipuAiChatModel.builder()
// 模型key
.apiKey(CommonConstants.API_KEY)
// 精确度
.temperature(0.9)
.model("GLM-4-Flash")
.maxRetries(3)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.logRequests(true)
.logResponses(true)
.build();
// 创建搜索引擎对象
WebSearchEngine webSearchEngine = SearXNGWebSearchEngine.builder()
.baseUrl("http://127.0.0.1:8088/")
//.logRequests(true)
//.logResponses(true)
.build();
// 在检索对象中设置搜索引擎对象
ContentRetriever webSearchContentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(webSearchEngine)
.maxResults(3)
.build();
// 查询路由,将不同的查询路由到不同的Retriver
Map<ContentRetriever, String> retrieverToDescription = new HashMap<>();
retrieverToDescription.put(contentRetriever, "医院的信息");
retrieverToDescription.put(webSearchContentRetriever, "搜索工具");
QueryRouter queryRouter = new LanguageModelQueryRouter(chatModel, retrieverToDescription);
// 检索增强器
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryRouter(queryRouter)
.build();
ChatMemoryProvider chatMemoryProvider = new ChatMemoryProvider() {
@Override
public ChatMemory get(Object o) {
return MessageWindowChatMemory.withMaxMessages(10);
}
};
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.retrievalAugmentor(retrievalAugmentor)
.chatMemoryProvider(userId -> MessageWindowChatMemory.withMaxMessages(10))
.build();
String answer = assistant.chat("郑州近期的的天气情况");
System.out.println(answer);
}
}执行结果

从执行结果看出,本例虽然使用了多个ContentRetriver对象,但是由于使用了LanguageModelQueryRouter进行路由查询,搜索结果没有受到影响。
核心代码
// 创建搜索引擎对象,指定searxng的访问地址
// 内部调用 http://127.0.0.1:8088/search?q=xxx&format=json
WebSearchEngine webSearchEngine = SearXNGWebSearchEngine.builder()
.baseUrl("http://127.0.0.1:8088/")
//.logRequests(true)
//.logResponses(true)
.build();
// 在检索对象中设置搜索引擎对象
ContentRetriever webSearchContentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(webSearchEngine)
.maxResults(3)
.build();
// 查询路由,将不同的查询路由到不同的Retriver
// 也测试了QueryRouter queryRouter = new DefaultQueryRouter(contentRetriever, webSearchContentRetriever)的写法,执行结果不尽如人意
Map<ContentRetriever, String> retrieverToDescription = new HashMap<>();
retrieverToDescription.put(contentRetriever, "医院的信息");
retrieverToDescription.put(webSearchContentRetriever, "搜索工具");
QueryRouter queryRouter = new LanguageModelQueryRouter(chatModel, retrieverToDescription);
// 检索增强器,指定查询路由对象
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.queryRouter(queryRouter)
.build();


















 4211
4211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









