




DeepSeek模型介绍
现在使用的主要是两个版本:
DeepSeek-V3:通用型模型,专注于自然语言处理、知识问答、内容创作等通用任务。
DeepSeek-R1:专注于数学、代码生成和复杂逻辑推理任务设计。
一些术语
DeepSeekMoE:
DeepSeekMoE中的MoE指的是“Mixture of Experts(专家混合)”。MoE通过将模型划分为多个“专家”,只在需要时激活相关专家,从而提升效率。每个MoE层包含1个共享专家和256个路由专家。
DeepSeekMLA:
DeepSeekMLA(Multi-head Latent Attention,多头潜在注意力)。推理的最大瓶颈之一在于内存占用:不仅需要加载整个模型,还要加载整个上下文窗口(context window)。而上下文窗口在内存中非常昂贵,因为每个token都需要存储一个Key-Value。DeepSeekMLA让Key-Value存储得以压缩,从而大幅降低推理时的内存使用。
蒸馏技术:
模型蒸馏是一种优化技术,通过模仿教师模型的输出,训练一个较小的学生模型,从而实现知识的传递。教师模型通常具有较高的性能,但计算成本高昂,而学生模型则更加轻量级,推理速度更快,且内存占用更少。
DeepSeek通过创新的蒸馏技术、精心准备的数据、有效的蒸馏方法和模型微调与优化等手段,成功地将R1的模型能力蒸馏到Qwen-1.5B中,使得Qwen-1.5B具备了与o1-mini相似的能力。
配置DeepSeek本地环境
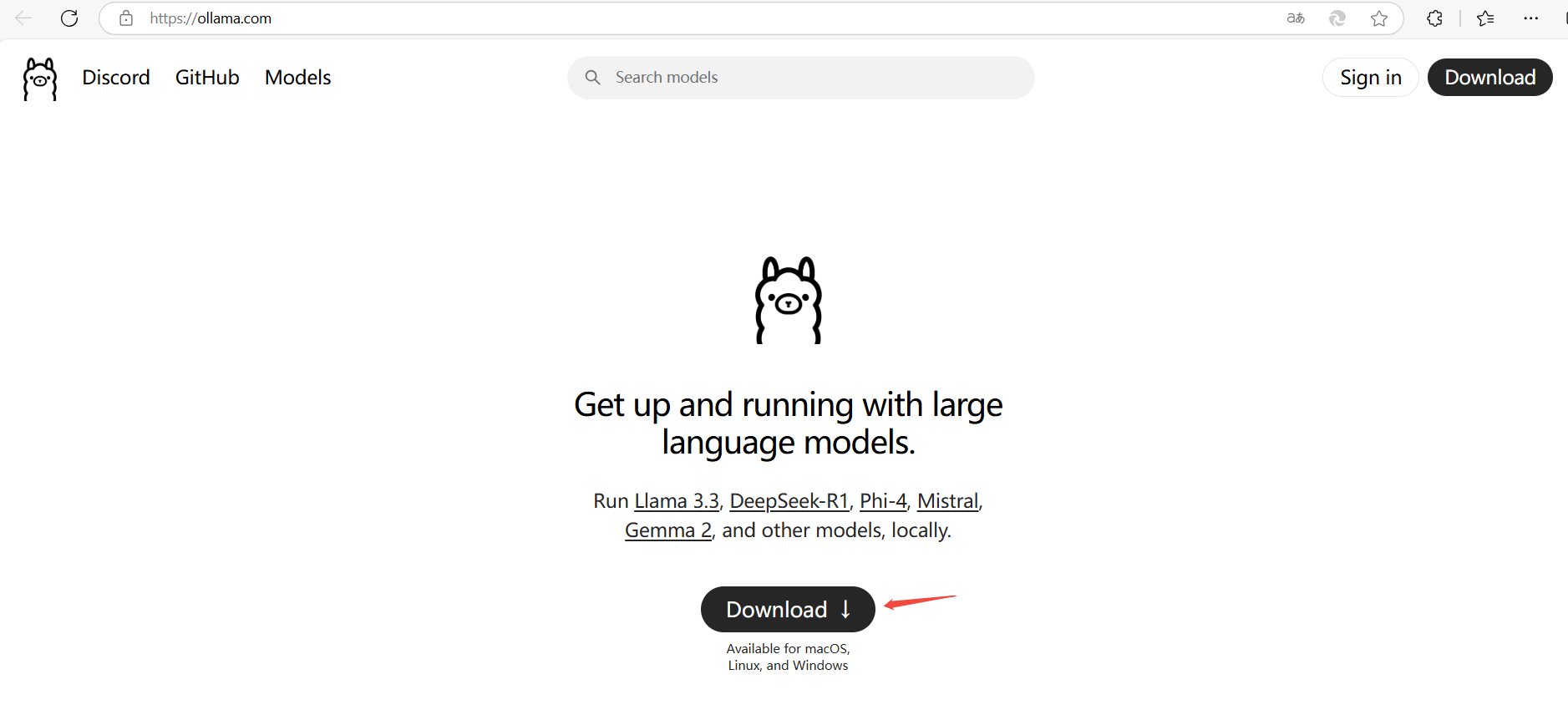
安装ollama
下载ollama
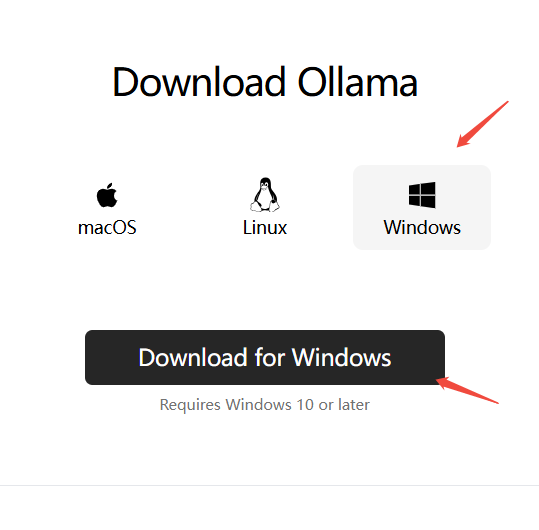
安装到指定位置
双击该文件即可安装,默认安装到C盘用户目录下
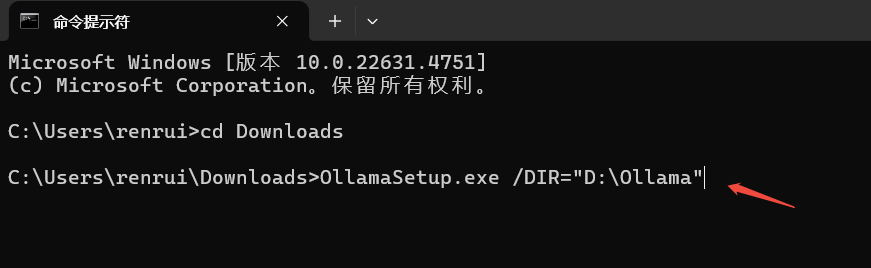
本例将其安装到D盘,安装命令如下:
OllamaSetup.exe /DIR="D:\Ollama"
拉取DeepSeek模型
在ollama的官网可以查看相关模型
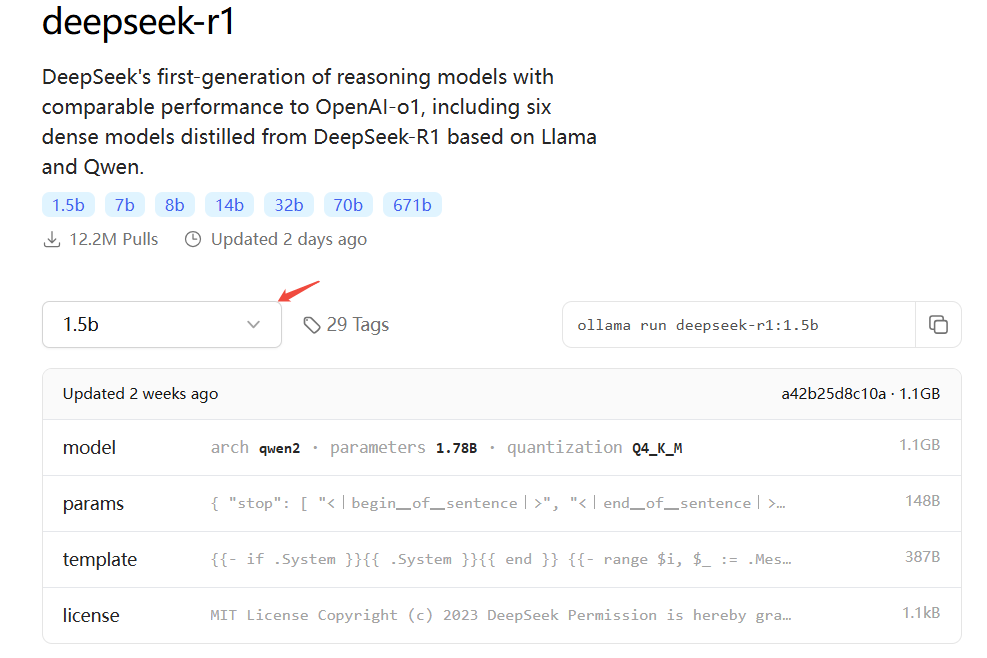
拉取指定模型
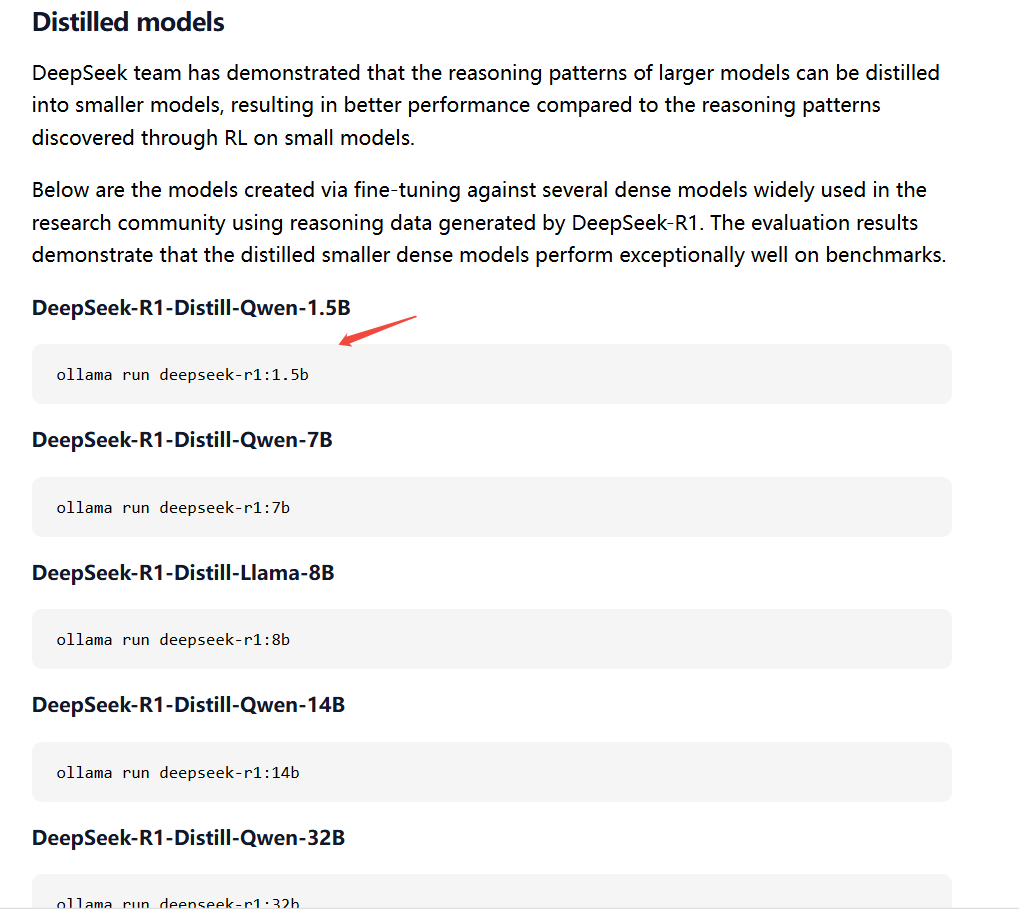
本例拉取1.5B,命令如下:
ollama run deepseek-r1:1.5b
开始拉取

拉取完成

开始聊天

ctrl+d或者/bye 可以结束聊天
修改模型拉取的位置
默认拉取到C盘用户目录下
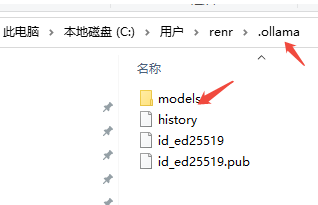
将models拷贝到D盘ollama的安装目录
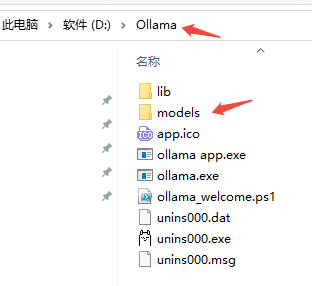
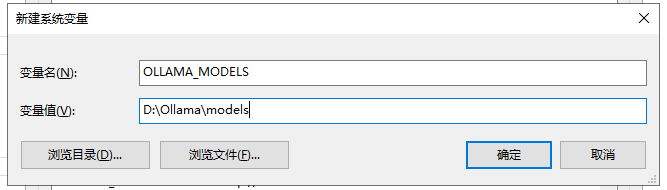
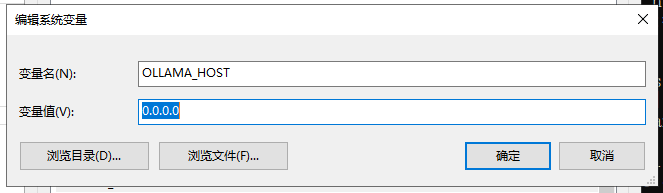
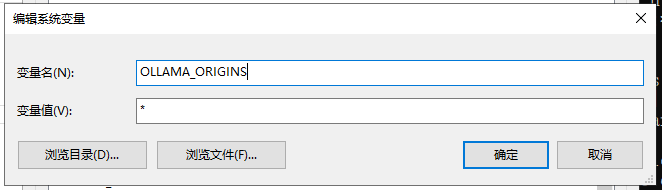
增加环境变量
查看已经拉取的模型

运行模型

通过api调用ollama
参考帮助文档:
https://github.com/ollama/ollama/blob/main/docs/api.md
https://www.llamafactory.cn/ollama-docs/api.html
根据如下案例测试

通过工具测试
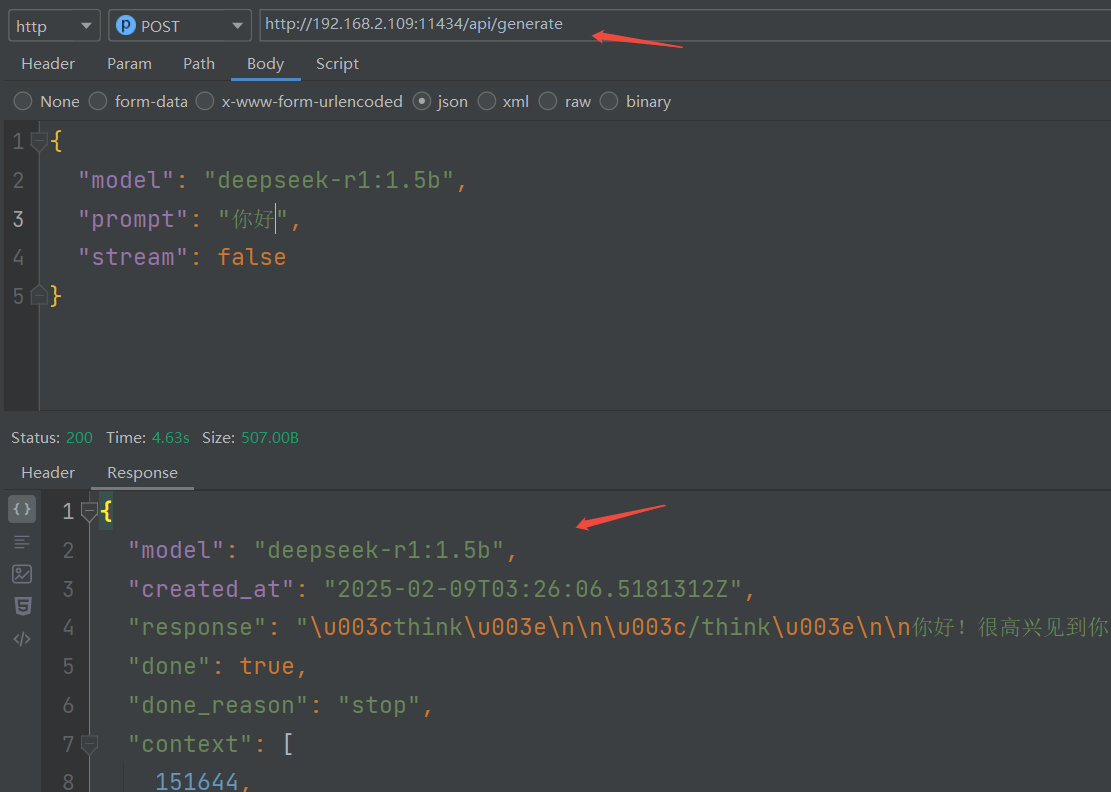
:::warning
注意:远程调用会提示无法连接,是跨域引起的,需要配置环境变量
:::



















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









