







我整理了一些单目深度估计的论文,github地址:awesome-Monocular-Depth-Estimation 持续更新中
2017 CVPR
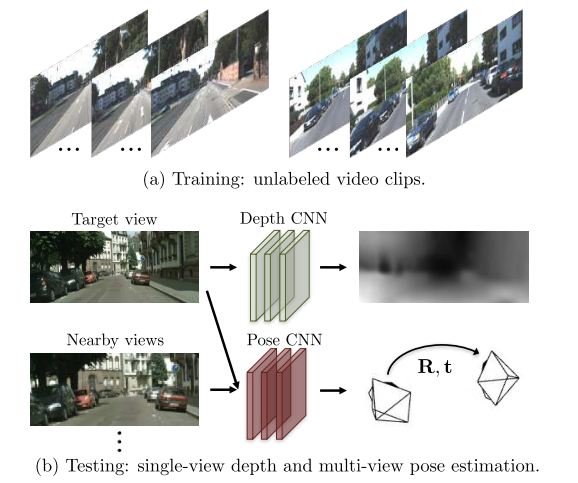
[pdf][video] Unsupervised Learning of Depth and Ego-Motion from Video [tensorflow][pytorch] 🔥⭐️
概述
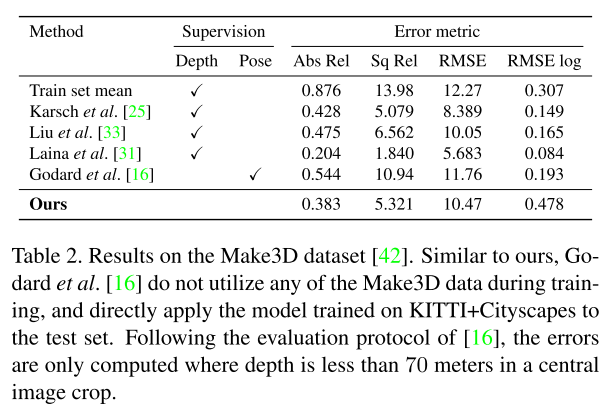
提出了一个从非结构化的视频序列中估计单目深度和相机运动的无监督的学习框架。方法建立在只有场景几何和相机姿势的中间预测与真实相对应时,几何视图合成系统才能始终表现良好,因此将整个视图合成pipeline定为CNN。用KITTI数据集训练,在Make3D数据集上评价泛化能力
假设:
1)场景是静止的没有移动的物体 2)目标视图和源视图之间没有遮挡物和去除遮挡物 3)表面是朗伯曲面,因此一致性误差有意义
系统优势:
1)单目深度的表现和使用真值姿势或深度进行训练的有监督方法相当 2)在可比较的输入设置下,姿态估计的性能优于SLAM系统。
方法:
模型直接从像素映射到自运动估计和底层场景结构。深度和姿态预测CNN的关键监督信号来自视图合成任务:给定一个场景的输入视图,合成从不同相机姿势看到的场景的新图像。
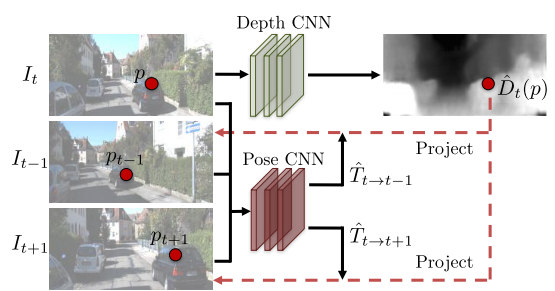
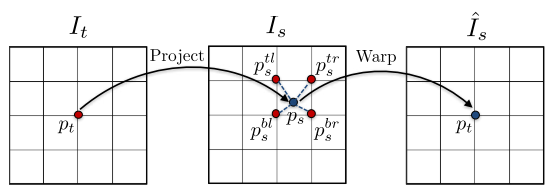
其实是有一张target图像,通过depth net和pose net预测得到的结果,由target图像project到source图像上,再warp到target图像计算重投影误差。warp在本文实际上是一个用双线性插值找最近栅格点的过程。这里有详细的解释。
https://zhuanlan.zhihu.com/p/297348430
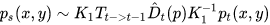
问题:
梯度由I(pt)和相邻的四个I(ps)的像素强度差值产生,当正确的ps在低纹理区域或者远离正确估计时会抑制训练。解决:1)使用卷积编码-解码器 2)用多尺度和平滑损失(本文采用方法)
网络:
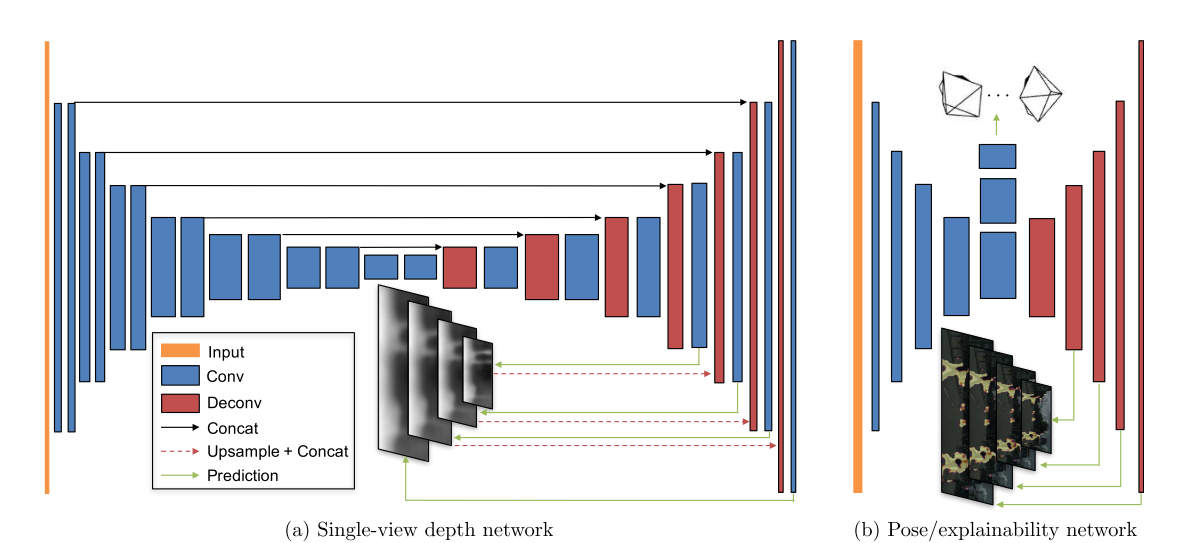
深度网络的输入是目标视图It,输出为每个像素的深度图Dt,对单视图深度网络,采用的是能多尺度预测的DispNet; 姿态网络的输入是目标视图It和临近/源视图It-1,It+1,输出是相对相机位姿Tt->t-1,Tt->t+1,两个网络的输出(深度和相对位姿)被用来逆扭曲源图来重建目标图。姿态网络和解释网络共享前几个卷积层,然后分别预测6-DoF相对位姿和多尺度可解释性掩码。两个网络的输出被用来反向将源视图Is重建目标视图It,CNN训练中使用的是光度重建损失。

E
^
(
s
)
\hat E(s)
E^(s)为可解释性预测网络为每个target-source对输出的每像素的soft mask,表明网络相信可以为每个目标像素成功建模直接视图合成的位置。 因为很可能在优化中
E
^
(
s
)
\hat E(s)
E^(s)=0,所以添加了一个正则项Lreg ,Lvs是目标图和合成图的像素差的loss。在学习时,梯度可能在I(pt)和四个I(ps)的像素强度差异产生,如果正确的ps在低纹理区域或者远离正确估计时会抑制训练,因此引入Lsmooth平滑损失。
训练:
单视图深度估计:除了输出层其他所有层都用批归一化,输入图像大小限制在128*416,一个图像序列为3帧。在更大的数据集上预训练,然后在kitti上微调,性能可以微微提升.
姿态估计:kitti00-08训练,09-10测试,一组图像序列为5帧。有限优化每种方法作预测的尺度因子,测量ATE作为度量
结果:
单视图深度估计:
将预测的深度图乘一个比例因子
s
^
\hat s
s^来评估结果,
s
^
=
m
e
d
i
a
n
(
D
g
t
)
/
m
e
d
i
a
n
(
D
p
r
e
d
)
\hat s = median(D~gt~)/ median(D~pred~)
s^=median(D gt )/median(D pred )
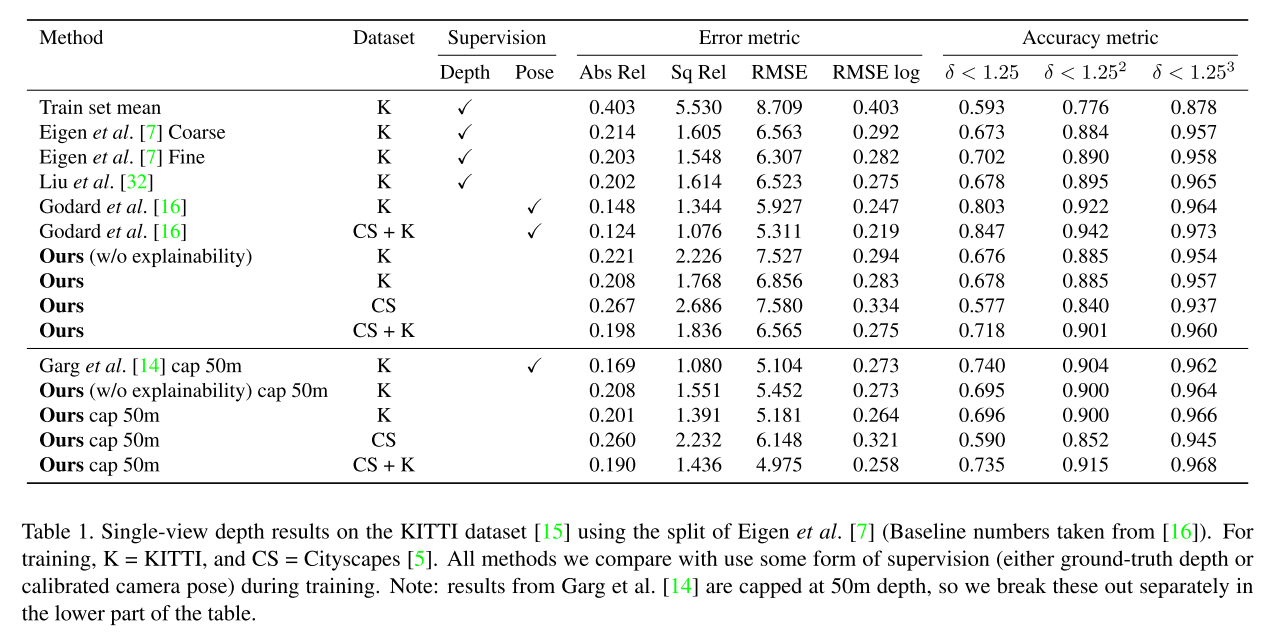
和一些有监督的方法相当但比另外一些的要差,为了可视化使用,真值深度图由系数测量差值得到,在开阔的场景和物体十分靠近前视相机时模型会失败。cityscapes模型有时难以恢复汽车、灌木的完整形状,错认为是远处的物体。消融实验证明可解释性模型只提供了适度的性能提升,解释 1)kitti数据集大多场景是静态的 2)遮挡、可见值发生在短时间内。




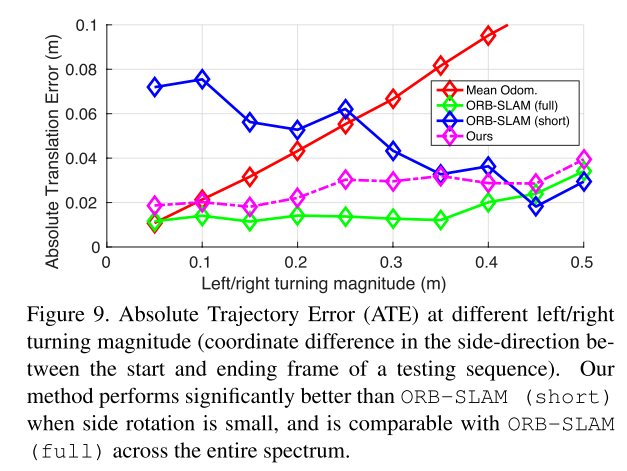
姿态估计:
1)与orb-slam比较(完整的和只有5帧片段的)2)与汽车运动数据集比较,输入也是5帧片段。比相同输入的实验要好,但比orb-slam(full)要差。
可解释性预测:网络学习到了识别动态物体,遮挡,和比较薄的结构,并把他们设置为mask。

可解释性遮罩
可视化结果

不足:
1)没有显式估计动态场景和遮挡,只是隐式地包含在可解释性遮罩里,直接通过动态分割对场景中的动态进行建模可能可以解决 2)假设内参是已知的,不适用于网上随便找的一段视频 3)可以扩展到学习3D物体表示


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









