



 本文介绍了一种从喜马拉雅FM网站抓取音频资源的方法,详细讲解了如何定位音频URL,解析网页源代码,以及使用Python的requests和BeautifulSoup库实现音频资源的批量下载。
本文介绍了一种从喜马拉雅FM网站抓取音频资源的方法,详细讲解了如何定位音频URL,解析网页源代码,以及使用Python的requests和BeautifulSoup库实现音频资源的批量下载。
爬虫框架的三个基本组成:获取网页,寻找信息,收集信息。 ## 分析网页获取音频资源的url 打开网页https://www.ximalaya.com/youshengshu/2684034/; 点击F12查看网页源代码。
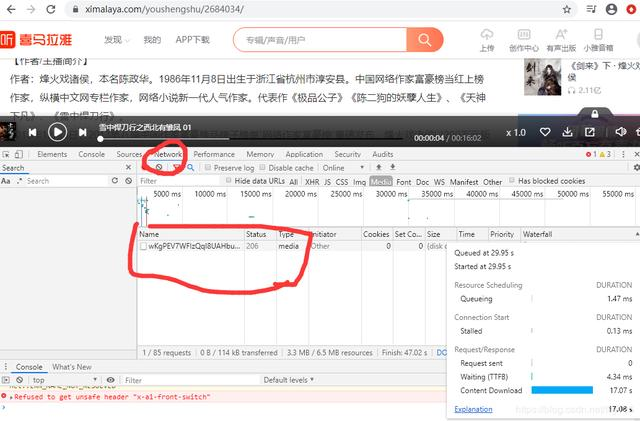
依次点击查看音频资源的url。https://aod.cos.tx.xmcdn.com/group80/M02/38/03/wKgPEV7WFIzQqI8UAHbux7JA91Y637.m4a查看网页源代码发现并没有与之相匹配的,所以真正的url被隐藏了。
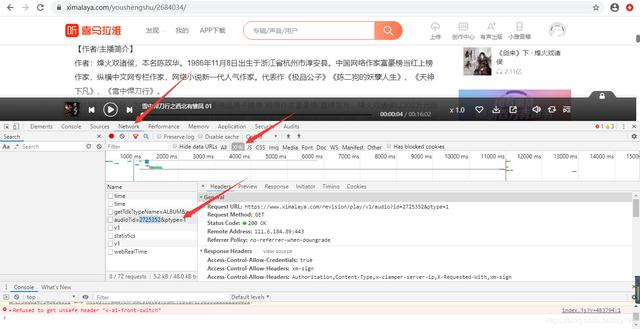
不断尝试下发现真正的资源文件在这个url下https://www.ximalaya.com/revision/play/v1/audio?id=2725352&ptype=1,以json字符串的形式存储。`# src=‘https://www.ximalaya.com/revision/play/v1/audio?id=’+str(id)+’&ptype=1’
# audiodic=getHTML(src) # src = audiodic.json()['data']['src']`
以此代码提取url。
下载资源
获取到url之后就可以下载对资源进行下载。
def getMp3(name,name2,url):
root = "E://python_resorce//" + name +"//"
# path = root + url.split('/')[-1]
path = root + name2+'.m4a'
print(root)
try:
print('kaishi1')
if not os.path.exists(root):
print('kaishi2')
os.mkdir(root)
if not os.path.exists(path):
print('kaishi3')
headers = {'User-Agent':'Unnecessary semicolonMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r=requests.get(url, headers = headers)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
因为大多数网站不许许爬虫所以对请求头部进行简单的伪装。如此就可以下载音频了,但是如果要进行批量下载,我没还需要知道网页的源代码,和我们所得到的音频资源的关系。
批量下载
https://www.ximalaya.com/revision/play/v1/audio?id=2725352&ptype=1以上述方法打开多个类似的url可以发现只有id号发生了改变,但是并不是线性变化的。
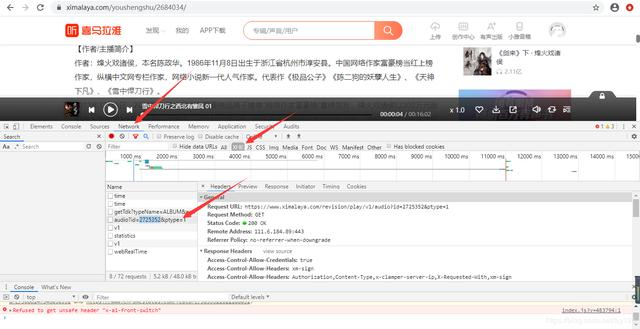
但是在网页的源码中我们是可以找到id号的。这样我们就可以对网页进行解析提取出我们需要的了
def get_M4a_Url(s):
soup = BeautifulSoup(s, "html.parser")
for link in soup.find_all(attrs={'class':'text _Vc'}):
name1=link.a.get('title')
id1=link.a.get('href').split('/')[-1]
src='https://www.ximalaya.com/revision/play/v1/audio?id='+str(id1)+'&ptype=1'
audiodic=getHTML(src)
src1 = audiodic.json()['data']['src']
my_dict={"name":name1,'id':id1,'src':src1}
list1.append(my_dict)
return list1
到这里结束,完整代码如下:
`from bs4 import BeautifulSoup
import re
import random
import requests
import os
def getHTML(url):
try:
headers = {'User-Agent':'Unnecessary semicolonMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r=requests.get(url, headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r
except:
return "产生异常"
def getMp3(name,name2,url):
root = "E://python_resorce//" + name +"//"
# path = root + url.split('/')[-1]
path = root + name2+'.m4a'
print(root)
try:
print('kaishi1')
if not os.path.exists(root):
print('kaishi2')
os.mkdir(root)
if not os.path.exists(path):
print('kaishi3')
headers = {'User-Agent':'Unnecessary semicolonMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
r=requests.get(url, headers = headers)
with open(path,'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
list1 = []
# def get_M4a_Src(id)
# src='https://www.ximalaya.com/revision/play/v1/audio?id='+str(id)+'&ptype=1'
# audiodic=getHTML(src)
# src = audiodic.json()['data']['src']
# return src
def get_M4a_Url(s):
soup = BeautifulSoup(s, "html.parser")
for link in soup.find_all(attrs={'class':'text _Vc'}):
name1=link.a.get('title')
id1=link.a.get('href').split('/')[-1]
src='https://www.ximalaya.com/revision/play/v1/audio?id='+str(id1)+'&ptype=1'
audiodic=getHTML(src)
src1 = audiodic.json()['data']['src']
my_dict={"name":name1,'id':id1,'src':src1}
list1.append(my_dict)
return list1
for i in range(1,20):
src='https://www.ximalaya.com/guangbojv/30816438/p'+str(i)
s=getHTML(src).text
get_M4a_Url(s)
for dict2 in list1:
print(dict2)
getMp3('雪中悍刀行',dict2['name'],dict2['src'])

















 2204
2204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









