







1、Java基础
1.1 面向对象OOP
1.1.1 面向对象开发特点:继承、多态、封装
多态:
-
重载:发生在同一类中,要求方法名相同,但是参数列表不同
-
重写:发生在继承关系种,遵循两同两小一大原则:两同(方法名相同,参数列表相同),两小(如果返回类型是基本类型则要完全一致,如果是对象类型则需要小于父类的返回类型;方法抛出的异常一定要小于父类抛出的异常),一大(访问权限要大于父类)
1.2 面向对象六大基本原则
-
单一职责原则:一个类只做一件事情
-
依赖倒置原则:面向接口编程,不能直接依赖类
-
接口隔离原则:接口要小而专,不能大而全
-
开闭原则:一个类对修改时关闭的,对拓展是开放的
-
里氏替换原则:一个父类能出现的地方,他的父类也能够出现
-
最小知道原则:一个实体应该尽量少的与其他实体之间发生相互作用,是的系统功能模块相对独立
1.2 接口 与 抽象类
相同点:都不能实例化对象
不同点:
-
接口里面只能包含抽象方法,而抽象类里面既能包含抽象方法,也能包含普通方法
-
一个类可以实现多个接口,而一个只能继承一个父类
-
接口强调的是功能,而抽象类强调的是继承关系
-
接口里面的变量都是
public static final修饰的变量,而抽象类里可以有普通成员变量 -
接口不能拥有构造函数,而抽象类可以有构造函数
-
从jdk1.8以后,接口可以有default默认实现方法
1.3 session 和 cookie 区别
-
存储位置:session存储在服务器端,cookie存储在浏览器端,所以相对来说,session比较安全,而cookie存在cookie欺骗的风险
-
性能:由于session存储在服务器端,相对安全的前提下也比较消耗服务器资源
-
存储容量:单个cookie保存的数据不能超过4k,很多浏览器都限制一个站点最多保存20个cookie,而对session没有太多的要求
1.4 equals 和 == 区别
-
比较对象:==既能用于对象之间的比较,也能用于基本类型之间的比较,而equals只能用于对象的比较。
-
能否重载:==不能重载,equals可以重载
-
比较内容:equals默认比较的是内存地址,而String类的equals比较的是内容。==比较的是对象的内存地址
1.5 访问修饰符
| public | protected | default | private | |
|---|---|---|---|---|
| 所有可见 | 1 | 0 | 0 | 0 |
| 子类可见 | 1 | 1 | 0 | 0 |
| 包内可见 | 1 | 1 | 1 | 0 |
| 自己可见 | 1 | 1 | 1 |
2、集合
2.1继承关系
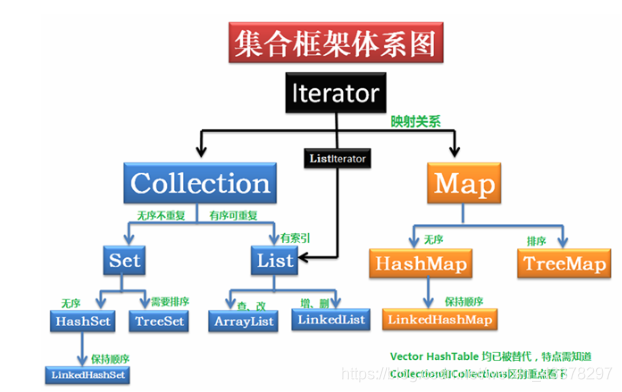
2.2 Collection
2.2.1 Set
2.2.1.1 HashSet
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
}底层使用HashMap数据结构存储,每次传入的值都是同一个Object对象
2.2.1.2 TreeSet
需要对传入的对象实现 Comparable接口,实现compare方法。或者传入比较器
2.2.2 List
2.2.2.1 ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
}底层数据结构:数组
思想:动态数组
初始化容量:10
扩容机制:扩充容量到原来的1.5倍数
存取原理:
存:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
-
看一下要不要进行扩容,1.5倍
-
存进去
2.2.2.2 LinkedList
双向链表,不能随机访问
2.3 Map
2.3.1 HashMap
-
JDK1.8以前
底层数据结构:数据+链表
默认初始化容量:16
默认加载因子:0.75
扩容规则:当我使用的容量大于 16*0.75 = 12的时候,也就是我插入第13个元素的时候,会触发扩容。扩容分为两个步骤:数组变成当前的两倍,再对里面的元素进行一个rehash的一个操作。而且使用的是一个头插法
怎么处理hash冲突:拉链地址法,因为数组的容量总是2^n,那么HashMap计算Hash值得时候,不是像我们那样使用取余得方法,而是使用位运算,相与得到数组得下标,再进行操作
不安全体现:但是HashMap是不安全的,不安全体现在我们得resize()的过程中,当有两个线程同时进行resize操作的时候,容易产生相互指向的死锁,消耗CPU内存。我们可以使用ConcurrentHashMap、HashTable、SynchronizedMap来解决这个问题
存取过程:
-
JDK1.8以后
底层数据结构:数据+链表+红黑树
默认初始化容量:16
默认加载因子:0.75
在一个链表大于8的时候,会转化成为红黑树,一红黑树结点<6的时候,会转换成为链表
存取过程:
(1)put
-
根据key计算出hashcode
-
判断是否需要进行初始化。即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
-
如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
-
如果都不满足,则利用 synchronized 锁写入数据。
-
如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
(2)get
-
根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
-
如果是红黑树那就按照树的方式获取值。
-
就不满足那就按照链表的方式遍历获取值。
主要参数:
-
存放数据的数组
-
结构体Node
-
默认初始化长度
-
最大长度 2^30
-
默认加载因子
-
modcount 修改次数
-
链表转红黑树的值、红黑树转链表的值
2.3.2 TreeMap
红黑树实现
-
每个节点要么是黑的,要么是红的
-
根节点是黑的
-
叶节点是黑的
-
如果一个节点是红的,他的两个儿子节点都是黑的
-
对于任一节点而言,其到叶节点树尾端NIL指针的每一条路径都包含相同数目的黑节点
-
插入:
新插入的结点总是设为红色的,如果父节点是黑色的,就不需要修复,只有父节点是红色节点的时候需要做修复
情况1 :当前节点的父节点是红色,且祖父节点的另一个子节点(叔叔节点)也是红色,则把当前结点的父节点和父节点的兄弟结点都变成黑色
对策 :把父节点和叔叔节点变黑,爷爷节点涂红,然后把当前节点指针给到爷爷,让爷爷节点那层继续循环,接受红黑树特性检测。
情况2: 当前节点的父节点是红的,叔叔节点是黑的,当前节点是父节点的右子树。
对策:当前节点的父节点作为新的当前节点,以新当前指点为支点左旋
情况3:当前节点的父节点是红色,叔叔节点是黑色,且当前节点是其父节点的左儿子
对策: 父节点变黑,祖父变红,以祖父节点为支点右旋
-
删除
在删除一个节点后,如果删除的节点时红色节点,那么红黑树的性质并不会被影响,此时不需要修正,如果删除的是黑色节点,原红黑树的性质就会被改变,此时我们需要做修正。
2.3.3 HashTable
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {}2.3.4 HashMap 与 HashTable
-
null值 :HashTable不允许K或V为null,HashMap允许K和V都为null
-
实现方式:HashTable继承了Dictionary,HashMap继承AbstractMap
-
初始化容量:HashTable 初始化容量为11,HashMap初始化容量为16
-
扩容机制:HashTable 当前容量 * 2+1,HashMap当前容量 * 2
-
迭代器:HashTable 安全失败,HashMap快速失败
2.4 String StringBuilder StringBuffer区别
底层原理:
-
String类为final类,表示不可继承不可修改,底层使用
final char[] value存储内容。而且String的各种方法返回的对象都是new String()返回一个新的对象。public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; } -
StringBuilder是继承自
AbstractStringBuilder,而AbstractStringBuilder底层是用char[] value来存储元素的,修改的是数组的本身 -
StringBuffer就是StringBuilder的基础之上加上了
synchronized关键字锁住,保证线程安全public final class StringBuilder extends AbstractStringBuilder implements java.io.Serializable, CharSequence {} abstract class AbstractStringBuilder implements Appendable, CharSequence { /** * The value is used for character storage. */ char[] value; }
StringBuilder StringBuffer
-
默认初始化容量为:16
-
扩容规则:当我们使用
StringBuffer对象的append(...)方法追加数据时,如果char类型数组的长度无法容纳我们追加的数据,StringBuffer就会进行扩容。扩容时会用到Arrays类中的copyOf(...)方法,每次扩容的容量大小是原来的容量的2倍加2。
3、并发
3.1 线程
3.1.1 线程状态
3.1.2 线程池
3.1.2.1 什么是线程池?
线程池是一种多线程处理形式,处理过程中将任务提交到线程池,任务的执行交由线程池来管理。
如果每个请求都创建一个线程去处理,那么服务器的资源很快就会被耗尽,使用线程池可以减少创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
3.1.2.2 创建线程池的好处
-
降低资源消耗,重复利用。创建线程是一个是非耗费资源的操作,如果我们每次都重新创建一个线程来执行一个任务的话,那么对CPU内存的损耗是十分大的。如果我事先就创建好了一个线程池,每次我要执行的时候,就去拿一个线程,那么速度和资源分配来讲,都是比较快的,是一种空间换时间的思想
-
提高管理性。可以编写线程池管理代码对池中的线程同一进行管理,比如说启动时有该程序创建100个线程,每当有请求的时候,就分配一个线程去工作,如果刚好并发有101个请求,那多出的这一个请求可以排队等候,避免因无休止的创建线程导致系统崩溃。
3.1.2.3 线程池的种类?
-
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
-
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
-
newCachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
-
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
3.1.2.4 有什么参数?
-
corePoolSize:就是线程池中的核心线程数量,这几个核心线程,只是在没有用的时候,也不会被回收
-
maximumPoolSize:就是线程池中可以容纳的最大线程的数量
-
keepAliveTime:就是线程池中除了核心线程之外的其他的最长可以保留的时间,因为在线程池中,除了核心线程即使在无任务的情况下也不能被清除,其余的都是有存活时间的,意思就是非核心线程可以保留的最长的空闲时间
-
util:就是计算这个时间的一个单位
-
workQueue:就是等待队列,任务可以储存在任务队列中等待被执行,执行的是FIFIO原则(先进先出)。
-
threadFactory:就是创建线程的线程工厂。
-
handler:是一种拒绝策略,我们可以在任务满了之后,拒绝执行某些任务。
3.1.2.5 线程池的拒绝策略
-
AbortPolicy策略:该策略会直接抛出异常,阻止系统正常工作。
-
CallerRunsPolicy 策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前的被丢弃的任务。
-
DiscardOleddestPolicy策略: 该策略将丢弃最老的一个请求,也就是即将被执行的任务,并尝试再次提交当前任务。
-
DiscardPolicy策略:该策略默默的丢弃无法处理的任务,不予任何处理。
3.1.2.6 execute和submit的区别?
execute适用于不需要关注返回值的场景,只需要将线程丢到线程池中去执行就可以了。
submit方法适用于需要关注返回值的场景
3.1.2.7 线程池都有哪几种工作队列?
-
ArrayBlockingQueue 是一个基于数组结构的有界阻塞队列,此队列按 FIFO(先进先出)原则对元素进行排序
-
LinkedBlockingQueue 一个基于链表结构的阻塞队列,此队列按FIFO (先进先出) 排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列
-
SynchronousQueue 一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
-
PriorityBlockingQueue 一个具有优先级的无限阻塞队列
3.1.3 创建线程的三种方式
-
继承Thread类
public class Main { /** * * @param args */ public static void main(String[] args) { MyThread m = new MyThread(); m.start(); } static class MyThread extends Thread { @Override public void run() { System.out.println("1"); } } } -
实现runnable接口
public class Main { /** * * @param args */ public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { System.out.println("1"); } }).start(); } } -
通过Callable和Future创建线程
3.1.4 线程同步方法
-
wait():使一个线程处于等待状态,并且释放所持有的对象的lock。让出CPU进入等待队列
-
sleep():使一个正在运行的线程处于睡眠状态,是一个静态方法,调用此方法要捕捉InterruptedException异常。占着茅坑不拉屎,不让出CPU
-
notify():唤醒一个处于等待状态的线程,注意的是在调用此方法的时候,并不能确切的唤醒某一个等待状态的线程,而是由JVM确定唤醒哪个线程,而且不是按优先级。
-
notityAll():唤醒所有处入等待状态的线程,注意并不是给所有唤醒线程一个对象的锁,而是让它们竞争。
3.1.5 sleep和wait比较
-
sleep()方法是Thread的静态方法,而wait是Object实例方法
-
wait()方法必须要在同步方法或者同步块中调用,也就是必须已经获得对象锁。而sleep()方法没有这个限制可以在任何地方种使用。另外,wait()方法会释放占有的对象锁,使得该线程进入等待池中,等待下一次获取资源。而sleep()方法只是会让出CPU并不会释放掉对象锁;
-
sleep()方法在休眠时间达到后如果再次获得CPU时间片就会继续执行,而wait()方法必须等待Object.notift/Object.notifyAll通知后,才会离开等待池,并且再次获得CPU时间片才会继续执行。
3.2 锁
3.2.1 synchronized
底层原理:
如果锁的是代码块,你那么进入的是monitorenter,退出锁是monitorexit,但是我们看21行还有一个monitorexit,是因为如果在抛出异常过后,也是进行monitorexit的,所以早期的synchronized就是通过这两种方式实现的锁,两个指令的执行是JVM通过调用操作系统的互斥量mutex来实现,被阻塞的线程会被挂起、等待重新调度,会导致“用户态和内核态”两个态之间来回切换,对性能有较大影响。
synchronized用的就是monitor机制,常常也被称作为管程,而monitor机制底层其实用的就是Unsafe的CAS操作,就是谁先进入同步代码块,谁就更改标志位当前线程,monitor机制是通过操作系统的互斥量mutex来实现的
锁升级过程:
-
在代码即将进入同步块的时候,如果此同步对象没有被锁定(锁标志位为“01”状态),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝
-
然后,虚拟机将使用CAS操作尝试把对象的Mark Word更新为指向Lock Record的指针。如果这个更新动作成功了,即代表该线程拥有了这个对象的锁,并且对象Mark Word的锁标志位(Mark Word的最后两个比特)将转变为“00”,表示此对象处于轻量级锁定状态
-
如果这个更新操作失败了,那就意味着至少存在一条线程与当前线程竞争获取该对象的锁。虚拟机首先会检查对象的Mark Word是否指向当前线程的栈帧,如果是,说明当前线程已经拥有了这个对象的锁,那直接进入同步块继续执行就可以了,否则就说明这个锁对象已经被其他线程抢占了。如果出现两条以上的线程争用同一个锁的情况,那轻量级锁就不再有效,必须要膨胀为重量级锁,锁标志的状态值变为“10”,此时Mark Word中存储的就是指向重量级锁(互斥量)的指针,后面等待锁的线程也必须进入阻塞状态。
-
当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位设置为“01”、把偏向模式设置为“1”,表示进入偏向模式。同时使用CAS操作把获取到这个锁的线程的ID记录在对象的Mark Word之中。如果CAS操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,虚拟机都可以不再进行任何同步操作
-
一旦出现另外一个线程去尝试获取这个锁的情况,偏向模式就马上宣告结束。根据锁对象目前是否处于被锁定的状态决定是否撤销偏向(偏向模式设置为“0”),撤销后标志位恢复到未锁定(标志位为“01”)或轻量级锁定(标志位为“00”)的状态,后续的同步操作就按照上面介绍的轻量级锁那样去执行
3.2.2 lock
public class ReentrantLock implements Lock, java.io.Serializable {
private static final long serialVersionUID = 7373984872572414699L;
/** Synchronizer providing all implementation mechanics */
private final Sync sync;
/**
* Base of synchronization control for this lock. Subclassed
* into fair and nonfair versions below. Uses AQS state to
* represent the number of holds on the lock.
*/
abstract static class Sync extends AbstractQueuedSynchronizer {}
}
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
private volatile int state;
}
ReentrantLock是通过 AbstractQueuedSynchronizer实现的
AQS使用一个FIFO的队列表示排队等待锁的线程,队列头节点称作“哨兵节点”或者“哑节点”,它不与任何线程关联。其他的节点与等待线程关联,每个节点维护一个等待状态waitStatus。如图
AQS中还有一个表示状态的字段state,例如ReentrantLocky用它表示线程重入锁的次数
lock()
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
首先用一个CAS操作,判断state是否是0(表示当前锁未被占用),如果是0则把它置为1,并且设置当前线程为该锁的独占线程,表示获取锁成功。当多个线程同时尝试占用同一个锁时,CAS操作只能保证一个线程操作成功,剩下的只能乖乖的去排队啦。
“非公平”即体现在这里,如果占用锁的线程刚释放锁,state置为0,而排队等待锁的线程还未唤醒时,新来的线程就直接抢占了该锁,那么就“插队”了。
若当前有三个线程去竞争锁,假设线程A的CAS操作成功了,拿到了锁开开心心的返回了,那么线程B和C则设置state失败,走到了else里面。我们往下看acquire。
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
final boolean nonfairTryAcquire(int acquires) {
//获取当前线程
final Thread current = Thread.currentThread();
//获取state变量值
int c = getState();
if (c == 0) { //没有线程占用锁
if (compareAndSetState(0, acquires)) {
//占用锁成功,设置独占线程为当前线程
setExclusiveOwnerThread(current);
return true;
}
} else if (current == getExclusiveOwnerThread()) { //当前线程已经占用该锁
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
// 更新state值为新的重入次数
setState(nextc);
return true;
}
//获取锁失败
return false;
}
/**
* 将新节点和当前线程关联并且入队列
* @param mode 独占/共享
* @return 新节点
*/
private Node addWaiter(Node mode) {
//初始化节点,设置关联线程和模式(独占 or 共享)
Node node = new Node(Thread.currentThread(), mode);
// 获取尾节点引用
Node pred = tail;
// 尾节点不为空,说明队列已经初始化过
if (pred != null) {
node.prev = pred;
// 设置新节点为尾节点
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 尾节点为空,说明队列还未初始化,需要初始化head节点并入队新节点
enq(node);
return node;
}
非公平锁tryAcquire的流程是:检查state字段,若为0,表示锁未被占用,那么尝试占用,若不为0,检查当前锁是否被自己占用,若被自己占用,则更新state字段,表示重入锁的次数。如果以上两点都没有成功,则获取锁失败,返回false。
入队。由于上文中提到线程A已经占用了锁,所以B和C执行tryAcquire失败,并且入等待队列。如果线程A拿着锁死死不放,那么B和C就会被挂起。
B、C线程同时尝试入队列,由于队列尚未初始化,tail==null,故至少会有一个线程会走到enq(node)。我们假设同时走到了enq(node)里。
/**
* 初始化队列并且入队新节点
*/
private Node enq(final Node node) {
//开始自旋
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
// 如果tail为空,则新建一个head节点,并且tail指向head
if (compareAndSetHead(new Node()))
tail = head;
} else {
node.prev = t;
// tail不为空,将新节点入队
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
这里体现了经典的自旋+CAS组合来实现非阻塞的原子操作。由于compareAndSetHead的实现使用了unsafe类提供的CAS操作,所以只有一个线程会创建head节点成功。假设线程B成功,之后B、C开始第二轮循环,此时tail已经不为空,两个线程都走到else里面。假设B线程compareAndSetTail成功,那么B就可以返回了,C由于入队失败还需要第三轮循环。最终所有线程都可以成功入队。
B和C相继执行acquireQueued(final Node node, int arg)。这个方法让已经入队的线程尝试获取锁,若失败则会被挂起。
/**
* 已经入队的线程尝试获取锁
*/
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true; //标记是否成功获取锁
try {
boolean interrupted = false; //标记线程是否被中断过
for (;;) {
final Node p = node.predecessor(); //获取前驱节点
//如果前驱是head,即该结点已成老二,那么便有资格去尝试获取锁
if (p == head && tryAcquire(arg)) {
setHead(node); // 获取成功,将当前节点设置为head节点
p.next = null; // 原head节点出队,在某个时间点被GC回收
failed = false; //获取成功
return interrupted; //返回是否被中断过
}
// 判断获取失败后是否可以挂起,若可以则挂起
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
// 线程若被中断,设置interrupted为true
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
unlock()
public void unlock() {
sync.release(1);
}
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
/**
* 释放当前线程占用的锁
* @param releases
* @return 是否释放成功
*/
protected final boolean tryRelease(int releases) {
// 计算释放后state值
int c = getState() - releases;
// 如果不是当前线程占用锁,那么抛出异常
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
// 锁被重入次数为0,表示释放成功
free = true;
// 清空独占线程
setExclusiveOwnerThread(null);
}
// 更新state值
setState(c);
return free;
}
流程大致为先尝试释放锁,若释放成功,那么查看头结点的状态是否为SIGNAL,如果是则唤醒头结点的下个节点关联的线程,如果释放失败那么返回false表示解锁失败
ryRelease的过程为:当前释放锁的线程若不持有锁,则抛出异常。若持有锁,计算释放后的state值是否为0,若为0表示锁已经被成功释放,并且则清空独占线程,最后更新state值,返回free。 v
4、IO
流的特性
-
先进先出:最先写入输出流的数据最先被输入流读取到。
-
顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(
RandomAccessFile除外) -
只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
分类
-
按数据流的方向:输入流、输出流
-
按处理数据单位:字节流、字符流
-
按功能:节点流、处理流
字节流与字符流的区别
-
字节流单次读取8位字节,字符流单次读取16位
-
字节流能处理一切文件类型,字符流只能处理txt文本
-
字节流本身不带缓冲区,字符流本身带有缓冲区,缓冲区容量为1024
IO模型介绍
-
阻塞IO模型 最常用的IO模型,所有文件操作都是阻塞的
-
非阻塞IO模型
-
IO复用模型
-
型号驱动IO模型
-
异步IO
BIO NIO AIO

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









