



 本文探讨了将深度残差网络(ResNet)转换为脉冲神经网络(S-ResNet)的挑战。提出了一个捷径转换模型来估算ReLU激活函数以匹配SNN的发放率,并引入补偿机制减少离散化误差。通过归一化权重和补偿传播误差,使得ResNet的激活函数与S-ResNet的发放率范围相匹配。转换过程涉及ReLU层替换为IF神经元,权重和偏置的调整,以及误差的迭代递归校正。
本文探讨了将深度残差网络(ResNet)转换为脉冲神经网络(S-ResNet)的挑战。提出了一个捷径转换模型来估算ReLU激活函数以匹配SNN的发放率,并引入补偿机制减少离散化误差。通过归一化权重和补偿传播误差,使得ResNet的激活函数与S-ResNet的发放率范围相匹配。转换过程涉及ReLU层替换为IF神经元,权重和偏置的调整,以及误差的迭代递归校正。
**摘要:**对于SNN来说,训练深层SNN仍然是一个巨大的挑战,而ResNet是一个先进的卷积神经网络可以训练深层的神经网络。所以就产生了将卷积的深度残差网络转换到脉冲版本的念头。将一个被训练的ResNet变成一个脉冲神经元网络——S-ResNet。我们提出了一个捷径转换模型去大致的估量持续值的激活函数去匹配脉冲神经网络中的发放率,和一个补偿的机制去减少因为离散化造成的误差。
相关工作
因为SNN这样的系统随着事件到达异步更新,因此减少操作数被要求在每一个时间步骤。
现在如何去训练一个脉冲神经网络仍然是一个公开的挑战因为它的脉冲机制的不连续性。很多努力已经被做去解决这个问题。这些方法可以分成4类:
1、梯度下降的算法:这个方法致力于克服snn的非线性并且应用梯度下降优化算法。早期的工作有SpikeProp,实现了SNN的BP算法,通过认为电势函数是可微的在方法时间周围的很小的邻域内。和BP很相似的方法,tempotron学习规则源于被细胞膜电势和发放时间所定义的一个损失函数,还有个SGD
2、突触可塑性规则的学习,比如STDP。STDP已经被证明了可以能够选择视觉的特征以一种无监督的行为。横向抑制和体内平衡被占有。
3、统计的算法,证据证明了神经网络在大脑中似乎是个随机的机制。噪音和不确定性被视为是有益的因素去促进在snn中的统计的学习和自我组织。一个SNN已经被展示可以表现贝叶斯推理,与这个建议一致的是贝叶斯推理是流行的在识别行为中。
4、转换方法。转换的研究,一个预训练的人工神经网络到它的等价的脉冲神经网络。获得脉冲神经网络的权重通过按比例衡量它的CNN副本的权重与LIF神经元的参数一致。
一种转换算法建立ANN和SNN之间的映射通过瞎搞激活函数/人工神经元去估计脉冲神经元的平均发放率。
另外种类的转换算法利用了ReLU激活函数非线性的优点去估计平均发放率。
建立一个S-ResNet
就像我上一篇博客所说的,残差网络(ResNet)中的block,如下图,F(x)=H(x)-x,H(x)是被渴望的潜在映射。
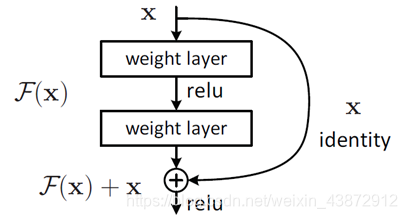
首先ANN和SNN的区别在于:ANN接受它的前层神经元的真实值的输入,而SNN接受的是前层神经元的脉冲。此外,ANN处理信息通过应用对输入和进行激活函数,而SNN中的神经元处理信息通过整合即将到来的脉冲。每一个即将到来的脉冲都会引起对一个神经元的突触后电势引起改变。
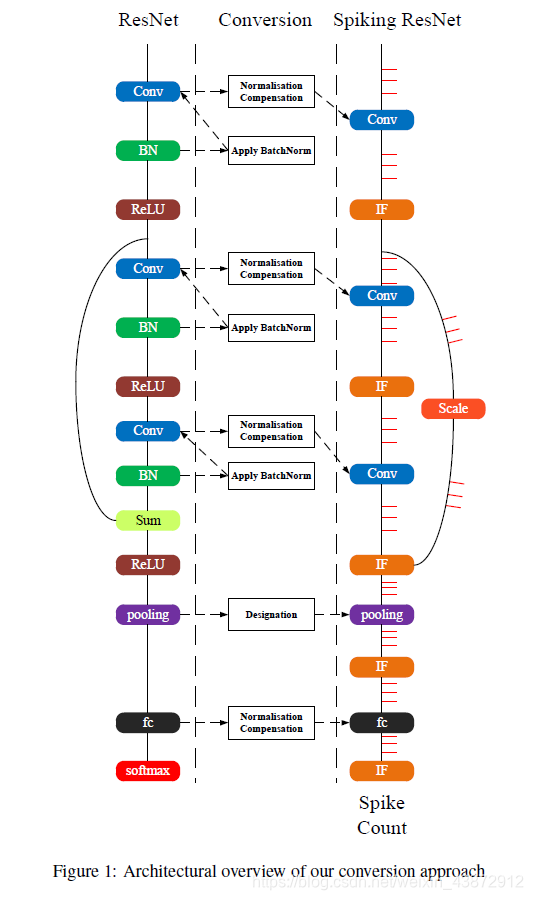
他们网络的结构
可以看到 激活函数-ReLU层被替换成了IF神经元。求和层也不在需要因为IF神经元自带求和效果(脉冲的整合)。卷积层被替换成一层突触连接似乎是卷积操作。卷积层的权重被映射到相应的突触层和偏置被看成是常数电流被输入到神经元中。相似的池化层和全连接也被类似的其他操作的突触所替换。平均池化层,突触权重被固定在1/poolsize^2。最大池化层,我们用逻辑比较只从最高发放率的神经元中去选择脉冲并且抑制其他即将到来的脉冲通过设置权重为0。一个IF神经元的额外层被添加在池化层或者全连接层之后去从哪些种类的突触连接中整合脉冲。因为权重在转换之前已经被训练好了,批柜子华就可以直接被应用去塑造在批归一化之前的卷积层。在卷积层中的权重和偏置被按比例缩放到
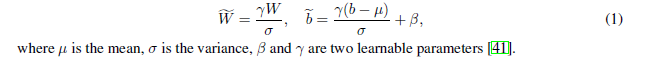
ANN的激活函数随着我们在训练中用ReLU函数肯定是正实数。同时脉冲神经元的发放率被固定在0到rmax之间,在单个时间步骤之内只能发放一个脉冲。
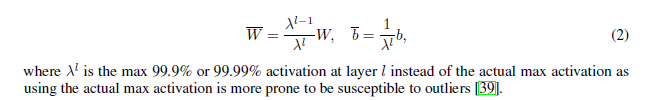
3.2ResNet的转换模型
ResNet的拓扑结构是一个直接的非循环的图,这使归一化方法在前面的内容中不兼容。虽然原始的权重在捷径中被设置为1去表现identity mapping,那些在卷积突触里的权重也应该被归一化,否则,如果我们只归一化堆栈层,脉冲神经元的发放率显著地将会从他们相应的激活函数中脱离。
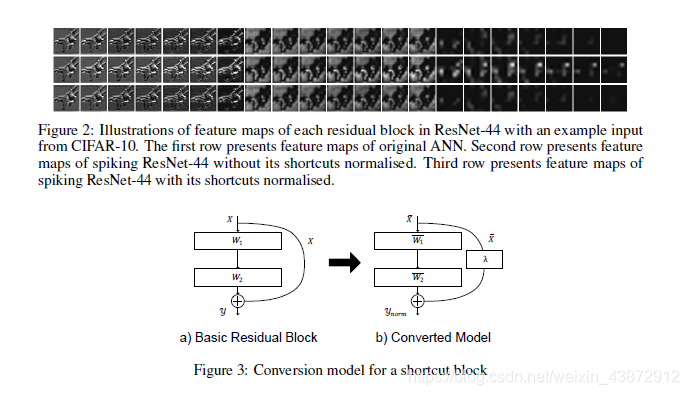
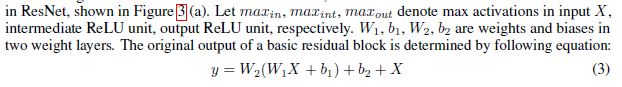
让ResNet的激活函数匹配S-ResNet的发放率范围,而脉冲神经元不被允许在一个时间步长里发放多次脉冲,因为攘夷使高活化作用的值被丢失。对于堆栈层,权重和偏置在每一层都会被归一化。
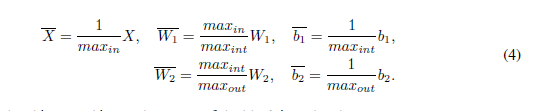
块的输出更新公式
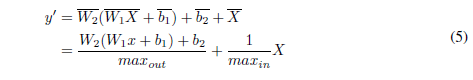
输出的归一化

比较公式5和6,我们发现5中的最后一项,捷径权重应该被限制在一个因素x,x=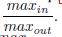 捷径中的突触权重应该被限制在
捷径中的突触权重应该被限制在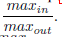
3.3传播误差的补偿
这个转换方法基于人工神经元和脉冲神经元1对1通信的基础上:ReLU的归一化活化作用被脉冲神经元的发放率所估计,
ANN,它的ReLU活化作用被计算为:
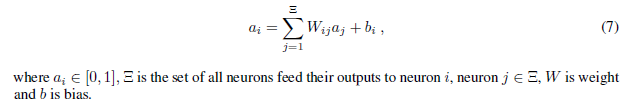
转换之后,人工神经元的权重和偏置直接映射到通过减法重置它的细胞膜电势的IF神经元,如果脉冲之间的时间间隔比不应期更大,神经元i从开始仿真到时间t已经发放的脉冲数满足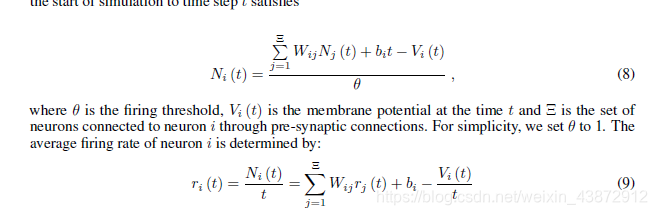
7和9的不同,ReLU激活函数的估计招致每个神经元最后一项的一定的偏差在9中。在这里我们定义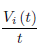 为传播误差
为传播误差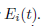
去明显地决定ReLU激活函数和发放率之间的关系,我们迭代地递归每一个突触前神经元的发放率:

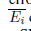 表示所有累计的传播误差的集合。如果一个SNN被组成用前馈层的堆栈暗示增长随
表示所有累计的传播误差的集合。如果一个SNN被组成用前馈层的堆栈暗示增长随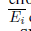 着网络变深。
着网络变深。

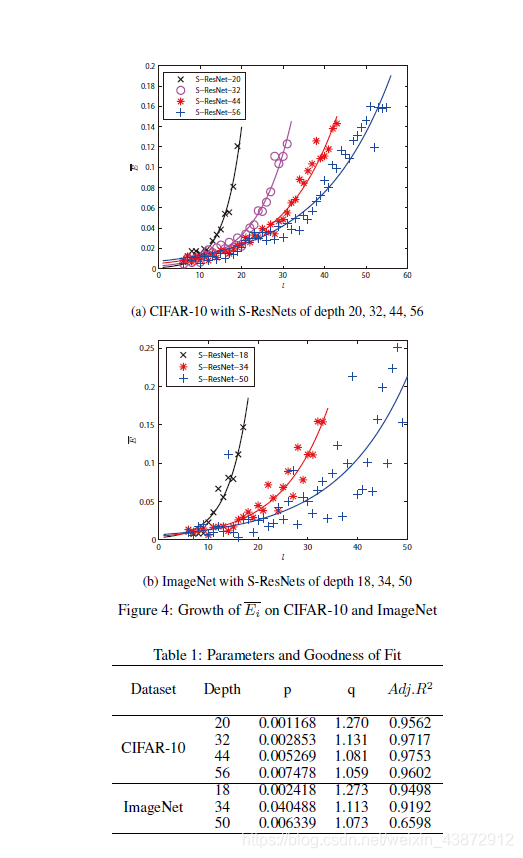
直觉上,我们应该把发放率变大去匹配ReLU激活函数,如果我们知道实际上完全数量上的传播误差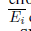 然而这很难。
然而这很难。
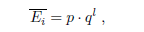 l是层数。p和q是两个常数。
l是层数。p和q是两个常数。


















 641
641




 到【灌水乐园】发言
到【灌水乐园】发言







