







 提出一种基于控制流图和TF-IDF的恶意软件家族分类方法。该方法利用图神经网络提取恶意软件的结构特征,结合指令序列信息进行高效分类。
提出一种基于控制流图和TF-IDF的恶意软件家族分类方法。该方法利用图神经网络提取恶意软件的结构特征,结合指令序列信息进行高效分类。
摘要
恶意软件家族的分类是基于恶意软件家族内部的相似性,包括程序结构和内容的相似性。由于控制流图属于非欧几里得结构化数据,之前很难直接利用从其数据和结构中提取的特征进行分类。然而,随着图神经网络的提出,非欧几里得图的分类成为可能。提出了一种基于控制流图和词频-逆文档频率的恶意软件族分类系统。该系统将控制流图分支结构和基本块中的指令序列均作为输入,通过图神经网络生成恶意软件族的图特征表示。在BIG2015数据集上的实验结果表明,保留图结构的特征数据可以有效提高族分类的效果。并且通过基于TF-IDF的指令特性也可以提高效果。
一、引言
恶意软件,是指通过网络、便携式存储设备或其他设备传播的软件。它们通常会引起意想不到的故障和信息安全问题,如隐私或机密信息泄露、系统破坏等。它们分为病毒、蠕虫、特洛伊木马、勒索软件、间谍软件等。
近年来,伴随着信息社会的快速发展,终端和设备大规模增长。经常需要将大量相同或相似的设备和生产环境连接到同一个域。类似的环境使其成为恶意软件的重要攻击目标。一种类型的恶意软件也能造成难以想象的损害。域内设备一旦受到攻击,恶意软件被植入,往往会造成该域内网络上恶意软件的迅速传播,造成无法挽回的损失。这对于在业务上严重依赖该设备的公司和个人来说尤其致命。CNCERT发布的《2020年上半年互联网网络安全数据分析报告》数据显示,共捕获计算机恶意程序样本约1815万个,日均传播次数超过483万次,涉及计算机恶意程序族1.1万多个。
这种增长趋势源于恶意软件的开发方式。相比于从利用漏洞到执行功能代码的完整恶意软件开发的高难度和高成本,一方面,恶意软件的开发更多地基于现有的功能代码模块或泄露的恶意软件源代码,如2021年6月中旬泄露的。net版天堂勒索软件源代码,大大降低了开发的时间成本和难度。另一方面,某个原型通过加密或突变发展出若干变体,以便在实体之间传播。基于以上两点所带来的推导,针对恶意软件家族相似性的多项研究正在进行中[10,13,15]。
恶意软件二进制程序分析根据分析过程中目标程序是否被执行分为动态分析和静态分析。动态分析可以在适当的激励条件下直接提取程序的核心代码指令流,也可以通过模糊的方法通过大量的尝试提取部分分支信息。与动态分析相比,静态分析可以获得更全面的程序信息。静态分析的一种常用方法是通过反汇编或反编译生成汇编代码或高级代码。这种方法在原理上相对简单,但更容易受到包装或其他方法的影响,导致拆装过于复杂,甚至无法得到正确的结果。因此,在进一步分析之前,有必要对程序进行解压和反汇编。
基于以上两种方法的处理结果可用于分析恶意软件的程序结构,包括基于控制流图[2]、基于函数调用图[5,15]、基于程序执行序列[11,12,16]的方法。控制流图信息最多,主要包含两部分信息:控制流图结构信息和装配指令序列信息。Han, Kyoung Soo和Kang, Boojoong和Im, Eul Gyu提出了在恶意软件识别中使用组装指令的频率信息的方法[3,14]。Jiang在Android平台[4]上提出了一种基于汇编指令序列的恶意软件分类方法。Li Yu等人提出了一种以操作码序列为样本特征[8]生成特征图像的方法。上述研究证明了汇编指令序列在恶意软件族分类中的作用。
因此设计了一种基于控制流图生成的方法,使用TF-IDF组合基本块中的组装操作码序列和频率信息。基于指令频率计算指令权重,以表示汇编指令。基本块表示从指令序列生成,并格式化为固定大小的向量。控制流图的结构信息用稀疏矩阵表示。结合节点特征和结构信息后,将图数据输入图神经网络,对恶意软件家族进行分类。
二、系统概述
在本节中,将介绍三个主要模块的主要结构和实现。主要流程如图1所示,包括控制流图生成模块、基本块特征生成模块、基于图神经网络的图分类模块。控制流图生成模块提取反汇编代码中的标签和汇编语句,根据跳转语句和分支语句构造邻接矩阵和基本块节点。基本块特征生成模块通过TF-IDF按类型计算训练集的词频权重,并以此为基础生成特征。基于gnn的图分类模块使用节点特征对齐后包含相邻边的有向图数据训练模型并返回族分类结果。
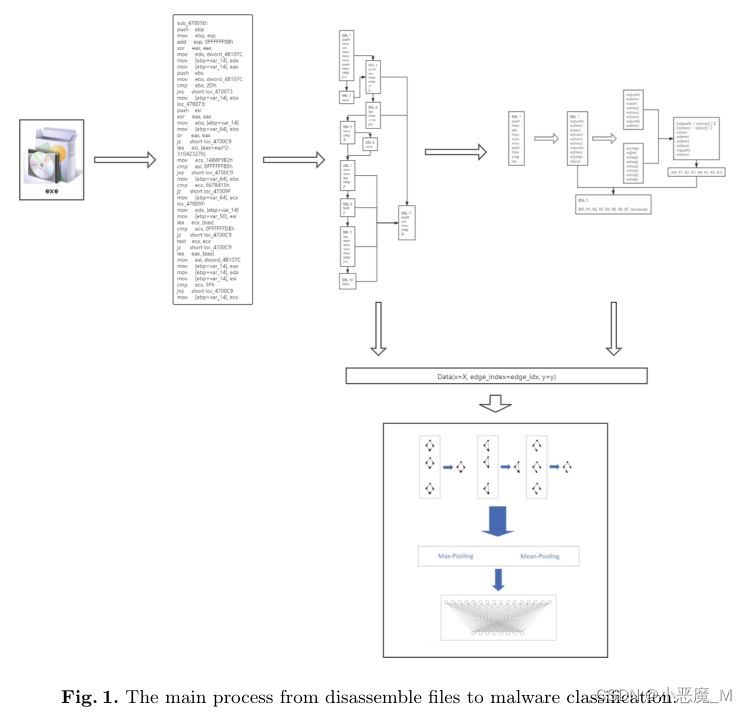
2.1控制流程图的制定
程序的控制流图由基本块和跳转关系组成。对于恶意软件,我们使用有向图G = (V, E)来表示其控制流图,其中顶点表示基本块,有向边表示跳转关系。每个基本块由几个程序集语句组成,这些语句在没有其他分支语句的情况下按顺序执行。基本块的最后一条语句通常是一个分支或跳转语句。分支指令,如jz,不仅可以继续执行汇编指令,还可以跳转到标签执行,而jmp指令只包含跳转。分支和跳转操作指令和操作数的标签可以用来描述基本块之间的邻接关系。由于没有对操作数进行上下文分析,无法确定跳转操作的条件,因此构造的控制流图中边的权值是相同的。
根据对数据集中部分拆装样本的分析,由于PE头被移除、动态链接库调用、拆装失败等原因,导致部分跳转无法确定对应的基本块内容。因此在图的邻接矩阵中只记录基本块标签和控制流,语句用NOP填充。
2.2基于TF-IDF的节点特征
据统计,该数据集包含了大约650条不同的操作指令,包括基本指令、浮点指令以及其他一些指令扩展,如SIMD和SSE扩展指令集。由于数据集包含了大约650种装配指令,有一种方案是根据装配指令的功能对其进行分类,并根据类型分配特征,但对于一些功能较复杂的指令,很难将其归类为一种类型。
一些指令具有相似的功能,并且有接近的比例发生。有些指令的功能不同,它们出现的位置比较近,出现的频率在规模上也比较接近。考虑到这些指令对的特征应该是接近的,在将容易分类的指令组合在一起后,以频率作为定义指令特征的基础。
频率的使用方法有两种,一种是基于频率设计每条指令的特征,另一种是基于倒数频率设计命令的特征。由于两个原因,后者不能用作特性。一方面,高频指令具有尺度接近的特点,另一方面,极低频指令分布所引起的偶然性。除此之外,操作指令的频率与恶意软件家族有关。考虑到相同频率的指令在不同类别中的分布也需要区分,引入TF-IDF(Term frequency - inverse Document frequency,一种信息检索和数据挖掘中常用的加权技术)来调整指令只在特定类别中出现的特征。
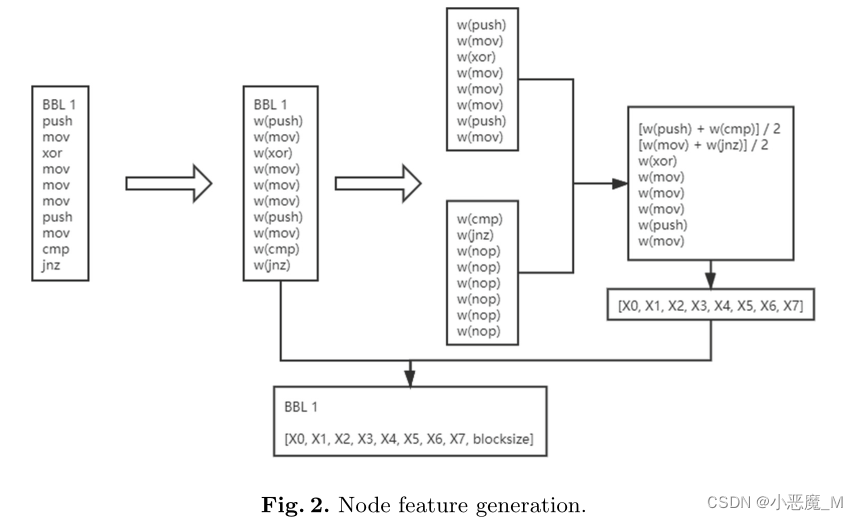
在使用训练集中的指令根据恶意软件族生成词频矩阵,并计算idf值后,导入样本的词频来计算TF-IDF值,作为该指令在样本中的特征。图中的节点特征应该具有统一的大小。控制流图中的节点是基本块,基本块中包含的指令数量是可变的。因此,需要对基本块的数据特征进行压缩。如图2所示,将矩阵按具体尺寸切片并计算平均值,并添加基本块大小作为基本块的特征值。
2.3分类模型
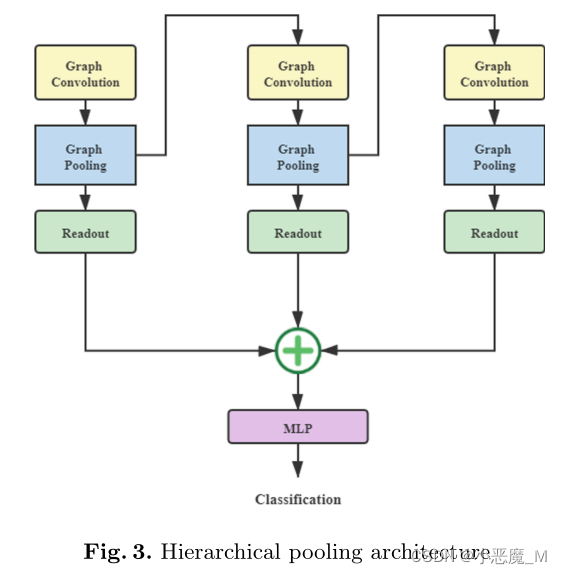
卷积神经网络已经成功地利用了欧氏域格式化数据的特性。为了处理图等非欧几里得数据结构,提出了图神经网络从图[17]中提取结构特征。在本文中,我们使用了如图3所示的分层池架构,该架构由Junhyun Lee, Inyeop Lee, jae - woo Kang[1,7]实现。

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









