







恶意软件分类中对抗性示例和防御的有效性
目录
4.2特征启用和禁用(Feature enabling and disabling)
4.3带舍入和位上升的FGSM(FGSM with rounding and Bit ascending)
5.4随机特征无效(Random Feature Nullification)
摘要
人工神经网络已经成功地用于许多不同的分类任务,包括恶意软件检测和区分恶意和非恶意程序。虽然人工神经网络在这些任务上表现得很好,但它们也容易受到敌对例子的攻击。一个对抗性示例是,对样本进行了微小修改,使神经网络对其进行错误分类。人们提出了许多技术,既可以用来制作对抗性示例,也可以用来强化针对它们的神经网络。以前的大多数工作都是在图像领域完成的。其中一些攻击已被用于恶意软件领域,该领域通常处理二进制特征向量。为了更好地理解恶意软件分类中对抗性示例的空间,我们研究了恶意软件领域中制作对抗性示例的不同方法和防御技术,并比较了它们在多个数据集上的有效性。
关键词:对抗式机器学习,恶意软件检测,安卓
一、介绍
- 神经网络的一个问题是,它们容易受到干扰输入数据而产生的对抗性示例的攻击。
- 本文研究了神经网络在恶意软件分类中的应用。我们关注近年来提出的一系列恶意软件攻击和防御,概述了这些算法,并以一致的方法比较了它们的有效性。
- 在本文中,我们比较了12种攻击,它们对不设防模型的有效性,以及四种防御方案的影响。
- 我们的结果表明,除了对抗性训练,所有防御在恶意软件上的表现都比在图像上差。
二、背景
2.1威胁模型(threat model)
Threat model 威胁模型是指一种方法所考虑的潜在攻击的类型,例如黑盒攻击。
在恶意软件检测设置中,系统的目标是准确区分恶意软件和非恶意软件。本例中的攻击者是恶意程序的作者,他们的目标是逃避恶意软件检测系统的检测。为了躲避检测系统,攻击者有两种选择。
- 第一种选择是“破坏”分类器,使其变得不可信;
- 第二种方法是修改他们的软件,使分类器将其视为良性的。
虽然神经网络为恶意软件检测带来了优势,但它们的使用使系统容易受到攻击,这些攻击通常可以用来对付神经网络。如果攻击者可以错误标记训练数据中的实例,则称为数据中毒攻击。数据中毒的目标是通过对错误标记的数据进行训练来规避分类器。
已经证明,在一个模型上创建的对抗性示例也可以用于攻击另一个模型,只要模型已经学习到足够相似的决策边界。因此,本文中的攻击都是白盒攻击。
2.2对抗性示例
对抗性示例——即非常接近合法实例但分类不同的实例。给出一个类标签为C(x)=t 的实例x,我们可以找到一个实例x′,这样C(x′)t。另一个约束是一些距离度量| | x−x′| |应该保持小。这意味着对合法样本所做的更改应该尽可能小。在图像中,这通常意味着人类不可能用肉眼感知x和x′之间的变化。
三、实验
3.1数据
- 使用Android应用程序的Drebin数据集——它包含恶意软件和良性类的提取特征。此外,它还包含5560个恶意软件应用程序本身,Drebin依赖于静态特征。
- 还对另一个数据集APDS进行了实验——其中包括从android应用程序中提取的权限。它包含398个实例和330个特征。50%的样本是恶意软件,50%是良性的。
3.2受害者模型(the victim model)
对抗攻击指的是对目标机器学习模型的原输入施加轻微扰动以生成对抗样本来欺骗目标模型(亦称为受害模型,Victim Model)的过程。
为了测试不同攻击和防御的性能,我们定义了一个受害者模型。
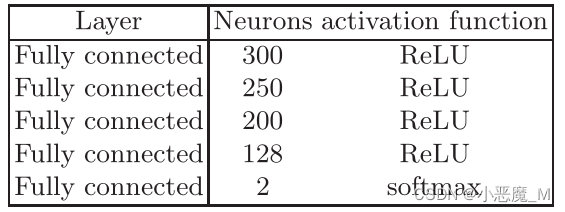
- 我们使用的模型由四个完全连接的隐藏层组成,以校正线性单元(ReLU)作为激活函数。受害者模型的架构见表2。由于输入层依赖于数据集,因此省略了输入层。
- 我们使用Adam优化器对模型进行了100次迭代训练,学习率为.001,β1=. 9,β2=. 999。作为损失函数,使用了二进制交叉熵。
- 受害者模型的性能见表1。在我们所有的训练中,我们使用56.25%的数据作为训练数据,18.75%作为验证数据,25%作为测试数据。
表1:测试集上受害者模型的准确度(acc)。还有假阴性率(FNR)、假阳性率(FPR)、真阳性率(FPR)和真阴性率(TNR)
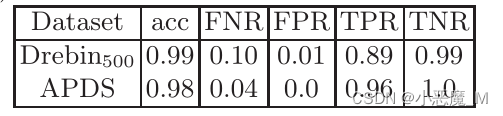
表2:受害者模型的体系结构
3.3.特征选择
Grosse等人发现,只有少数特征用于创建对抗性示例。为了测试更复杂的模型而不出现内存问题,我们对受害者模型(表2)进行了特征选择。我们使用scikit-learn实现SelectKBest,以卡方检验(chi-squared)作为评分函数,并针对不同的K值运行特征选择。在整篇论文中,当我们想要指出我们使用了特征选择时,我们将指出我们使用的特征K的数量,如下所示:
四、攻击(attacks)
4.1JSMA
Grosse等人采用了基于雅可比显著图(JSMA)开发的图像处理方法。雅可比矩阵是输出类样本的每个特征的前向导数矩阵。创建对抗性示例包括两个步骤。
- 首先计算雅可比矩阵。
- 在第二步中,选择并保持朝向所需输出类别具有最大正梯度的特征。
计算雅可比矩阵和改变特征的步骤重复多次,直到达到最大允许扰动次数或实现错误分类。
结果
JMSA攻击对我们训练的受害者模型有效(表3),逃逸率因数据集而异。然而在APDS上逃逸率可以达到100%,在Drebin500上逃逸率为33%。变更栏给出了所有对抗性示例的平均变更。
表3:Grosse等人基于JSMA的方法,最大允许扰动为25。

【补充】JSMA原理
引自:(26条消息) 对抗样本生成算法之JSMA算法_学-evday的博客-优快云博客_jsma攻击
背景
之前的对抗样本的扰动方向都是损失函数的梯度方向,该论文生成的对抗样本的扰动方向是目标类别标记的预测值的梯度方向,作者将这个梯度称为前向梯度(forward derivative),即

显然,前向梯度是由神经网络的目标类别输出值对于每一个像素的偏导数组成的。这意味着,我们可以通过检查每一个像素值对于输出的扰动,选择最合适的像素来进行改变。
论文提出的JSMA算法,研究的是输入扰动对输出结果的影响来找到相应的对抗扰动。作者引入了显著图的概念,该概念来自于计算机视觉领域。
显著图:表示不同的输入特征对分类结果的影响程度。若发现某些特征对应分类器中某个特定输出,可通过在输入样本中增强或减弱这些特征来使分类器产生指定输出。
算法的原理和步骤
具体步骤如下:
1、计算前向导数
计算DNN 最后一层的每个输出对输入的偏导,标识了每个输入特征对每个输出分类的影响程度。(导数的计算与反向传播类似)

2、构建对抗显著图
分类器对于一个输入x 的分类规则为

假设分类器将x 分为j ,我们希望分为t ,即
![]()
构建对抗显著图:

从而计算得到哪些像素位置的改变对目标分类t 的影响最大。若对应位置导数值为正值,则增大该位置像素可增加目标t分数;若负值则减小。
3、使用显著图挑选需要改变的像素位置
对于2中我们构建的显著图,我们挑选使得

值最大的位置,然后增加或减小其像素值,对应的就能增加目标t 的输出,然后进行迭代,直到攻击成功或达到最大破坏阈值。
4.2特征启用和禁用(Feature enabling and disabling)
Stokes等人提出了三种基于雅可比矩阵的迭代方法,分别使用正特征和负特征。
- 正特征是指恶意软件的指标—这意味着恶意软件类相对于输入的雅可比矩阵对于该特征是正的。
- 同样,负特征是良性类的指标。
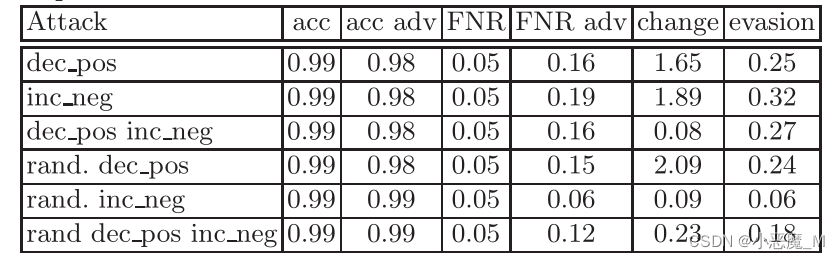
迭代禁用正特征称为dec_pos攻击,禁用负特征称为inc_neg。这些方法可以交替使用,以获得dec_pos+ inc_neg。可以选择随机特征,而不是选择具有最大值的特征。这导致了另外三种不同的技术;随机化dec_pos、随机化inc_neg和随机化dec_pos+ inc_neg。我们将这些攻击应用于在Drebin500上训练的受害者模型,结果见表4。
表4:基于雅可比矩阵启用和禁用特征的方法。在Drebin500上报告的表格
结果
- 随机化的inc_neg完全没有实现任何额外的规避,这表明随机启用特征不是一个好方法。
- 与dec_pos相比,在Drebin500上,inc_neg实现了更高的规避率,平均变化略有增加。
4.3带舍入和位上升的FGSM(FGSM with rounding and Bit ascending)
Huang等人提出了四种不同的方法。
- 前两种方法基于快速梯度符号法(Fast Gradient Sign Method)。FGSM是一种沿最大损耗方向移动样本的一步方法。
- 攻击的一个更强大的变体是多步
,其中k是迭代次数。要将此方法应用于离散恶意软件域,需要四舍五入。作者提出了两种不同的取整方案:确定性取整
和随机取整
。
- 第三种方法是访问多个有希望的顶点,并更深入地探索可能的特征空间。这种方法称为多步位梯度上升(Bit Gradient Ascent)
。
范数,除以
。
- 另一种方法是多步位坐标上升(Bit Coordinate Ascent )
。在每一步中,与损失最大偏导数特征对应的位都会发生变化。
攻击在Drebin500上训练的模型的结果见表5。
表5:方法 ,
,
,
和
。在Drebin500报告的表格
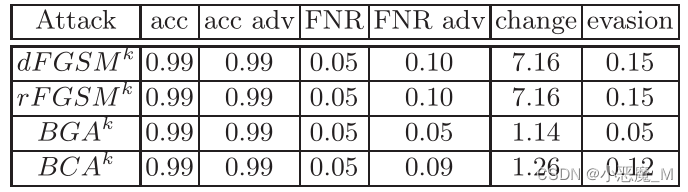
结果
- FGSM的迭代变体在规避方面产生了最有效的对抗示例。采用的四舍五入方案无关紧要。当我们攻击其他的受害者模型时,同样的模式也适用。
- 在APDS上,两种攻击都实现了100%的逃逸率。
【补充】对抗样本之FGSM原理&实战 - 简书 (jianshu.com)
FGSM介绍
- FGSM(fast gradient sign method)是一种基于梯度生成对抗样本的算法,属于对抗攻击中的无目标攻击(即不要求对抗样本经过model预测指定的类别,只要与原样本预测的不一样即可)
- 我们在理解简单的dp网络结构的时候,在求损失函数最小值,我们会沿着梯度的反方向移动,使用减号,也就是所谓的梯度下降算法;而FGSM可以理解为梯度上升算法,也就是使用加号,使得损失函数最大化。
如下图,其中 x 是原始样本,θ 是模型的权重参数(即w),y是x的真实类别。输入原始样本,权重参数以及真实类别,通过 J 损失函数求得神经网络的损失值,∇x 表示对 x 求偏导,即损失函数 J 对 x 样本求偏导。sign是符号函数,即sign(-2),sign(-1.5)等都等于 -1;sign(3),sign(4.7)等都等于 1。sign函数图如下。
ϵ(epsilon)的值通常是人为设定 ,可以理解为学习率,一旦扰动值超出阈值,该对抗样本会被人眼识别。


之后,原始图像x + 扰动值 η = 对抗样本 x + η 。
理解公式后,感觉FGSM并不难。其思想也和dp神经网络类似,但它更像是一个逆过程。我们机器学习算法中无论如何都希望损失函数能越小越好;那对抗样本就不一样了,它本身就是搞破坏的东西,当然是希望损失值越大越好,这样算法就预测不出来,就会失效。
4.4 MalGAN
MalGAN是Hu等人提出的一种攻击。为了创建对抗性示例,它使用了生成性对抗网络(GAN)。GANs背后的想法是通过训练人工神经网络来创建数据。在我们的实验中,我们使用了Hu等人描述的体系结构。
- 生成器将一个合法样本作为输入和一个10维噪声向量。它被送入一个完全连接的隐藏层,有256个单元和ReLU激活。
- 隐藏层完全连接到使用sigmoid作为激活功能的输出层。输出层的大小就是输入层的大小。在最后一层之后,输出被四舍五入,从而转化为适当的二进制特征表示。
- 对于鉴别器,我们使用一个简单的网络,有一个隐藏层,256个神经元,ReLU激活。输出层由一个神经元组成,sigmoid激活。
生成器和鉴别器经过100次迭代训练。每一次生成的对抗性示例都会通过黑盒检测器进行测试。最后,使用黑匣子上错误分类率最高的生成器。
- 对于黑盒检测器,使用了具有两个隐藏层的模型。第一个隐藏层有256个,第二个隐藏层有128个。两者都使用ReLU作为激活,在训练期间信息丢失(dropout)为0.2。
- 输出层有两个神经元,使用softmax激活。黑盒使用Adam进行200次迭代的训练,学习率为.001,β1=.9,β2=.999。
通过这次攻击,我们获得了表6中的规避率。
表6:Hu等人使用GAN创建对抗性示例的方法

结果
- 有趣的是,当攻击Drebin500受害者模型时,根本没有实现任何规避。事实上,情况正好相反,所有对抗示例都得到了正确分类,从而提高了模型性能。
- 在APDS上,攻击的规避率达到77%。通过使用更复杂的鉴别器和/或生成器,对Drebin500模型的攻击可能会更有效。
4.5攻击有效性
攻击的有效性可以通过其创建避开分类器的对抗性示例的能力来衡量。
表7:所有受害者模型上不同攻击有效性的比较
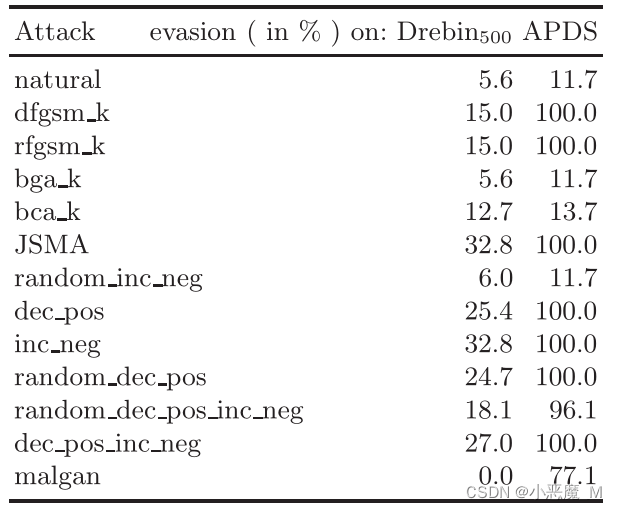
结果
- 首先,对于所有预期的
- Drebin500上的
五、防御(defenses)
5.1蒸馏(Distillation)
蒸馏最初是作为一种训练较小模型的技术引入的。为了实现这一点,较小的模型使用软类标签进行训练,软类标签是较大模型的输出。作为一种防御技术,蒸馏还训练具有软类标签的第二个网络,但在这种情况下,这两个网络具有相同的体系结构。这样做的目的不是让网络变得更小,而是通过更好地概括,使其更能适应敌对的例子。
【补充】【深度学习】深度学习之对抗样本问题和知识蒸馏技术_专栏_易百纳技术社区 (ebaina.com)
到底什么是知识蒸馏?
一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。
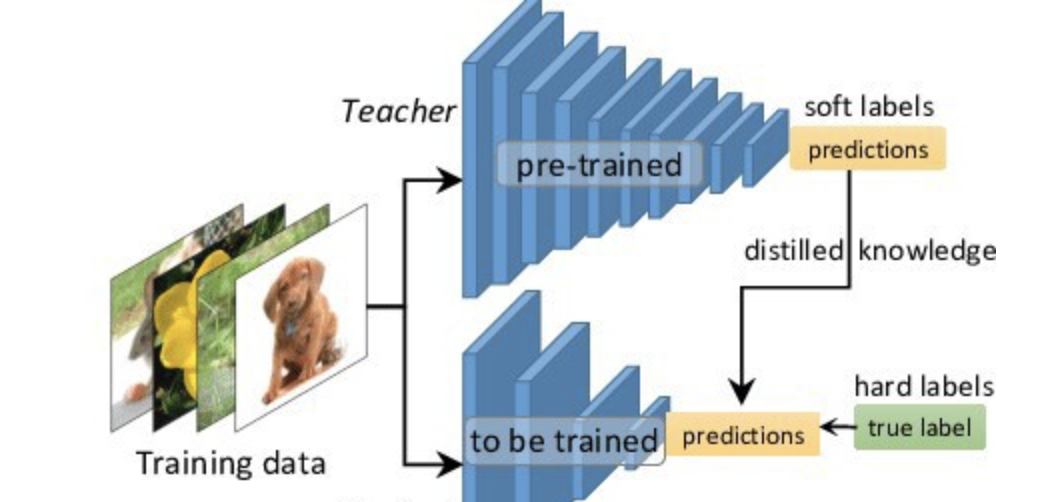
Hinton等人最早在文章《Distilling the Knowledge in a Neural Network》中提出了知识蒸馏这个概念,其核心思想是先训练一个复杂网络模型,然后使用这个复杂网络的输出和数据的真实标签去训练一个更小的网络,因此知识蒸馏框架通常包含了一个复杂模型(被称为Teacher模型)和一个小模型(被称为Student模型)。
为什么要有知识蒸馏?
知识蒸馏是模型压缩中重要的技术之一。
- 提升模型精度。如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的A模型。
- 降低模型时延,压缩网络参数。如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A,从而达到降低时延的目的。
- 标签之间的域迁移。假如使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B,那么就可以用这两个模型同时蒸馏出一个可以识别狗、猫、香蕉以及苹果的模型,将两个不同域的数据集进行集成和迁移。
知识蒸馏基本框架
知识蒸馏采取Teacher-Student模式:将复杂且大的模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。
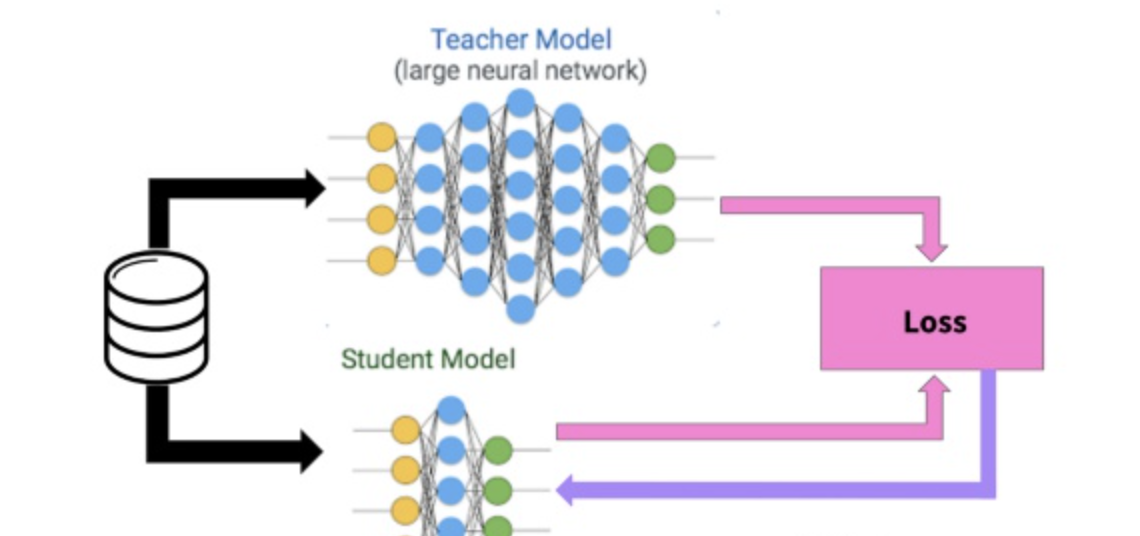
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向,下面我们对其进行介绍。 知识蒸馏 知识蒸馏是一种模型压缩方法,是一种基于“教师-学生网络思想”的训练方法。
知识蒸馏损失函数:
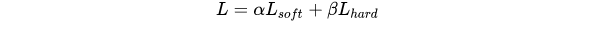

5.2对抗训练
- Szegedy等人提出了一种称为对抗训练的策略。其想法是,向训练数据中添加对抗性示例可以起到规范化的作用。这提高了模型的泛化能力,从而使其更能抵抗对抗性示例。
- Kurakin等人介绍了一种基于小批量的可扩展对抗训练框架。他们还发现,使用单步方法(如FGSM)创建的示例比迭代方法具有更大的好处。
- Mossavi等人发现,当使用对抗性样本进行对抗训练时,使用DeepFool样本会增加鲁棒性,而使用FGSM样本可能会导致鲁棒性降低。
- Tramèr等人发现,经过对抗训练的模型更能抵抗白盒攻击,但与直觉相反,仍然容易受到黑盒攻击。
多位作者将对抗训练视为恶意软件领域的防御手段。4.4提出四种不同的方法, ,
,
和
,理论上,这里可以使用任何创建对抗性示例的方法。我们使用
创建对抗性示例。
结果
对抗训练非常有效,可以使网络对对抗性示例更加稳健。另一个可能有益的策略是在训练中使用来自不同攻击的对抗性示例。
【补充】论文阅读:对抗训练(adversarial training) - 知乎 (zhihu.com)
概念
鲁棒性——对于对抗样本防御的性能,称之为鲁棒性(Roubustness)
泛化性——训练集训练的模型在测试集上的性能。
所谓对抗训练,则是属于对抗防御的一种,它构造了一些对抗样本加入到原数据集中,希望增强模型对对抗样本的鲁棒性。
对抗训练(adversarial training)是增强神经网络鲁棒性的重要方式。在对抗训练的过程中,样本会被混合一些微小的扰动(改变很小,但是很可能造成误分类),然后使神经网络适应这种改变,从而对对抗样本具有鲁棒性。
在图像领域,采用对抗训练通常能提高鲁棒性,但是通常都会造成泛化性降低,也就是说,虽然对对抗样本的抵抗力提升了,但是有可能影响普通样本的分类能力。神奇的是,在语言模型领域却观察到不一致的结果——对抗训练既提高了鲁棒性也提高了泛化性。所以对抗训练还值得研究一下,毕竟对效果也是有提升的。
我们首先来看一下对抗训练的一般性原理,对抗训练可以概括为如下的最大最小化公式:
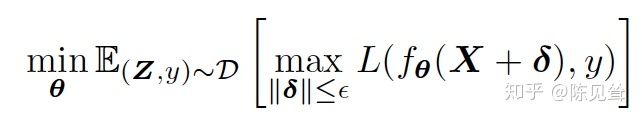

外层就是对神经网络进行优化的最小化公式,即当扰动固定的情况下,我们训练神经网络模型使得在训练数据上的损失最小,也就是说,使模型具有一定的鲁棒性能够适应这种扰动。
这个公式是一个一般性的公式,并没有讲如何设计扰动。理想情况下,最好是能直接求出,但在神经网络模型中这是不太可行的。所以大家就提出各种各样的扰动的近似求解的方法。事实上,对抗训练的研究基本上就是在寻找合适的扰动,使得模型具有更强的鲁棒性。
5.3集成(Ensembles)
Tramèr等人提出了对集成方法的改进,称为集成对抗训练(ensemble adversarial traning)。
- 与正常对抗训练一样,对抗性示例也包含在数据集中。
- 在集成对抗训练中,对抗性示例不仅来自被训练的模型,还来自另一个预先训练的模型。这种训练技巧可以增强黑匣子攻击的防御能力。
作者没有考虑使用目标模型的输出来增强攻击的自适应黑盒攻击。在我们的实验中,我们训练三个不同的模型,并将它们组合成一个整体。为了让集成发挥作用,最好有行为不同的模型。因此,我们选择了三种截然不同的体系结构。这三种体系结构如下所示。
- 1.对于我们的第一个模型,我们选择了一个非常宽但相当平坦的架构。它由两个完全连接的隐藏层组成,每个层有1000个神经元。
- 2.第二个模型的设计与第一个模型相反,是一个相当平坦但更深的建筑。它由八个隐藏层组成,每个层有64个神经元。
- 3.第三个模型相当小,有两个隐藏层,第一个由256个神经元组成,第二个由128个神经元组成。除最后一层使用softmax外,所有模型均使用ReLU作为所有层的激活函数。为了迫使模型彼此更加不同,我们采用了大量的丢弃(dropout)。两个隐藏层的丢弃值均为0.5。
我们使用Adam优化器和本文前面描述的标准设置,对这三个模型进行了200次迭代训练。我们用我们所有的攻击测试网络集成的鲁棒性。
与受害者模型相比,集成的自然规避效果更好,但集成在对抗鲁棒性方面没有增加任何东西。集成中的不同模型可以使用不同的特征进行训练。这可能会提高恢复能力,使攻击者更难找到要修改的特征。
【补充】(27条消息) 机器学习_集成学习(Ensemble)_【WeThinkIn】的主理人的博客-优快云博客_深度学习ensemble
集成学习介绍
集成学习也称为模型融合(Model Ensemble)。是一种有效提升机器学习效果的方法。
不同于传统的机器学习方法在训练集上构建一个模型,集成学习通过构建并融合多个模型来完成学习任务。
首先我们通过下图的一个例子来介绍集成的基本概念,下图是一个二分类问题。
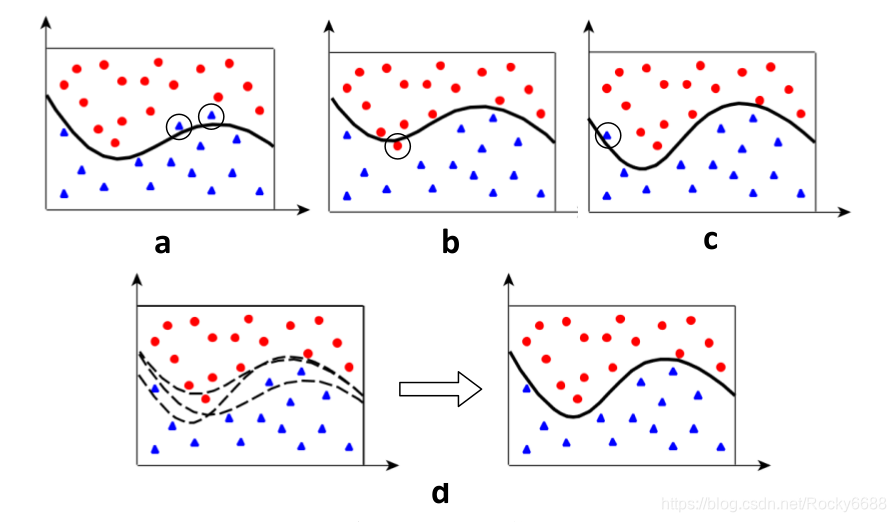
图中的数据均是测试数据,a、b、c分别是三个不同模型在测试集上的分类结果。需要注意的是,一般在做集成的时候,
- 相同模型结构的不同参数是比较常见的情况(同质模型融合(Homogeneous Model Ensemble))。
- 但是不能死板,我们也可以把不同模型甚至完全不同的算法做集成学习(异质模型融合(Heterogeneous Model Ensemble))。
上图中每个模型的错误分类的样本都用圆圈标了出来,可以看到每个模型大体都是准确的,但是错误的情况也会存在。这种情况下,我们可以考虑用集成的方法:将3个不同模型的记过进行综合考虑,因为错误分类毕竟是少数,所以最终的结果的可靠性就会增加。
上图d模型就是进行集成学习的结果,可以看到效果变好了。这里采用的方法是多数投票(majority vote):对3个模型分类结果中多数的结果作为最终结果。除了多数投票,在实际应用中常见的方法还有取均值或者中值,但是基本思想都是一样的。
以上,集成学习主要包含两个步骤:
- 训练若干个单模型(Signle Model),也称作基学习器(Base Learner)。这些单模型可以是决策树、神经网络或者是其他类型的算法。
- 模型融合,相应的方法有平均法、投票法和学习法等等。我们不单单可以进行一级模型融合,我们也可以进行多级模型融合,或者是一级模型和二级模型的混合融合类。
集成学习的泛化能力要比单模型强得多,这也是集成学习能够被人们广泛研究和应用的原因。集成学习可以整合多个"弱"模型最终得到一个"强"模型。
集成法是通过多个模型的结果综合考虑给出最终的结果,虽然准确率和稳定性都会提高,但是训练多个模型的计算成本也是非常高的,如果训练10个左右的模型,则计算成本高了一个量级。
融合方法
- 1.平均法
- 2.投票法
- 3.Bagging。独立的集成多个模型,每个模型有一定的差异,最终综合有差异的模型的结果,获得学习的最终的结果。其中Dropout可以认为是一种极端的Bagging,每个模型都在单独的数据上训练,同时,通过和其他模型对应参数的共享,从而实现模型参数的高度正则化。
- 4.Stacking。Stacking的基本思路是:通过一个模型来融合若干个单模型的预测结果,目的是降低单模型的泛化误差。单模型被称为一级模型,Stacking融合模型被称为二级模型或元模型。
- 5.Boosting(集成增强学习)。集成多个模型,每个模型都在尝试增强(Boosting)整体的效果。
5.4随机特征无效(Random Feature Nullification)
为了让攻击者更难计算梯度,Wang等人引入了一种称为随机特征无效的防御方法。在训练和分类过程中,一组随机特征被禁用。这是通过选择二进制向量 并计算实例 xi 和向量
的哈达玛乘积(Hadamard-Product如下例子)来实现的。
中的零是均匀分布的。零的数量和分布是可以调整的超参数。

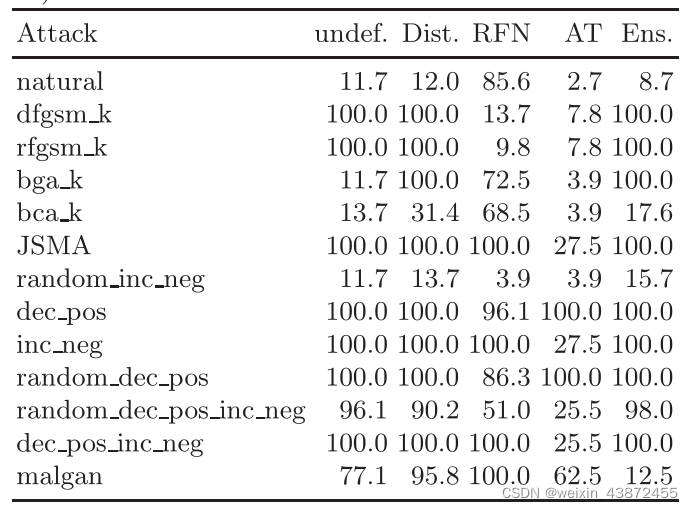
表8:所有受害者模型上不同攻击有效性的比较。报告的是规避率(以%)。使用的防御:未防御(undef.),蒸馏(Dist.)、随机特征无效(RFN)、对抗训练(AT)和集成(Ens.)
六、讨论
比较不同的防御措施。并列比较见表8。
- 蒸馏对对抗性稳健性几乎没有积极的影响,并在某些攻击中有效地伤害了它。
- 随机特征消除可能是有益的,因为它显著提高了鲁棒性,但在我们的实验中,它也会极大地损害未受攻击的性能。
- 虽然集成被证明有助于改善自然逃避,但它不能防止对抗性规避。在集成中使用分类器,根据实例的不同特征表示进行训练,可能会使系统更加健壮。
- 唯一能提供显著鲁棒性的防御是对抗性训练。
对抗训练的问题在于,它对训练期间使用的攻击最有效。因此,它不一定对新的未知攻击具有鲁棒性。即使防御不会显著影响分类器的性能,也可能会使其更容易受到某些对抗性示例创建方法的攻击。这就提出了一个问题,即我们今天采用的防御措施是否真的使模型更容易受到未来的攻击。
理想情况下,一个好的防御系统应该对未知攻击具有鲁棒性。防御需要以某种方式适应该领域。本文比较的所有防御都是领域不可知的。也许一种更直接地针对二进制数据的方法可以提高弹性。
七、结论
通过对不同数据集上的12次攻击和4次防御进行评估,我们研究了恶意软件分类中对抗示例的空间。
- 我们的实验表明,攻击工作可靠,创建对抗性示例相对简单直接。
- 另一方面,这些防御措施并不那么直接,可能并不总是合适的。正确的防御选择取决于许多不同的因素,如数据集、模型体系结构等。
- 我们的研究结果表明,除对抗训练外,大多数基于图像分类的防御机制在恶意软件领域都是无效的,需要针对二进制数据的方法来确保分类器的鲁棒性。

















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









