







 本文详细介绍Hadoop全分布式环境的搭建步骤,包括配置环境、格式化HDFS、启动集群等关键环节,确保Hadoop集群稳定运行。
本文详细介绍Hadoop全分布式环境的搭建步骤,包括配置环境、格式化HDFS、启动集群等关键环节,确保Hadoop集群稳定运行。
Hadoop 全分布式搭建流程
准备工具
1.hadoop-2.7.1.tar.gz 上传到/opt 下
2。集群的所有服务器需要安装jdk 环境变量配置完成
3.ip 主机名互相ping通
4.ssh免密
1.解压 hadoop 压缩包
我们先在一台虚拟机上配置
cd /opt
tar -zxvf hadoop-2.7.1.tar.gz
ll

2.配置hadoop-2.7.1/etc/hadoop 下的配置文件
vi hadoop-env.sh(配jdk路径)
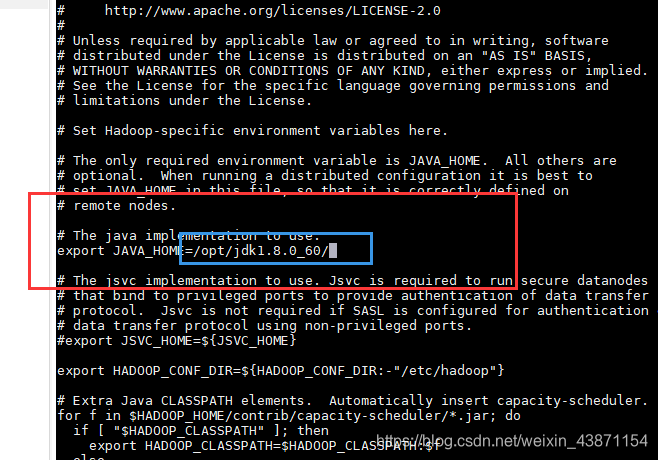
vi slaves(配置哪台机子启动)

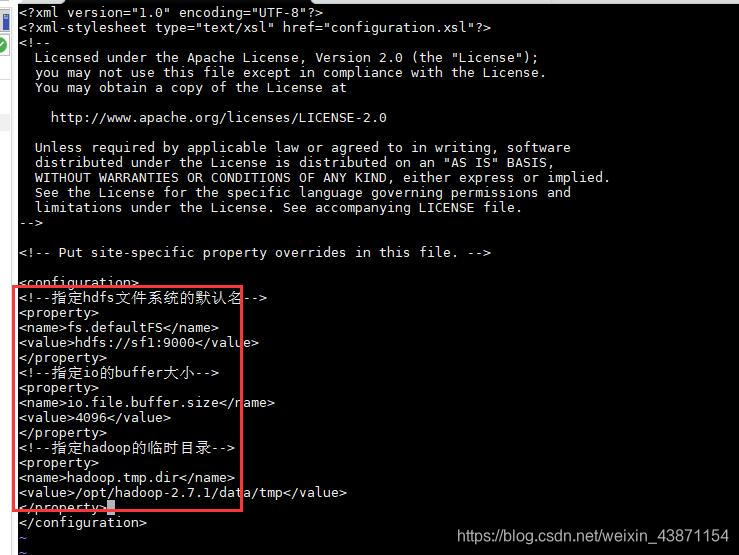
vi core-site.xml(配namenode主机名和hadoop运行临时目录)
<!--指定hdfs文件系统的默认名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://sf1:9000</value>
</property>
<!--指定io的buffer大小-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定hadoop的临时目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.1/data/tmp</value>
</property>
4. vi hdfs-site.xml (配副本数、块大小、NN DN SNN保存存储目录、NN SNN的webUI端口)
<!--指定块的副本数,默认是3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定数据块的大小-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!--指定namenode的元数据目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-2.7.1/data/dfs/name</value>
</property>
<!--指定datanode存储数据目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-2.7.1/data/dfs/data</value>
</property>
<!--指定secondarynamenode的检测点目录-->
<property>
<name>fs.checkpoint.dir</name>
<value>/opt/hadoop-2.7.1/data/dfs/checkpoint/cname</value>
</property>
<!--edit的数据存储目录-->
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/opt/hadoop-2.7.1/data/dfs/checkpoint/edit</value>
</property>
<!--指定namenode的webui监控端口-->
<property>
<name>dfs.http.address</name>
<value>sf1:50070</value>
</property>
<!--指定secondarynamenode的webui监控端口-->
<property>
<name>dfs.secondary.http.address</name>
<value>sf2:50090</value>
</property>
<!--是否开启webhdfs的-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--是否开启hdfs的权限-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>

5. vi mapred-site.xml (配MR运行基于yarn、配历史服务器的内部通信端口和webUI 端口)
将 mapred-site.xml.template 复制一份出来 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml

<!--配置mapreduce的框架名称-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<!--指定jobhistoryserver的内部通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>sf3:10020</value>
</property>
<!--指定jobhistoryserver的web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>sf3:19888</value>
</property>
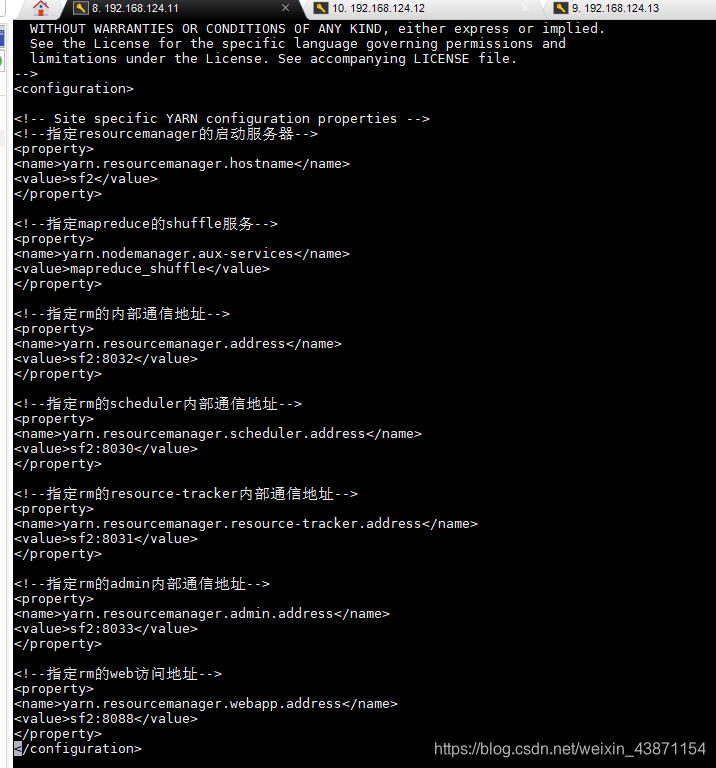
vi yarn-site.xml(配RM的主机名、内部通信端口、webUI端口)
<!--指定resourcemanager的启动服务器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sf2</value>
</property>
<!--指定mapreduce的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定rm的内部通信地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>sf2:8032</value>
</property>
<!--指定rm的scheduler内部通信地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sf2:8030</value>
</property>
<!--指定rm的resource-tracker内部通信地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sf2:8031</value>
</property>
<!--指定rm的admin内部通信地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sf2:8033</value>
</property>
<!--指定rm的web访问地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sf2:8088</value>
</property>
3.发送配置好的hadoop到每一台服务器中
scp -r /opt/hadoop-2.7.1 root@sf2:/opt
scp -r /opt/hadoop-2.7.1 root@sf3:/opt
4.HDFS格式化(namenode的格式化)
在namenode的节点(sf1)上
hdfs namenode -format
格式化只需要在namenode的服务器上执行,为了初始化元数据(所以yarn不需要初
始化)
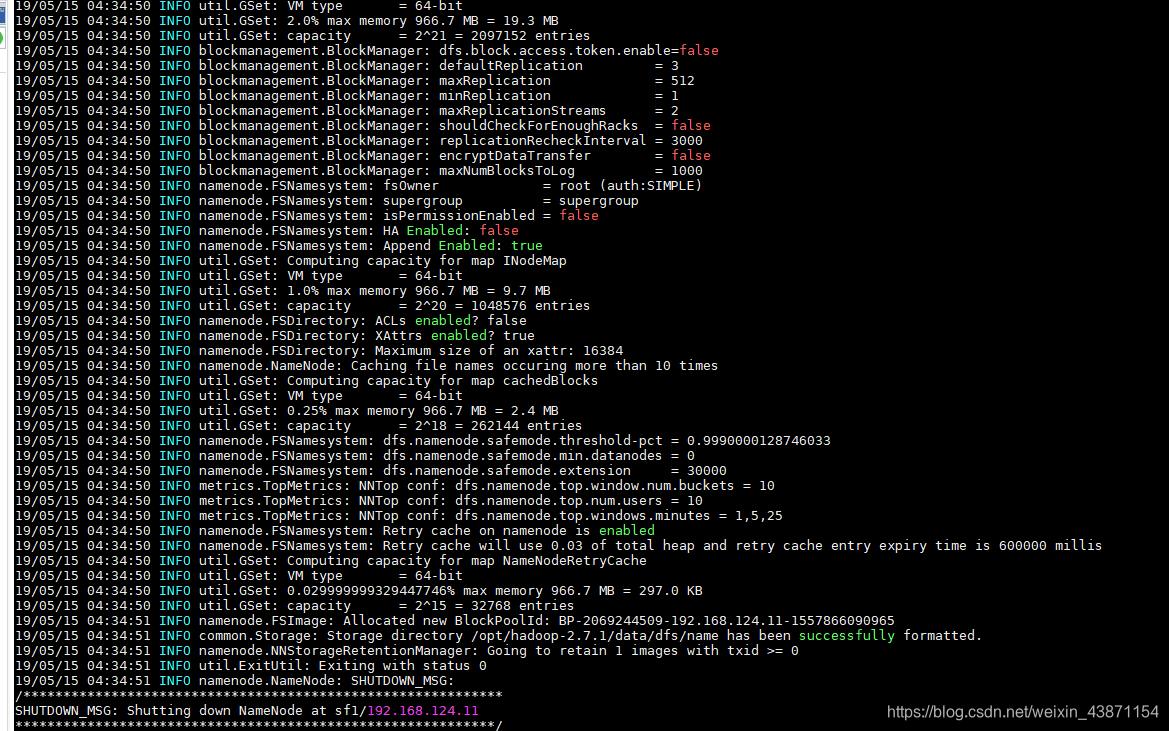
确认没有报错信息 如果想有根据配置信息查找错误 多为配置文件错误
cd /data/dfs/name/current
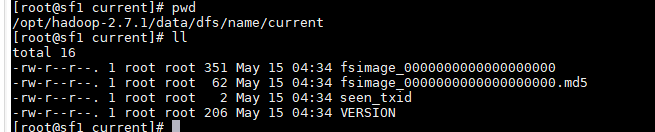
确认不缺少文件
5.启动集群
-
在namenode的节点上启动hdfs:
start-dfs.sh
1.1 在sf1上

cd /opt/hadoop-2.7.1/data/dfs
启动后生成了一个新的文件 data
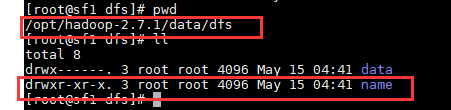
1.2 在 sf2 上
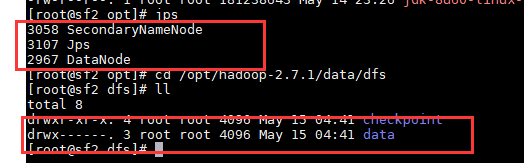
1.3 在 sf3上
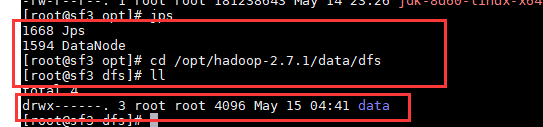
2 . 在ResouceManager的节点上启动yarn (注意环境变量的问题)start-yarn.sh
在 sf3
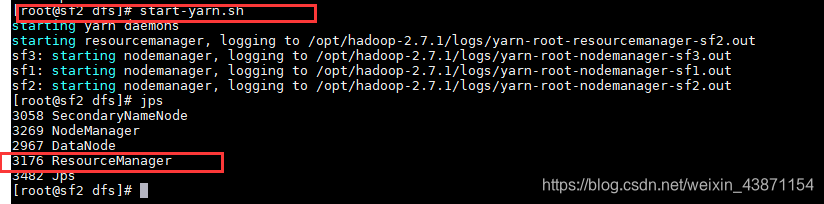
-
在历史服务器的节点上启动历史服务器
mr-jobhistory-daemon.sh start historyserver
在 sf3

6 检验
jps
sf1 :
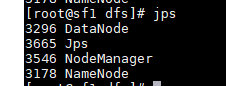
sf2:
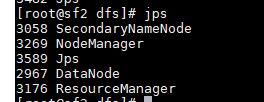
sf3:
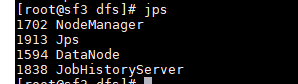
查看webUI
HDFS sf1:50070 访问NN sd2:50090 访问SNN
(如果在window中没有配置映射需要使用ip地址访问 ef:192.168.124.11:50070)

















 5417
5417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









