






以前学习浏览器的渲染机制时,对浏览器的渲染概念就是html解析成DOM,css形成样式规则。两者共同构建渲染树。浏览器根据渲染树的样式进行布局和渲染。后来再次回过头去看这些概念时发现很多知识点都是非常深的。
比如浏览器如何解析CSS形成样式树,那么浏览器究竟如何解析?了解这些并非没有意义,比如当了解css解析是自右向左后,就知道在写css样式时应该避免嵌套。了解解析顺序就知道如何缩短首屏时间提高用户体验。
浏览器渲染机制涉及到的内容非常多,因时间有限,本次分享重点介绍CSS的一些渲染规则,并就此引出一些可以优化的CSS规则。
目录
- 浏览器渲染机制
- CSS解析机制
- 优化方式
浏览器渲染机制
时间都去哪儿了?
从耗时的角度,浏览器请求、加载、渲染一个页面,时间花在下面五件事情上:
- DNS 查询
- TCP 连接
- HTTP 请求
- 服务器响应
- 客户端渲染
浏览器渲染步骤
- 处理 HTML 标记并构建 DOM 树。
- 处理 CSS 标记并构建 CSSOM 树。
- 将 DOM 与 CSSOM 合并成一个渲染树。
- 根据渲染树来布局,以计算每个节点的几何信息。
- 将各个节点绘制到屏幕上。
一、处理 HTML标记并构建DOM树。
当浏览器接收到服务器响应来的HTML文档后,会遍历文档节点,生成DOM树。 需要注意的是,DOM树的生成过程中可能会被CSS和JS的加载执行阻塞。
浏览器处理过程:
- 转换:
浏览器从磁盘或网络读取 HTML 的原始字节,然后根据指定的文件编码格式(例如 UTF-8 )将其转换为相应字符 - 符号化:
浏览器将字符串转换为 W3C HTML5 标准 指定的各种符号 - 词法分析:
发射的符号转换为 对象 ,定义它们的属性与规则 - DOM 构建:
因为 HTML 标记定义不同标签间的相互关系(某些标签嵌套在其他标签中),所以创建的对象在树状数据结构中互相链接,树状数据结构还捕获原始标记中定义的父子关系:比如 HTML 对象是 body 对象的父对象, body 是 paragraph 对象的父对象等等
二、处理 CSS 标记并构建 CSSOM 树。
三、将 DOM 与 CSSOM 合并成一个渲染树。
解析完成后,浏览器引擎会通过DOM Tree 和 CSS Rule Tree 来构造 Rendering Tree。不过,Rendering Tree 渲染树并不等同于DOM树,因为渲染树和 DOM 元素相对应的,但并非一一对应,渲染树是用于显示,那些不可见的元素当然就不会在这棵树中出现了。比如非可视化的 DOM 元素不会插入呈现树中,例如“head”元素。如果元素的 display 属性值为“none”,那么也不会显示在呈现树中(但是 visibility 属性值为“hidden”的元素仍会显示)
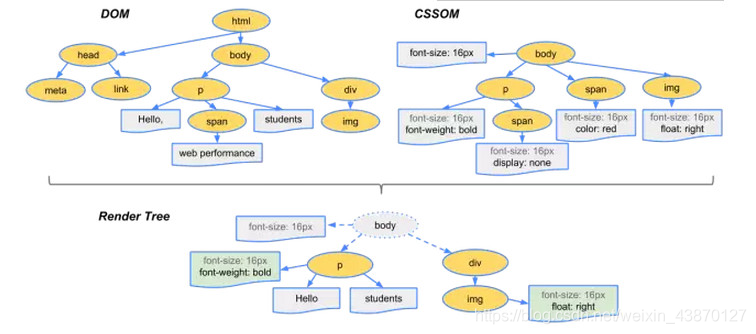
四、根据渲染树来布局,以计算每个节点的几何信息。
- 布局阶段会从渲染树的根节点开始遍历
- 确定每个节点对象在页面上的确切位置(由css布局方式决定)
- 然后确定每个节点对象内部的尺寸(由盒子模型决定)
- 精确地捕获每个元素在屏幕内的确切位置与大小
五、将各个节点绘制到屏幕上。
根据渲染树布局,HTML默认是流式布局的,CSS和js会打破这种布局,改变DOM的外观样式以及大小和位置 。
这时就要提到两个重要概念:replaint(重绘)和reflow(回流)
replaint(重绘) : 屏幕的一部分重画,不影响整体布局, 比如某个CSS的背景色变了,但元素的几何尺寸和位置不变。 所以重绘不会影响到其他元素
reflow(回流):意味着元件的几何尺寸变了,我们需要重新验证并计算渲染树。 这会影响到其他元素的尺寸和位置,是渲染树的一部分或全部发生了变化。
CSS解析机制
在上文中,我们谈到了渲染引擎加载页面时浏览器的具体工作流程。粗略地说,就是构建一个dom树,页面要显示的各元素都会创建到这个dom树当中,每当一个新元素加入到这个dom树当中,浏览器便会通过css引擎查遍css样式表,找到符合该元素的样式规则应用到这个元素上。CSS 引擎查找样式表,对每条规则都按从右到左的顺序去匹配。 为什么要从右到左呢?
1.HTML 经过解析生成 DOM Tree(这个我们比较熟悉);而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵 Render Tree,最终用来进行绘图。Render Tree 中的元素与 DOM 元素相对应,但非一一对应:一个 DOM 元素可能会对应多个 renderer,如文本折行后,不同的「行」会成为 render tree 种不同的 renderer。也有的 DOM 元素被 Render Tree 完全无视,比如 display:none 的元素。
2.在建立 Render Tree ,浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果来确定生成怎样的 renderer。对于每个 DOM 元素,必须在所有 Style Rules 中找到符合的 selector 并将对应的规则进行合并。选择器的「解析」实际是在这里执行的,在遍历 DOM Tree 时,从 Style Rules 中去寻找对应的 selector。
3.因为所有样式规则可能数量很大,而且绝大多数不会匹配到当前的 DOM 元素(因为数量很大所以一般会建立规则索引树),所以有一个快速的方法来判断「这个 selector 不匹配当前元素」就是极其重要的。
4.如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。
5.逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。
6.但因为匹配的情况远远低于不匹配的情况,所以逆向匹配带来的优势是巨大的。同时我们也能够看出,在选择器结尾加上「*」就大大降低了这种优势,这也就是很多优化原则提到的尽量避免在选择器末尾添加通配符的原因。
简单的来说浏览器从右到左进行查找的好处是为了尽早过滤掉一些无关的样式规则和元素
<div>
<div class="Aaron">
<p><span>s1</span></p>
<p><span>s2</span></p>
<p><span>s3</span></p>
<p><span class='red'>s4</span></p>
</div>
</div>
CSS选择器:
div > div.Aaron p span.red{
color:red;
}
如果按从左到右的方式进行查找:
- 先找到所有div节点
- 第一个div节点内找到所有的子div,并且是class="Aaron
- 然后再一次匹配p span.red等情况
- 遇到不匹配的情况,就必须回溯到一开始搜索的div或者p节点,然后去搜索下个节点,重复这样的过程。这样的搜索过程对于一个只是匹配很少节点的选择器来说,效率是极低的,因为我们花费了大量的时间在回溯匹配不符合规则的节点。如果换个思路,我们一开始过滤出跟目标节点最符合的集合出来,再在这个集合进行搜索,大大降低了搜索空间。
从右到左来解析选择器:
首先就查找到的元素。Firefox称这种查找方式为key selector(关键字查询),所谓的关键字就是样式规则中最后(最右边)的规则,上面的key就是span.red。
紧接着我们判断这些节点中的前兄弟节点是否符合p这个规则,这样就又减少了集合的元素,只有符合当前的子规则才会匹配再上一条子规则。要知道DOM树是一个什么样的结构,一个元素可能有若干子元素,如果每一个都去判断一下显然性能太差。而一个子元素只有一个父元素,所以找起来非常方便。
优化方式
选择器性能优化
CSS选择器对性能的影响源于浏览器匹配选择器和文档元素时所消耗的时间, 所以优化选择器的原则是应尽量避免使用消耗更多匹配时间的选择器。
CSS 选择器的执行效率从高到低
- id选择器(#myid)
- 类选择器(.myclassname)
- 标签选择器(p,h1,p)
- 相邻选择器(h1+p)
- 子选择器(ul < li)
- 后代选择器(li a)
- 通配符选择器(*)
- 属性选择器(a[rel=“external”])
- 伪类选择器(a:hover, li:nth-child)
优化方式
1、避免使用通配规则。如 *{} 计算次数惊人!
2、尽量少的去对标签进行选择,而是用class。如:#nav li{},可以为li加上nav_item的类名,如下选择.nav_item{}
3、不要去用标签限定ID或者类选择符。如:ul#nav,应该简化为#nav
4、尽量少的去使用后代选择器,降低选择器的权重值。后代选择器的开销是最高的,尽量将选择器的深度降到最低,最高不要超过三层,更多的使用类来关联每一个标签元素。
5、考虑继承。了解哪些属性是可以通过继承而来的,然后避免对这些属性重复指定规则
示例一:
#nav li {}
CSS选择符是从右到左进行匹配的。了解这方面的知识后,我们知道这个之前看似高效地规则实际开销相当高,浏览器必须遍历页面上每个li元素并确定其父元素的id是否为nav。
示例二:
*{}
*通配符将匹配所有元素,所以浏览器必须去遍历每一个元素,这样的计算次数可能是上万次!
示例四:
ul#nav{} ul.nav{}
在页面中一个指定的ID只能对应一个元素,所以没有必要添加额外的限定符,而且这会使它更低效


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









