






 本文深入介绍了并查集的数据结构,包括其在判断元素间连通性问题中的应用,以及两种优化策略:权值并查集和路径压缩。权值并查集通过优先合并小集合减少查找次数,降低树高。路径压缩则通过递归直接找到根节点,提升查询效率。文章还展示了如何使用并查集解决实际问题,例如在给定数组中寻找最长连续子集的长度,并详细解析了优化后的并查集类的实现细节。
本文深入介绍了并查集的数据结构,包括其在判断元素间连通性问题中的应用,以及两种优化策略:权值并查集和路径压缩。权值并查集通过优先合并小集合减少查找次数,降低树高。路径压缩则通过递归直接找到根节点,提升查询效率。文章还展示了如何使用并查集解决实际问题,例如在给定数组中寻找最长连续子集的长度,并详细解析了优化后的并查集类的实现细节。
并查集
应用:
- 两个集合(图)之间的连通性
场景:
- 两类元素,属于不同的集合,彼此之间不清楚自己所属的集合
并查集漫画
设计方式:
- 每个集合各自的元素都使用类似指针的方式连通在一起;
- 并查集类UnionFind维护一个parent[]数组,记录自己上一个元素的位置,即parent[i] = last;
- 根节点的parent[i] == i,即自己
这样判别两个元素是否在一个集合,只需要***找到各自的根节点是否相同即可***
代码实现【以最简单的int哈希表为例】:
class UnionFind{
int[] parent;
//记录不同的集合数量
int count;
//初始化
public UnionFind(int n) {
parent = new int[n];
//因为所有人都是一个集合,因此集合数量就是parent长度
count = n;
//所有parent都初始化为自己
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
//为第i个元素查找根节点
public int findRoot(int i) {
while(parent[i] != i) i = parent[i];
return i;
}
//获取集合数量
public int getCount() {
return count;
}
//合并两个集合
//很简单,将其中一个集合的根节点的父节点改为另一个集合根节点即可
public void union(int i, int j) {
int rootA = findRoot(i);
int rootB = findRoot(j);
//已经是同一个集合,无需合并
if (rootA == rootB) return;
parent[rootB] = rootA;
//合并了一个集合,因此集合数量减一
count--;
}
//判断两个元素是否属于同一个集合
public boolean isConnect(int i, int j) {
return findRoot(i) == findRoot(j);
}
}
优化一:权值并查集,压缩树高
存在的问题:
若按照最大值做根节点这样的合并顺序,对于有序数组,每次都插入都满足线性的时间复杂度,如{0, 2, 4, 9}
合并后为 9 -> 4 -> 2 -> 0, 比较次数为n ^ 2
- 优化
增加一个属性为weight[n], 表示每个集合中的元素个数
每次合并时,先考虑两个集合的weight,优先合并较小的集合,减少查找次数
探究:为什么这样做可以降低树高?
假设有两个“集合”要合并【其实本质是多叉树】
A的树高是2,B的树高是3
假设A作为主分支,则B插到A的根节点下,那么A的高度就会变成 1 + 3 = 4【A根节点加上B树高】
而若将较高的B作为主分支,那么树高就是max(3, 1 + 2) = 3
树高竟然没有改变
在任何情况下,矮的插高的都会比高的插矮的树高要低一点
那为什么树高影响查找效率呢?
本质上是不断查找父节点,当然树越低越好【遍历次数减少】
class UnionFind{
int[] parent;
//记录每个集合的元素个数
int[] weight;
//记录不同的集合数量
int count;
//初始化
public UnionFind(int n) {
parent = new int[n];
//因为所有人都是一个集合,因此集合数量就是parent长度
count = n;
//所有parent都初始化为自己
for (int i = 0; i < n; i++) {
parent[i] = i;
weight[i] = 1; //只有自己
}
}
//为第i个元素查找根节点
public int findRoot(int i) {
while(parent[i] != i) i = parent[i];
return i;
}
//获取集合数量
public int getCount() {
return count;
}
//合并两个集合
//很简单,将其中一个集合的根节点的父节点改为另一个集合根节点即可
public void union(int i, int j) {
int rootA = findRoot(i);
int rootB = findRoot(j);
//已经是同一个集合,无需合并
if (rootA == rootB) return;
//i被合并
if (weight[i] < weight[j]) {
parent[rootA] = root[B];
weight[rootB] += weight[rootA];
} else {
//j被合并
parent[rootB] = root[A];
weight[rootA] += root[B];
}
//合并了一个集合,因此集合数量减一
count--;
}
//判断两个元素是否属于同一个集合
public boolean isConnect(int i, int j) {
return findRoot(i) == findRoot(j);
}
}
优化二:路径压缩提高根节点查询效率
非常巧妙,注意:
将find()方法进行优化,使得parent[i] 返回的永远是最终的根节点,而是当前节点的父节点。
如何做到?
递归
//使用路径压缩提高查询速度
//每个节点都指向最终父节点
public int find() {
if (parent[i] != i) parent[i] = find(parent[i]);
return parent[i];
}
使用并查集解128题
顺便理解并查集的用法:
(1)定义根节点规则
根节点规则定义为:集合中最小的那个数
引申出合并规则:
由于要查连续的数,可以稍微修改一下union()方法:
对于数组元素num:
a. 查看num + 1是否在nums中
若在,将num与num + 1合并,因为num 必定小于 num+1,因此num的那一个作为主分支,将num + 1合并
并且方法返回当前这个的集合的个数,作为最终返回值的参考
(2)使用何种并查集:
由于要使用集合个数,可以使用权重集合
class UnionFindSet {
//使用Map存储,防止数组长度不确定造成的越界
//key: 当前元素值
//val: 当前元素的父节点
Map<Integer, Integer> parent;
//当前某集合的元素数量
//key:当前集合的根节点;
//val:以这个根节点作为父节点的元素个数;
Map<Integer, Integer> weight;
int[] nums;
//初始化并查集
public UnionFindSet(int[] nums) {
int len = nums.length;
this.nums = nums;
parent = new HashMap<>();
weight = new HashMap<>();
for (int i = 0; i < len; i++) {
parent.put(nums[i], nums[i]);
weight.put(nums[i], 1);
}
}
//返回根节点
public int find(int num) {
while (num != parent.get(num))
num = parent.get(num);
return num;
}
//接收:当前元素num以及num + 1
//返回:以num所在集合的根节点为根的集合元素个数
//只有***tar包含在nums中,才会进行合并***
public int union(int num, int tar) {
if (!parent.containsKey(tar)) {
//因为在初始化时,所有的元素都会变成一个key,而tar不是key,说明tar不是nums元素
//不是nums元素,不进行合并,直接返回当前元素所在集合个数
return weight.get(find(num));
}
int r = find(num);
int t = find(tar);
//本来就是同一个集合,不合并
if (r == t) return weight.get(num);
parent.put(tar, r);
int sum = weight.get(r) + weight.get(t);
//将主分支元素作为“根节点”的元素个数
weight.put(r, sum);
return sum;
}
//只需要 构造、并、查 三个方法即可
}
//并查集法,需要首先定义并查集类
public int longestConsecutive(int[] nums) {
int max = 0, len;
if (nums == null || (len = nums.length) == 0) return 0;
UnionFindSet ufs = new UnionFindSet(nums);
for (int num : nums) {
max = Math.max(ufs.union(num, num + 1), max);
}
return max;
}
由于在union()中多次采用find(),而find()是一个o(N)的方法,因此union()复杂度也是O(n),因此综合来说,复杂度为O(n)
有没有优化的方法呢?
使用压缩路径法优化并查集的find()
由上节的分析,find()可以通过递归来直接指向根节点。
修改find()为:
public int find(num) {
int n; //num当前的父节点
if (num == (n = parent.get(num))) return num;
int r = find(n);
//当前节点父节点直接设置为根节点,相当于将链表变成了多叉树
parent.put(num, r);
return r;
}
产生的效果如图示
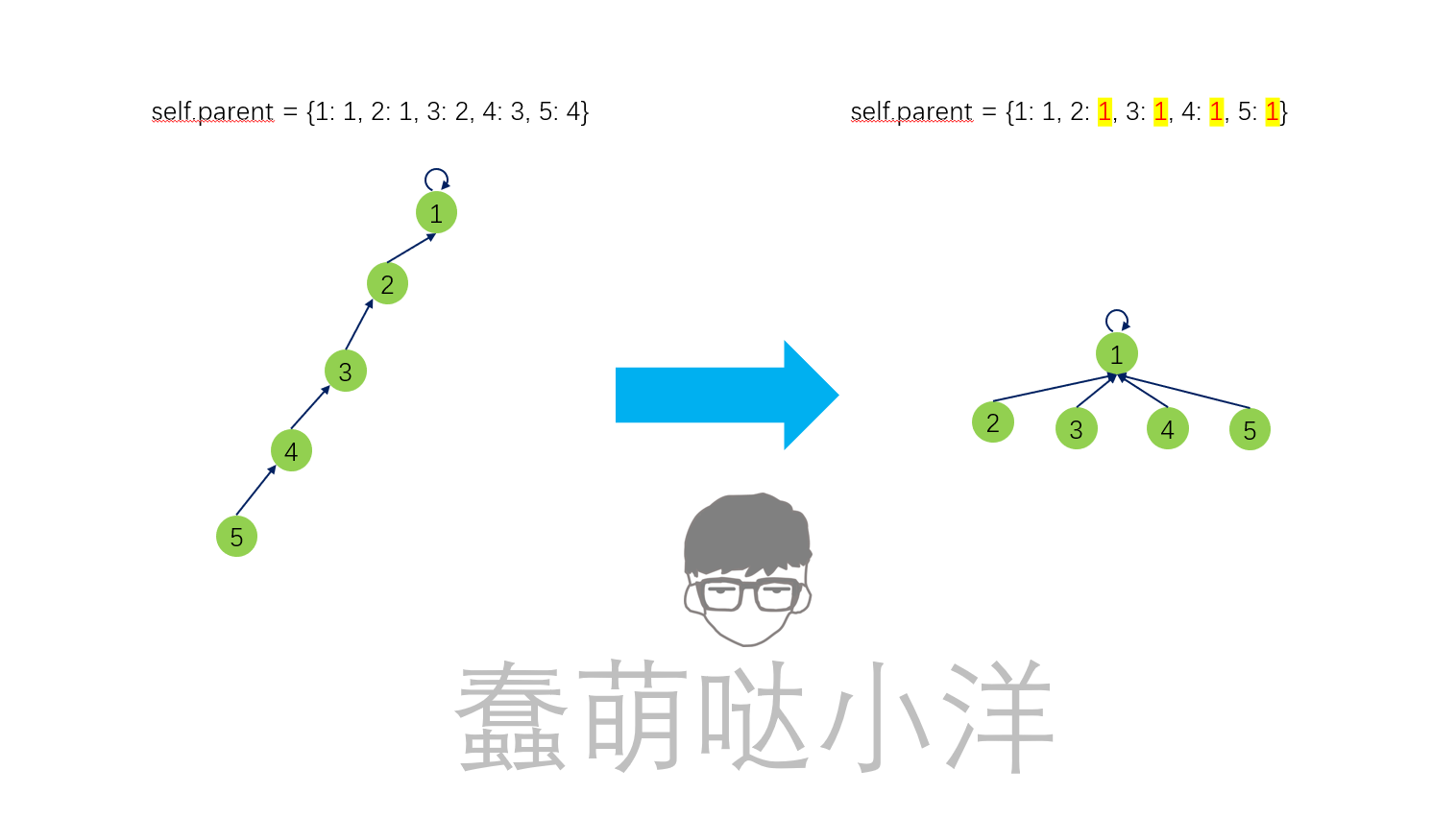
此时,find()方法的时间复杂度降到了o(1):
第一次查询find(num), 得到父节点就是最终父节点n,
会再次调用find(n), 方法直接结束,因此最多只会调用两次
优化二:压缩树高度
还是按照上节的分析, 可以通过矮树插高树的模式降低树高
需要根据height[num]的值来决定谁做主分支
因为这题weight是用来记录元素个数的,需要另外一个数组height来记录树高,最终union返回的还是weight[num]
注意:除了两者等高时,结合后的树高度会加一,剩下无论谁并谁都不会改变树高。
太多了,就不写了。。。
总结:
并查集模板:
class UnionFindSet {
Map1 parent; //记录元素的父节点【或者根节点】
Map2 weight; //记录每个集合的树高
int count; //记录集合个数
//其他属性根据题意灵活改变
//如,本题需要求最大子集的元素个数,因此需要一个记录每个集合元素个数的map
public UnionFindSet (集合nums) {
//初始化
parent = {num: num};
height = {num: 1};
count = nums.size();
}
int find(int num) {
int f = parent.get(num);
if (num == f) return num;
parent.set(num, find(f));
return parent.get(num);
}
void union(int n1, int n2) {
int r1 = find(n1), r2 = find(n2);
if (r1 == r2) return;
h1 = height.get(r1);
h2 = height.get(r2);
//除了两者等高的情况,高度都不会改变
if (h1 < h2) {
parent.put(r1, r2);
} else if (h1 > h2) {
parent.put(r2, r1);
} else {
parent.put(r2, r1);
height.put(r1, h1 + 1);
}
//集合个数减一
count--;
}
}
ght.get(r2);
//除了两者等高的情况,高度都不会改变
if (h1 < h2) {
parent.put(r1, r2);
} else if (h1 > h2) {
parent.put(r2, r1);
} else {
parent.put(r2, r1);
height.put(r1, h1 + 1);
}
//集合个数减一
count--;
}
}

















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









