







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
java代码的执行分为两步:
(1)通过javac前端编译器将源码编译为class字节码;
(2)通过解释器和JIT编译器将字节码变成机器码执行。
机器不能识别字节码,字节码比起机器语言,更像是一层更加抽象的语言,他的这种抽象性是为了实现跨平台而实现的。
java的编译是一个具有语境的词语,共有三种意思:
(1)javac将java文件编译为字节码文件;
(2)JIT编译器将字节码编译为机器语言;
(3)AOT编译器直接将java文件编译为机器语言。

复习一下字节码的位置:存于方法区,解释执行时由PC寄存器记录下条指令的行号。
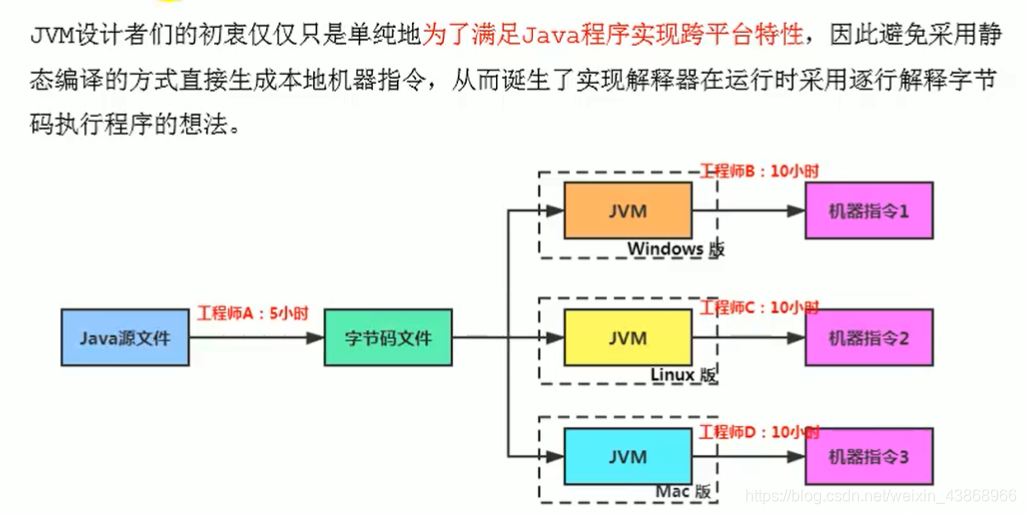
一、java执行过程
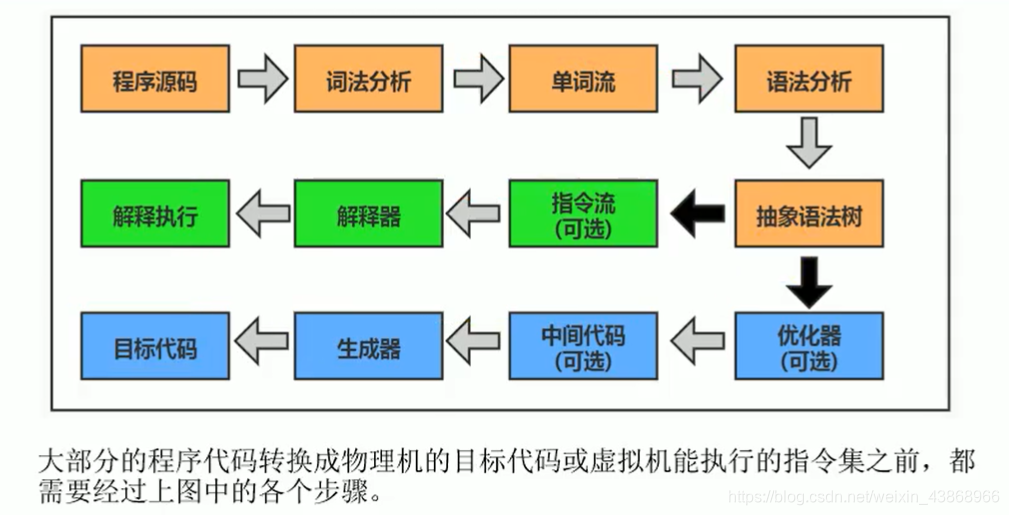
橙色:Javac编译为字节码文件。
绿色:解析器将字节码文件按行执行。
蓝色:后端编译器JIT将字节码文件统一翻译为机器码后再执行。
起初的Java语言(1.0版本)只有解释器,执行起来速度很慢。
后来在JVM增加了编译器,解释器可以和编译器协同工作,当解释执行过程高频的代码被发现时,优先将其编译为机器码存放到缓冲,之后就不用解释执行了,直接去缓冲区取机器码执行。

执行示意图:
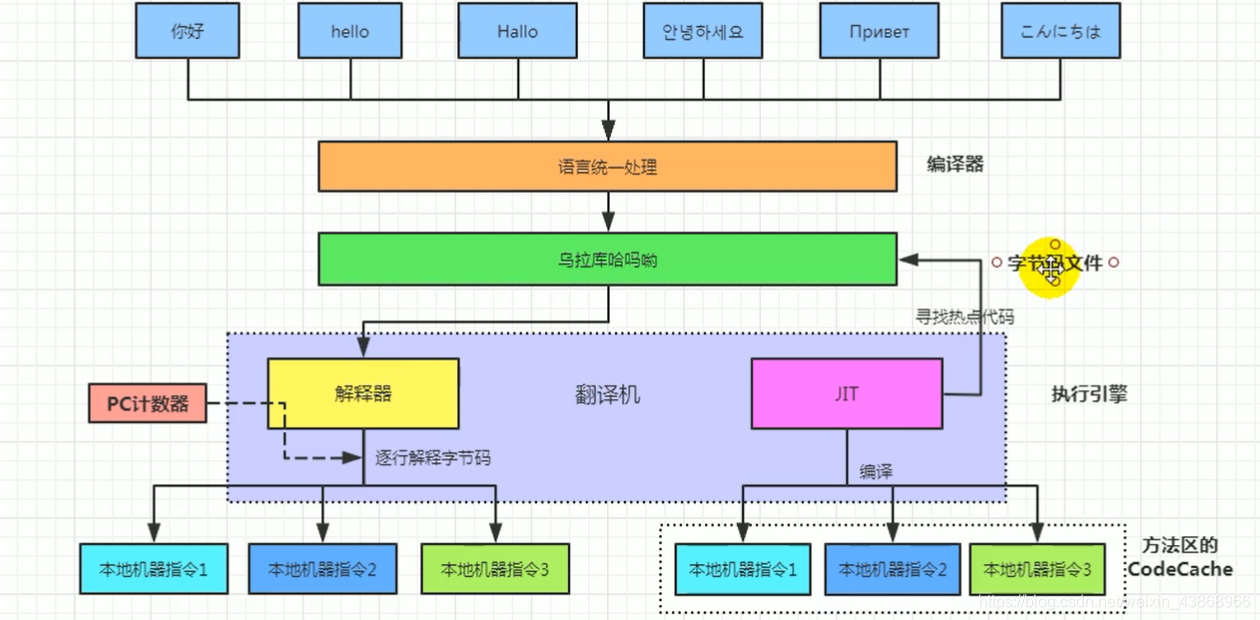
二、机器码、汇编语言、字节码
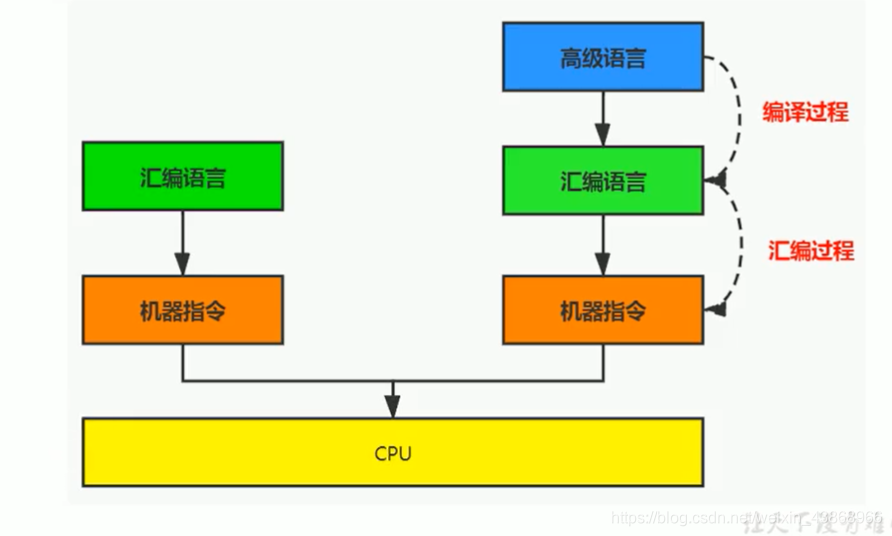
机器码:0-1代码,不同计算机因为硬件的差别,机器码的指令也有所差别。
汇编语言:将一个指令变成助记符,翻译为机器码才能执行【这个翻译过程叫做汇编】
高级语言:需要翻译成汇编语言【这个翻译过程叫做编译】,在转化为汇编语言执行时的情况。
不论何时,计算机唯一能够看懂的只有机器码。
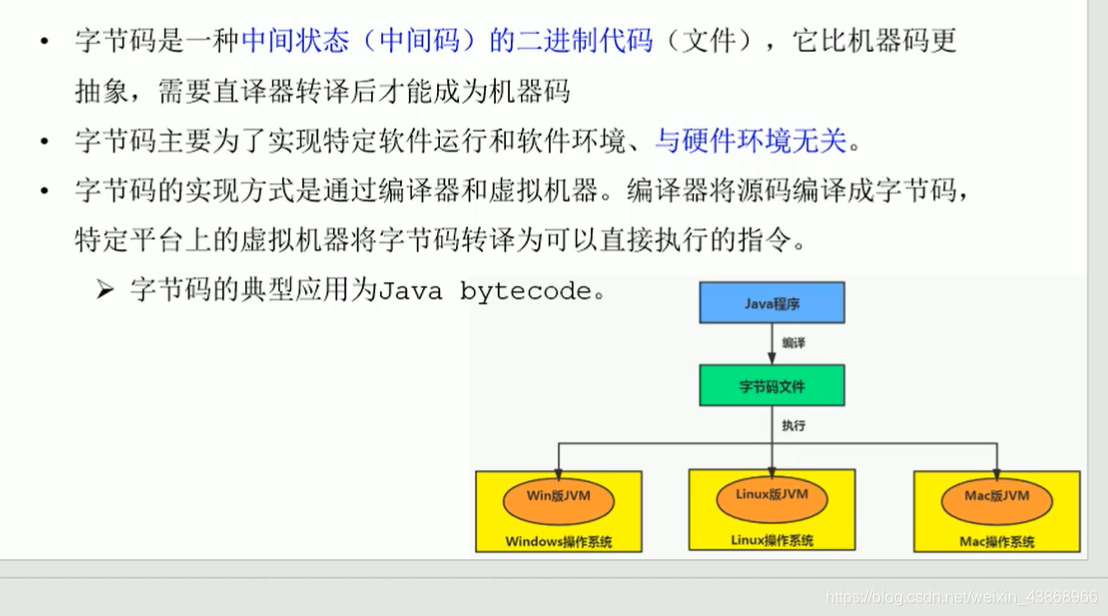
字节码:这是JVM类语言特有的文件,是一种位于机器码与高级语言的中间状态,在执行时由执行引擎进行翻译机器码处理
【这是java跨平台的关键。因为不同平台class文件的格式都是一样的,只是在具体平台的执行过程中,执行引擎会根据OS提供的指令进行翻译为机器码,因此对于上层来说就无视了平台差别】
三、解释器
最初选择解释程序的原因是为了实现跨平台。
现在还保留解释器的原因是而为了增加代码执行的响应速度。
解释器的执行特定是:
将每个本语言指令通过较高效的底层语言进行映射,即将一个简单的单词或者短语变成一个c的函数,因此在解释器的实现中有大量 if(xxx) {c函数}的样子。【python解释器就是这样的原理】

解释执行的最大毛病就是慢,但是实现简单。因为慢常常被c/c++程序员嘲讽。
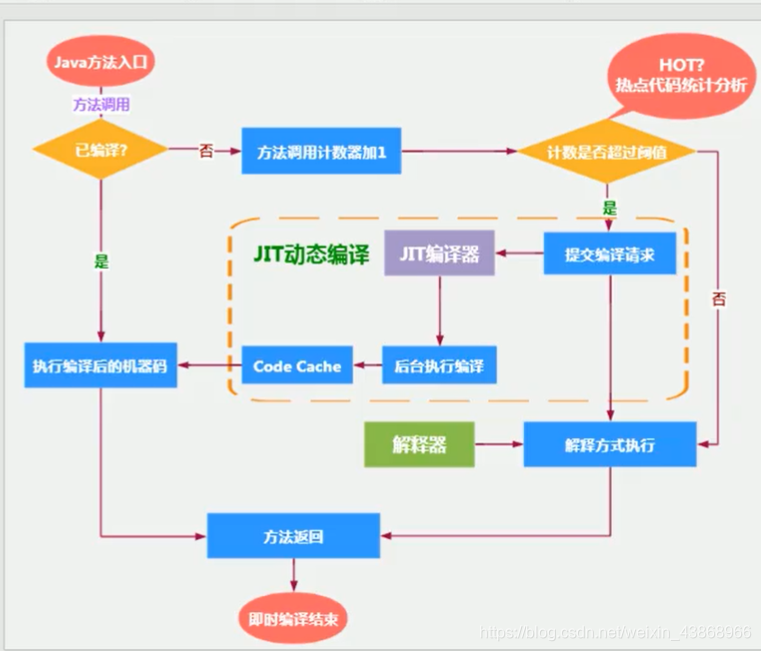
四、JIP编译器
JIP是执行引起的即时编译器(Just In Time).
编译是指一次将整个字节码文件翻译为机器码,因为其中要等待编译结束,程序会卡在那里,因此最大的缺点是响应时间长。
JRockit虚拟机完全只使用编译模式。
而HotSpot将两者都保留了。

两者保留的好处是,不仅响应时间快,而且随着程序的推进,会在运行过程中逐渐将解释方法转为编译器的缓存字节码。这样,在极少等待的情况下就能享受高效的运行速度。

OSR编译(On Stack Repalce),即栈上替换。指的是一个程序的方法计数器和回边计数器之和达到阈值,就有资格进行编译,下次执行这段程序时栈帧中的方法引用会动态地替换为编译的机器码缓存的地址。
作为程序是解释执行还是编译执行的标准,主要依靠:方法调用计数器、回边计数器。

方法调用计数器是针对方法而言的,一个方法在一定时间内被调用10000次(server)。

半衰周期:
为了防止执行时间过长,因为累计而造成的计数器达到阈值,这样对热点代码的判断就不太准确了。
执行引擎还会在GC时将指定时间长度不在执行的方法的方法调用计数器减半,这个时间长度叫做半衰周期。【一只蜗牛一只爬一晚上也能爬个几十米,显然不能说蜗牛很快】

减半的时机是在GC时期。
回边计数器:
回边针对的是循环中的代码。
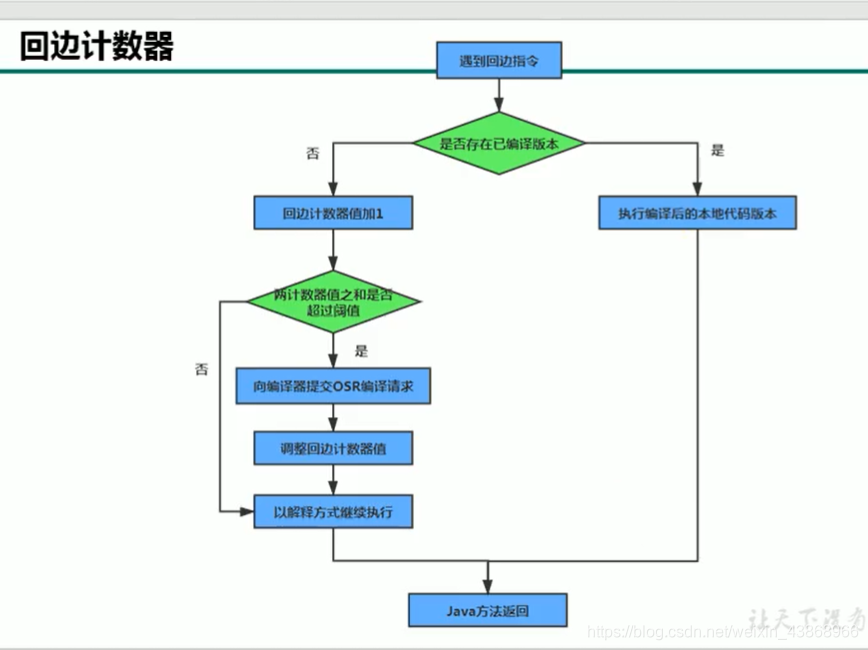
OSR的触发是回边 + 方法调用计数 > 阈值
五、模式切换
默认情况下为混合模式:即解释器和编译器同步执行
切换解释模式:-Xint
切换编译模式:-Xcomp切换混合模式:-Xmixed`
case:使用一段100000次循环的代码来展示各种执行方式的差别。
public static void main(String[] args) {
long start = System.currentTimeMillis();
int count = 0;
for (int i = 0; i < 1000000; i++) {
count = countPrimeNumber();
}
System.out.println(count);
System.out.println(System.currentTimeMillis() - start);
}
private static int countPrimeNumber() {
int count = 0;
label:for (int i = 2; i <= 100 ; i++) {
boolean flag = false;
for (int j = 2; j <= Math.sqrt(i); j++) {
if (i % j == 0) {
flag = true;
continue label;
}
}
if (!flag) {
count++;
}
}
return count;
}
混合模式:

解释模式:

编译模式:
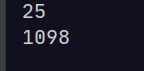
可见,编译模式最快,混合模式也差不多【因为其中只有百分之一执行解释】,解释模式最慢。
Server模式与Client模式:
Server模式更加在乎代码优化的深度,他不注重执行的响应速度,而是要将代码优化到执行性能最高的级别。Server模式使用C2编译器【JIT的一种,C2编译器是c++实现的】
Client更注重响应速度,代码优化程度较低,基于C1编译器。

Server模式不支持六十四位操作系统,设置了client模式也会被忽略。
分层编译:解释执行时使用C1编译,开启监控后采用C2深度优化。

六、其他编译器
(1)Graal是一个新秀JIT编译器,几年时间就有C2的性能。

(2)AOT编译器
及Ahead of Time, 与JIT(just in time)相对,表示在程序执行之前就已经转化为机器码了。
利用Graal编译器直接将输入的字节码文件转为机器码,而不是依靠运行时根据系统环境进行适应改变,因此程序启动可以直接使用缓存中的机器码,效率很高。
缺点时由于机器码不是运行时生成的,因此机器码只能运行在之前生成这个机器码的机器上,失去了java跨平台的特性。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









