







 本文介绍了作者如何使用Python爬取携程机票信息,并将结果存储在MariaDB数据库中,然后通过邮件发送到指定邮箱。项目采用CentOS7.7服务器,利用Crontab定时任务执行爬虫和邮件发送。爬虫初学者通过该项目了解了爬虫的基本工作流程。
本文介绍了作者如何使用Python爬取携程机票信息,并将结果存储在MariaDB数据库中,然后通过邮件发送到指定邮箱。项目采用CentOS7.7服务器,利用Crontab定时任务执行爬虫和邮件发送。爬虫初学者通过该项目了解了爬虫的基本工作流程。
0x0 前言
在疫情发生之前,在知乎上刷到一个回答,说是用服务器实现一个自动爬取机票并将过滤后的机票信息发送到自己的邮箱中,感觉十分有趣。由于疫情原因无法返校,加上家和学校相隔接近3000公里,再加上阿里云送服务器。于是想起了这个idea。
0x1 实现思路
- 服务器镜像选择的是centos7.7,个人比较喜欢centos,因为可以直接通过root用户操作。
- 爬取机票信息,选取了携程作为数据源。
- 存放机票信息,选择Mariadb。
- 发送机票信息邮件到我的邮箱。
基于以上选择,在Ubuntu18.04平台上使用python作为开发语言。大概的结构如下图。
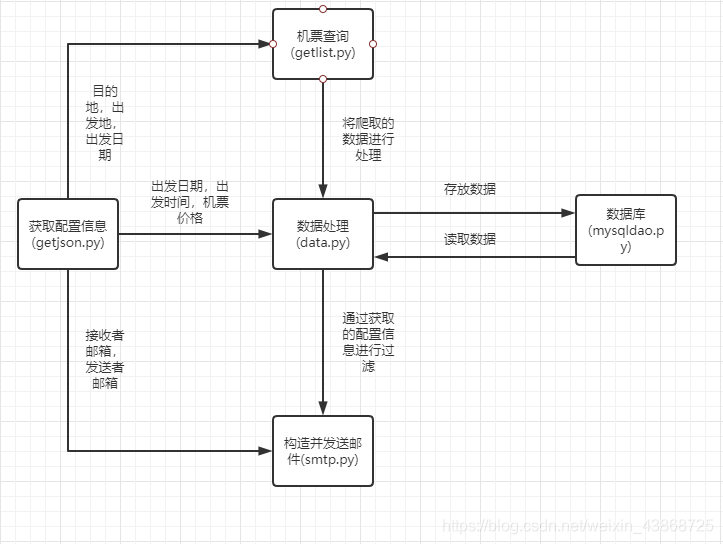
0x2 实现过程
-
阿里云服务器的领取就比较简单了,不再赘述。
-
爬取机票信息需要爬虫,但爬虫对我来说完全是一个全新的知识,事先找了很多资料,发现很多文章都注重如何防止爬虫被识别。但在我的想法中这个项目每隔一天爬取一次数据就足够了。所以在这两个文章的帮助下,成功的完成了爬取机票信息的过程。Python3爬虫基础实战篇之机票数据采集,Python爬取携程机票代码实例。因为对这方面也不是很熟悉,所以在这里就不涉及分析的过程了。
#coding:utf-8 #getllist.py import log import requests import getjson import json # 获取艺龙机票信息 def getlylist(): data=getjson.getcity() # 获取查询需要的请求数据 Departure=str(data[0]) # 出发机场三字码 DepartureName=str(data[1]) # 出发城市名 Arrival=str(data[2]) # 到达机场三字码 ArrivalName=str(data[3]) # 到达城市名 DepartureDate=str(data[4]) # 出发日期 try: url = "https://www.ly.com/flights/api/getflightlist" headers = { "Cookie":"__ftoken=nH1p4OADy%2BhIyjjDXqd7UuCg97ZyEvHWEuua31Q9G2zMeSBPRpzk3a%2FuWEIc7QlNqnha2ncAIbeEOHQQFPWvlA%3D%3D; __ftrace=efde5834-4ae4-45e4-8f55-8942d7304bf8; _dx_uzZo5y=696e7d7c4d7cb8e724cb154e92fd6d27e1fec611898ed7f00d27f905a63c9f8e672f2a0f; _dx_app_bc4b3ca6ae27747981b43e9f4a6aa769=5ed9ea6bGCjbBOcZ1O2OOVzPEPgKWXPp6E1Dv5g1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36 Edg/83.0.478.44", } data = { "Departure":Departure,"Arrival":Arrival,"GetType":"1","QueryType":"1","DepartureDate":DepartureDate, "DepartureName":DepartureName,"ArrivalName":ArrivalName,"IsBaby":0, "paging":{ "cid":"8f272df1-5931-48bb-b5bd-8d5181339194","dataflag":"some"}, "DepartureFilter":"","ArrivalFilter":"","flat":"465","plat":"465","isFromKylin":1,"refid":"" } html = requests.post(url, headers=headers,data=data).text log.info("Crawling information from ly succeeded") return html except: log.error("Failed to crawl information from ly") # 获取携程机票信息 def getcxlist(): data=getjson.getcity() # 获取查询需要的请求数据 Departure=str(data[0]) # 出发机场三字码 DepartureName=str(data[1]) # 出发城市名 Arrival=str(data[2]) # 到达机场三字码 ArrivalName=str(data[3]) # 到达城市名 DepartureDate=str(data[4]) # 出发日期 try: url = "https://flights.ctrip.com/itinerary/api/12808/products" headers = { "Referer":"https://flights.ctrip.com/itinerary/oneway/"+Departure+"-"+Arrival+"?date="+DepartureDate, "User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:77.0) Gecko/20100101 Firefox/77.0", "Content-Type": "application/json" } data = { "flightWay":"Oneway", "classType":"ALL", "hasChild":False, "hasBaby":False, "searchIndex":1, "airportPar
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1919
1919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









