







前言
重点关注官方示例如何导入Onnx模型,相关API的用法;
1--代码
#include "argsParser.h"
#include "buffers.h"
#include "common.h"
#include "logger.h"
#include "parserOnnxConfig.h"
#include "NvInfer.h"
#include <cuda_runtime_api.h>
#include <cstdlib>
#include <fstream>
#include <iostream>
#include <sstream>
using samplesCommon::SampleUniquePtr;
const std::string gSampleName = "TensorRT.sample_onnx_mnist";
class SampleOnnxMNIST
{
public:
SampleOnnxMNIST(const samplesCommon::OnnxSampleParams& params): mParams(params), mEngine(nullptr){}
bool build();
bool infer();
private:
samplesCommon::OnnxSampleParams mParams;
nvinfer1::Dims mInputDims; // 网络的输入维度
nvinfer1::Dims mOutputDims; // 网络的输出维度
int mNumber{0}; // 类别数
std::shared_ptr<nvinfer1::ICudaEngine> mEngine; // 初始化engine
bool constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder,
SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config,
SampleUniquePtr<nvonnxparser::IParser>& parser);
// 前处理
bool processInput(const samplesCommon::BufferManager& buffers);
// 验证结果
bool verifyOutput(const samplesCommon::BufferManager& buffers);
};
bool SampleOnnxMNIST::build()
{
// 创建 builder
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger()));
if (!builder)
{
return false;
}
// 显式 batch
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 创建network
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
if (!network)
{
return false;
}
// 创建config
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if (!config)
{
return false;
}
// 创建parser
auto parser = SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger()));
if (!parser)
{
return false;
}
// 调用成员函数生成网络
auto constructed = constructNetwork(builder, network, config, parser);
if (!constructed)
{
return false;
}
// CUDA stream used for profiling by the builder.
auto profileStream = samplesCommon::makeCudaStream(); // 创建Cuda stream
if (!profileStream)
{
return false;
}
config->setProfileStream(*profileStream);
SampleUniquePtr<IHostMemory> plan{builder->buildSerializedNetwork(*network, *config)}; // 创建推理引擎
if (!plan)
{
return false;
}
SampleUniquePtr<IRuntime> runtime{createInferRuntime(sample::gLogger.getTRTLogger())}; // 创建Runtime接口
if (!runtime)
{
return false;
}
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(plan->data(), plan->size()), samplesCommon::InferDeleter());
if (!mEngine)
{
return false;
}
ASSERT(network->getNbInputs() == 1); // 输入 batch 为1
mInputDims = network->getInput(0)->getDimensions();
ASSERT(mInputDims.nbDims == 4); // 输入维度为 4(包含 batch 维度)
ASSERT(network->getNbOutputs() == 1); // 输出 batch 为1
mOutputDims = network->getOutput(0)->getDimensions();
ASSERT(mOutputDims.nbDims == 2); // 输出维度为 2
return true;
}
// constructNetwork 成员函数实现
bool SampleOnnxMNIST::constructNetwork(SampleUniquePtr<nvinfer1::IBuilder>& builder,
SampleUniquePtr<nvinfer1::INetworkDefinition>& network, SampleUniquePtr<nvinfer1::IBuilderConfig>& config,
SampleUniquePtr<nvonnxparser::IParser>& parser)
{
auto parsed = parser->parseFromFile(locateFile(mParams.onnxFileName, mParams.dataDirs).c_str(),
static_cast<int>(sample::gLogger.getReportableSeverity())); // 解析onnx模型
if (!parsed)
{
return false;
}
config->setMaxWorkspaceSize(16_MiB); // 设置最大工作空间
if (mParams.fp16) // 设置精度
{
config->setFlag(BuilderFlag::kFP16);
}
if (mParams.int8)
{
config->setFlag(BuilderFlag::kINT8);
samplesCommon::setAllDynamicRanges(network.get(), 127.0f, 127.0f);
}
samplesCommon::enableDLA(builder.get(), config.get(), mParams.dlaCore);
return true;
}
bool SampleOnnxMNIST::infer()
{
// 创建内存管理
samplesCommon::BufferManager buffers(mEngine);
// 创建context
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
if (!context)
{
return false;
}
// 从 buffer 中读取数据,并进行前处理
ASSERT(mParams.inputTensorNames.size() == 1);
if (!processInput(buffers))
{
return false;
}
// 将数据复制到 GPU 中
buffers.copyInputToDevice();
bool status = context->executeV2(buffers.getDeviceBindings().data()); // 执行推理
if (!status)
{
return false;
}
// 将结果复制到 CPU 中
buffers.copyOutputToHost();
// 验证推理结果
if (!verifyOutput(buffers))
{
return false;
}
return true;
}
// 前处理成员函数实现
bool SampleOnnxMNIST::processInput(const samplesCommon::BufferManager& buffers) // 传入 buffers 的引用
{
const int inputH = mInputDims.d[2];
const int inputW = mInputDims.d[3];
// 随机选择一个数据进行读取
srand(unsigned(time(nullptr)));
std::vector<uint8_t> fileData(inputH * inputW);
mNumber = rand() % 10;
readPGMFile(locateFile(std::to_string(mNumber) + ".pgm", mParams.dataDirs), fileData.data(), inputH, inputW);
// Print an ascii representation
sample::gLogInfo << "Input:" << std::endl;
for (int i = 0; i < inputH * inputW; i++)
{
sample::gLogInfo << (" .:-=+*#%@"[fileData[i] / 26]) << (((i + 1) % inputW) ? "" : "\n");
}
sample::gLogInfo << std::endl;
// buffers.getHostBuffer() 返回 Name 对应的 buffer 地址
float* hostDataBuffer = static_cast<float*>(buffers.getHostBuffer(mParams.inputTensorNames[0]));
for (int i = 0; i < inputH * inputW; i++) // 对这段 buffer 地址的内容进行赋值操作,由于 processInput() 函数传入的是buffer引用,所以能改变buffer的值
{
hostDataBuffer[i] = 1.0 - float(fileData[i] / 255.0);
}
return true;
}
// 验证推理结果的成员函数实现
bool SampleOnnxMNIST::verifyOutput(const samplesCommon::BufferManager& buffers)
{
const int outputSize = mOutputDims.d[1];
float* output = static_cast<float*>(buffers.getHostBuffer(mParams.outputTensorNames[0]));
float val{0.0f};
int idx{0};
// Calculate Softmax
float sum{0.0f};
for (int i = 0; i < outputSize; i++)
{
output[i] = exp(output[i]);
sum += output[i];
}
sample::gLogInfo << "Output:" << std::endl;
for (int i = 0; i < outputSize; i++)
{
output[i] /= sum;
val = std::max(val, output[i]);
if (val == output[i])
{
idx = i;
}
sample::gLogInfo << " Prob " << i << " " << std::fixed << std::setw(5) << std::setprecision(4) << output[i]
<< " "
<< "Class " << i << ": " << std::string(int(std::floor(output[i] * 10 + 0.5f)), '*')
<< std::endl;
}
sample::gLogInfo << std::endl;
return idx == mNumber && val > 0.9f;
}
// 初始化参数
samplesCommon::OnnxSampleParams initializeSampleParams(const samplesCommon::Args& args)
{
samplesCommon::OnnxSampleParams params; // 创建参数对象
if (args.dataDirs.empty()) //!< Use default directories if user hasn't provided directory paths
{
params.dataDirs.push_back("data/mnist/");
params.dataDirs.push_back("data/samples/mnist/");
}
else //!< Use the data directory provided by the user
{
params.dataDirs = args.dataDirs;
}
// 设置参数对象的默认属性
params.onnxFileName = "mnist.onnx";
params.inputTensorNames.push_back("Input3");
params.outputTensorNames.push_back("Plus214_Output_0");
params.dlaCore = args.useDLACore;
params.int8 = args.runInInt8;
params.fp16 = args.runInFp16;
return params;
}
// 打印参数信息
void printHelpInfo()
{
std::cout
<< "Usage: ./sample_onnx_mnist [-h or --help] [-d or --datadir=<path to data directory>] [--useDLACore=<int>]"
<< std::endl;
std::cout << "--help Display help information" << std::endl;
std::cout << "--datadir Specify path to a data directory, overriding the default. This option can be used "
"multiple times to add multiple directories. If no data directories are given, the default is to use "
"(data/samples/mnist/, data/mnist/)"
<< std::endl;
std::cout << "--useDLACore=N Specify a DLA engine for layers that support DLA. Value can range from 0 to n-1, "
"where n is the number of DLA engines on the platform."
<< std::endl;
std::cout << "--int8 Run in Int8 mode." << std::endl;
std::cout << "--fp16 Run in FP16 mode." << std::endl;
}
int main(int argc, char** argv)
{
samplesCommon::Args args;
bool argsOK = samplesCommon::parseArgs(args, argc, argv);
if (!argsOK)
{
sample::gLogError << "Invalid arguments" << std::endl;
printHelpInfo();
return EXIT_FAILURE;
}
if (args.help)
{
printHelpInfo();
return EXIT_SUCCESS;
}
auto sampleTest = sample::gLogger.defineTest(gSampleName, argc, argv);
sample::gLogger.reportTestStart(sampleTest);
SampleOnnxMNIST sample(initializeSampleParams(args)); // 创建对象
sample::gLogInfo << "Building and running a GPU inference engine for Onnx MNIST" << std::endl;
if (!sample.build())
{
return sample::gLogger.reportFail(sampleTest);
}
if (!sample.infer())
{
return sample::gLogger.reportFail(sampleTest);
}
return sample::gLogger.reportPass(sampleTest);
}
2--编译
① CMakeLists.txt:
cmake_minimum_required(VERSION 3.13)
project(TensorRT_test)
set(CMAKE_CXX_STANDARD 11)
set(SAMPLES_COMMON_SOURCES "/home/liujinfu/Downloads/TensorRT-8.2.5.1/samples/common/logger.cpp")
add_executable(TensorRT_test_OnnxMNIST sampleOnnxMNIST.cpp ${SAMPLES_COMMON_SOURCES})
# add TensorRT8
include_directories(/home/liujinfu/Downloads/TensorRT-8.2.5.1/include)
include_directories(/home/liujinfu/Downloads/TensorRT-8.2.5.1/samples/common)
set(TENSORRT_LIB_PATH "/home/liujinfu/Downloads/TensorRT-8.2.5.1/lib")
file(GLOB LIBS "${TENSORRT_LIB_PATH}/*.so")
# add CUDA
find_package(CUDA 11.3 REQUIRED)
message("CUDA_LIBRARIES:${CUDA_LIBRARIES}")
message("CUDA_INCLUDE_DIRS:${CUDA_INCLUDE_DIRS}")
include_directories(${CUDA_INCLUDE_DIRS})
# link
target_link_libraries(TensorRT_test_OnnxMNIST ${LIBS} ${CUDA_LIBRARIES})② 编译
mkdir build && cd build
cmake ..
make3--运行结果
./TensorRT_test_OnnxMNIST -d /home/liujinfu/Downloads/TensorRT-8.2.5.1/data/mnist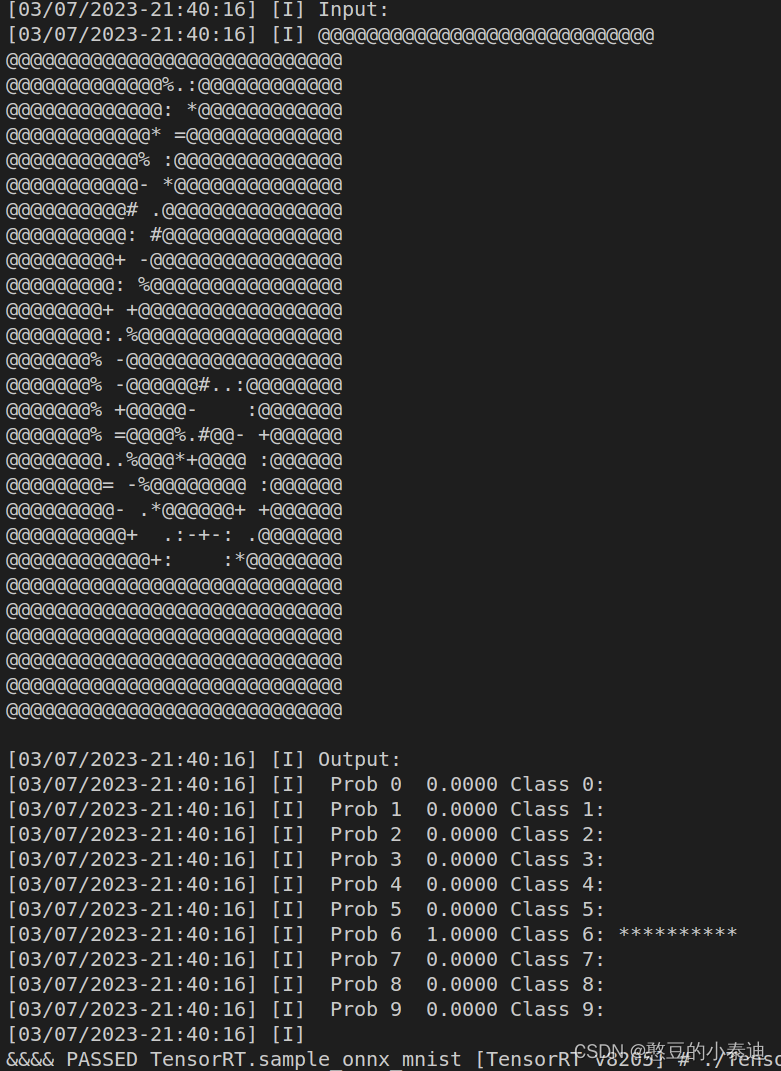


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









