







 本文详细介绍了杭州地铁5号站点的流量预测过程,包括数据预处理、筛选特定时间段内的进出站人数,并绘制了流量趋势图进行可视化展示。
本文详细介绍了杭州地铁5号站点的流量预测过程,包括数据预处理、筛选特定时间段内的进出站人数,并绘制了流量趋势图进行可视化展示。
杭州地铁流量预测之数据预处理
----地铁数据处理
import pandas as pd
import csv
for i in range(13,24):
Date = '%02d'%i
print(Date)
Date = str(Date)
discfile = 'C:\\Users\\11202\\Desktop\\大数据分析方法\\subway_predict\\地铁\\record_2019-01-'+Date+'.csv'
# 读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式
data = pd.read_csv(discfile)
data_beifen = data
#data['time'] = pd.to_datetime(data['time'])
#station_ID=input("Please Enter The Station ID:\n")
station_ID = 5
i_1_1 = 0
i_1_2 = 0
i_2_1 = 0
i_2_2 = 10
every_number = 0
station_ID_status_1 = 0
station_ID_status_0 = 0
i_1_1 = str(i_1_1)
i_1_2 = str(i_1_2)
i_2_1 = str(i_2_1)
i_2_2 = str(i_2_2)
with open('C:\\Users\\11202\\Desktop\\大数据分析方法\\subway_predict\\地铁_2\\5_station_ahhh.csv', 'a+', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
data = data[(pd.to_datetime(data['time'], format='%Y-%m-%d %H:%M:%S') >= pd.to_datetime(
'2019-1-'+Date+' ' + i_1_1 + ':' + i_1_2 + ':00', format='%Y-%m-%d %H:%M:%S')) & (
pd.to_datetime(data['time'], format='%Y-%m-%d %H:%M:%S') < pd.to_datetime(
'2019-1-'+Date+' ' + i_2_1 + ':' + i_2_2 + ':00', format='%Y-%m-%d %H:%M:%S'))]
#print(len(data))
every_number += len(data)
for i in range(len(data)):
if data['stationID'][i] == int(station_ID):
if data['status'][i] == 1:
station_ID_status_1 += 1
elif data['status'][i] == 0:
station_ID_status_0 += 1
csv_writer.writerow([data_beifen['time'][0],str(station_ID_status_0),str(station_ID_status_1)])
#print(station_ID_status_0,station_ID_status_1)
print(station_ID_status_0,station_ID_status_1)
data = data_beifen
i_1_1 = int(i_1_1)
i_1_2 = int(i_1_2)
i_2_1 = int(i_2_1)
i_2_2 = int(i_2_2)
with open('C:\\Users\\11202\\Desktop\\大数据分析方法\\subway_predict\\地铁_2\\5_station_ahhh.csv', 'a+', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
while i_2_1 <= 24:
station_ID_status_1 = 0
station_ID_status_0 = 0
i_1_2 += 10
i_2_2 += 10
if i_1_2 > 50:
i_1_2 = 0
i_1_1 += 1
if i_2_2 > 50:
i_2_1 += 1
i_2_2 = 0
#该if是因为24点时间与0点存在歧义,计算23:50-23:59:59的进出站人数
if i_2_1 == 24 and i_2_2 == 0:
i_1_1 = 23
i_1_2 = 50
i_2_1 = 23
i_2_2 = 59
i_1_1 = str(i_1_1)
i_1_2 = str(i_1_2)
i_2_1 = str(i_2_1)
i_2_2 = str(i_2_2)
data = data[(pd.to_datetime(data['time'], format='%Y-%m-%d %H:%M:%S') >= pd.to_datetime(
'2019-1-'+Date+' ' + i_1_1 + ':' + i_1_2 + ':00', format='%Y-%m-%d %H:%M:%S')) & (
pd.to_datetime(data['time'], format='%Y-%m-%d %H:%M:%S') <= pd.to_datetime(
'2019-1-'+Date+' ' + i_2_1 + ':' + i_2_2 + ':59', format='%Y-%m-%d %H:%M:%S'))]
# print(len(data))
i1 = len(data_beifen) - len(data)
for i in range(i1, len(data_beifen)):
if data['stationID'][i] == int(station_ID):
if data['status'][i] == 1:
station_ID_status_1 += 1
elif data['status'][i] == 0:
station_ID_status_0 += 1
csv_writer.writerow([data_beifen['time'][every_number], str(station_ID_status_0), str(station_ID_status_1)])
print(station_ID_status_0,station_ID_status_1)
break
time_1_1 = str(i_1_1)
time_1_2 = str(i_1_2)
time_2_1 = str(i_2_1)
time_2_2 = str(i_2_2)
data = data[(pd.to_datetime(data['time'], format='%Y/%m/%d %H:%M') >= pd.to_datetime('2019/1/'+Date+' ' + time_1_1 + ':' + time_1_2, format='%Y/%m/%d %H:%M')) & (pd.to_datetime(data['time'], format='%Y/%m/%d %H:%M') < pd.to_datetime('2019/1/'+Date+' ' + time_2_1 + ':' + time_2_2, format='%Y/%m/%d %H:%M'))]
#print(len(data))
for i in range(every_number,every_number+len(data)):
if data['stationID'][i] == int(station_ID):
if data['status'][i] == 1:
station_ID_status_1 += 1
elif data['status'][i] == 0:
station_ID_status_0 += 1
csv_writer.writerow([data_beifen['time'][every_number],str(station_ID_status_0), str(station_ID_status_1)])
every_number += len(data)
data = data_beifen
#print(station_ID_status_0, station_ID_status_1)
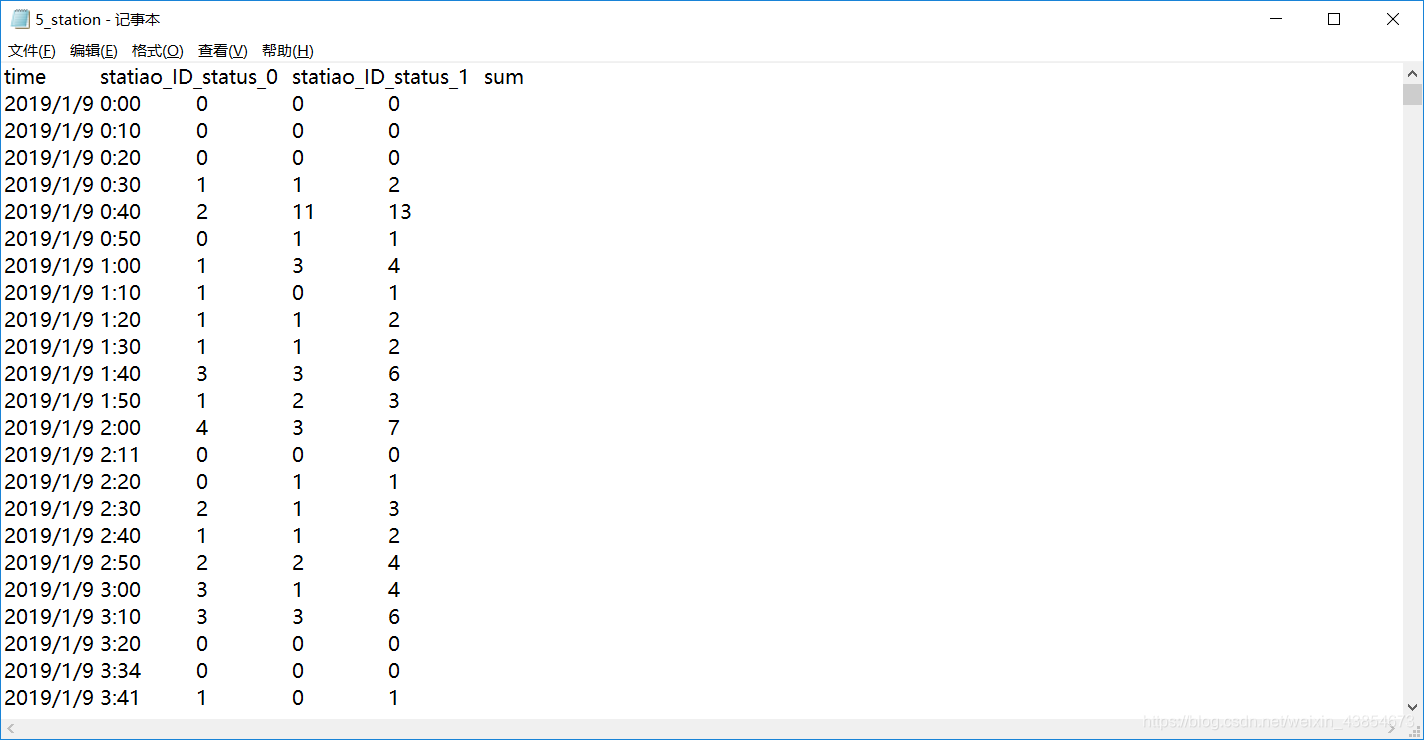
处理完成后站点5对应的保存文件
----地铁流量趋势图
# -*- coding: utf-8 -*-
#0为出站,1为进站
import pandas as pd
import matplotlib.pyplot as plt
#import matplotlib
import matplotlib.dates as mdate
#plt.rcParams['savefig.dpi'] = 500 #图片像素
#plt.rcParams['figure.dpi'] = 500 #分辨率
discfile = 'C:\\Users\\11202\\Desktop\\大数据分析方法\\subway_predict\\地铁_2\\5_station_copy.csv'
data = pd.read_csv(discfile)
data.time = pd.to_datetime(data.time, format = '%Y-%m-%d %H:%M:%S')
data.index = data.time
plt.rcParams['font.sans-serif']=['SimHei']#正常显示中文
plt.rcParams['axes.unicode_minus']=False#正常显示负号
fig = plt.figure()
ax = fig.add_subplot(111)
ax.xaxis.set_major_formatter(mdate.DateFormatter('%Y-%m-%d %H:%M:%S'))
plt.xticks(pd.date_range(data.index[0],data.index[-1],freq='D'),rotation=90)
ax.plot(data.index,data['sum'],color='r')
plt.show()

















 1290
1290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









