




 本文详细介绍了如何在IntelliJ IDEA中配置Maven,包括设置本地仓库优先级、修改Maven镜像等关键步骤,帮助开发者解决Maven配置过程中的常见问题。
本文详细介绍了如何在IntelliJ IDEA中配置Maven,包括设置本地仓库优先级、修改Maven镜像等关键步骤,帮助开发者解决Maven配置过程中的常见问题。
1.打开idea中的setting
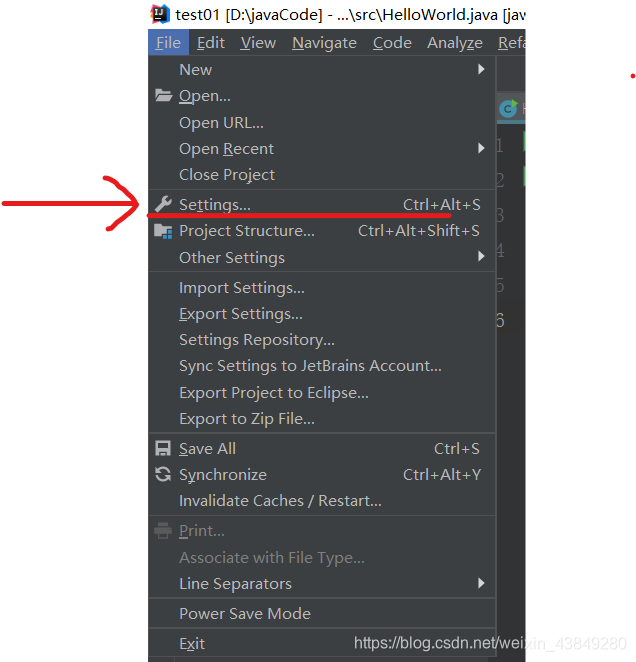
2.搜索框搜索maven,下面找到maven
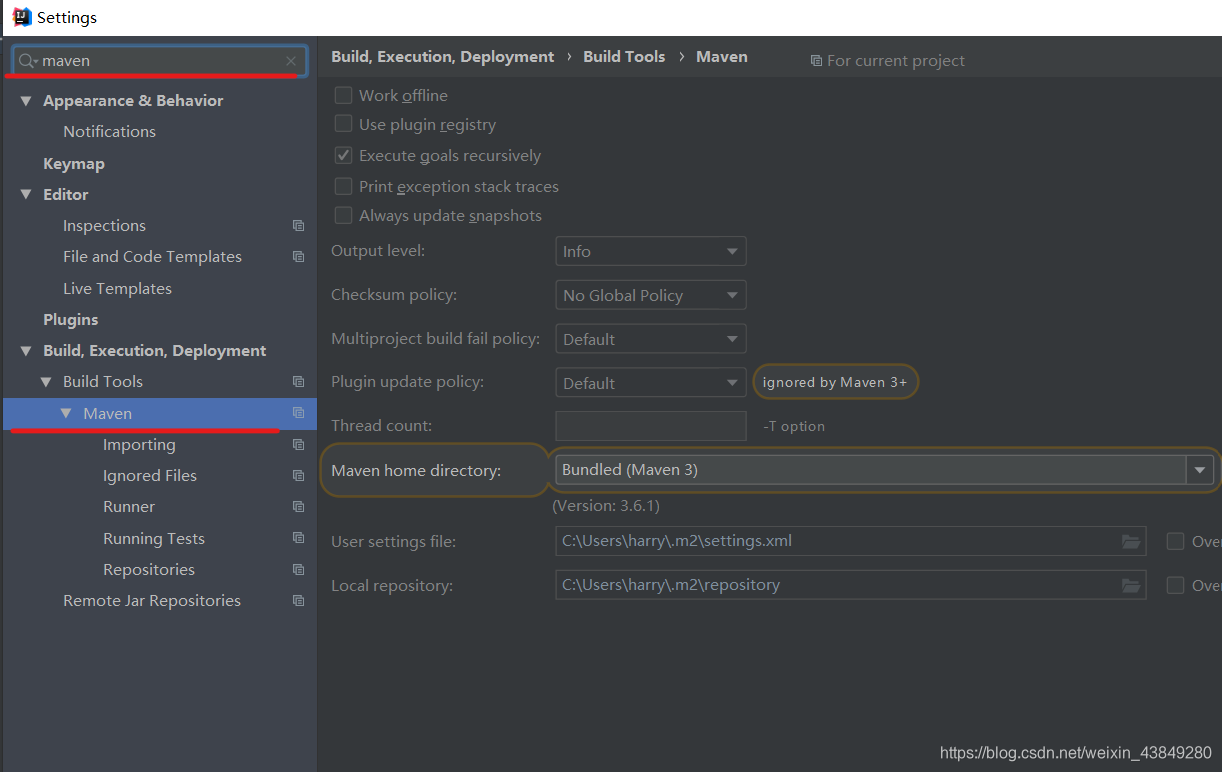
右侧显示就是maven的设置界面
3.配置maven
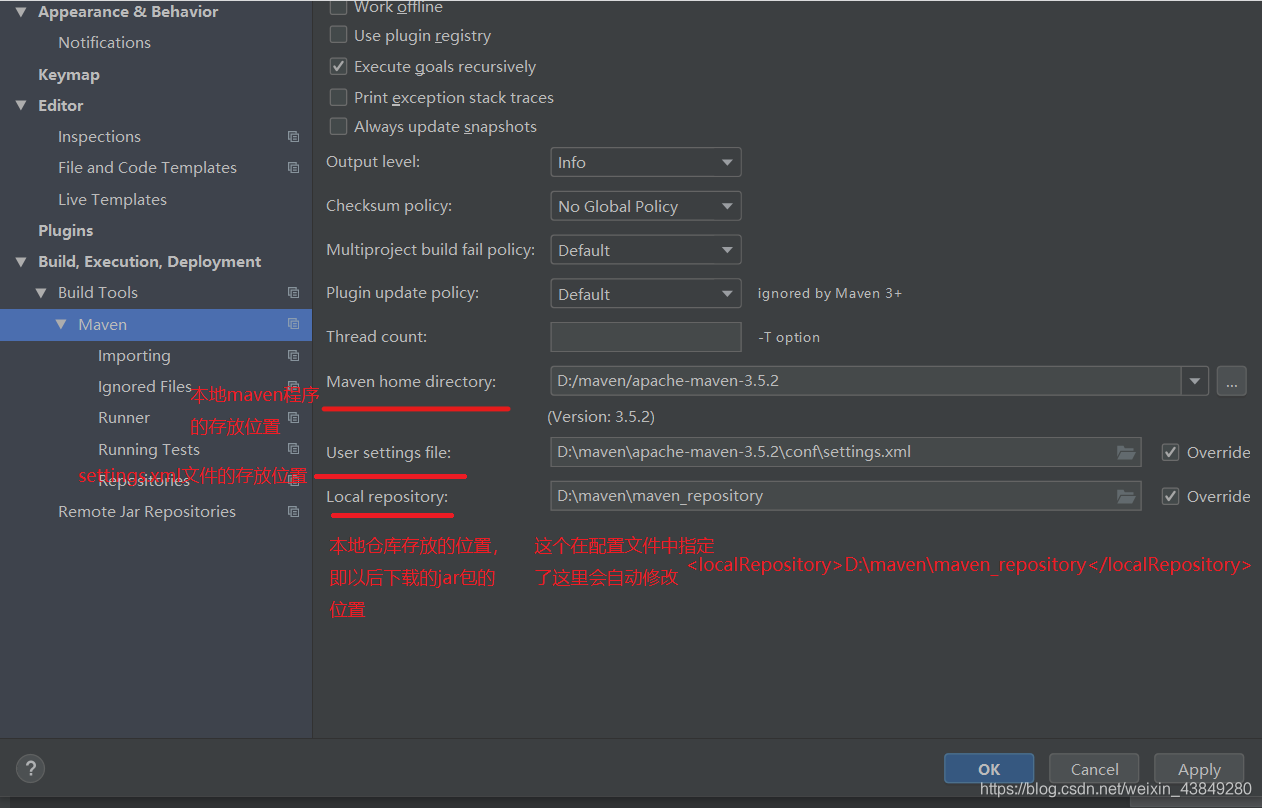
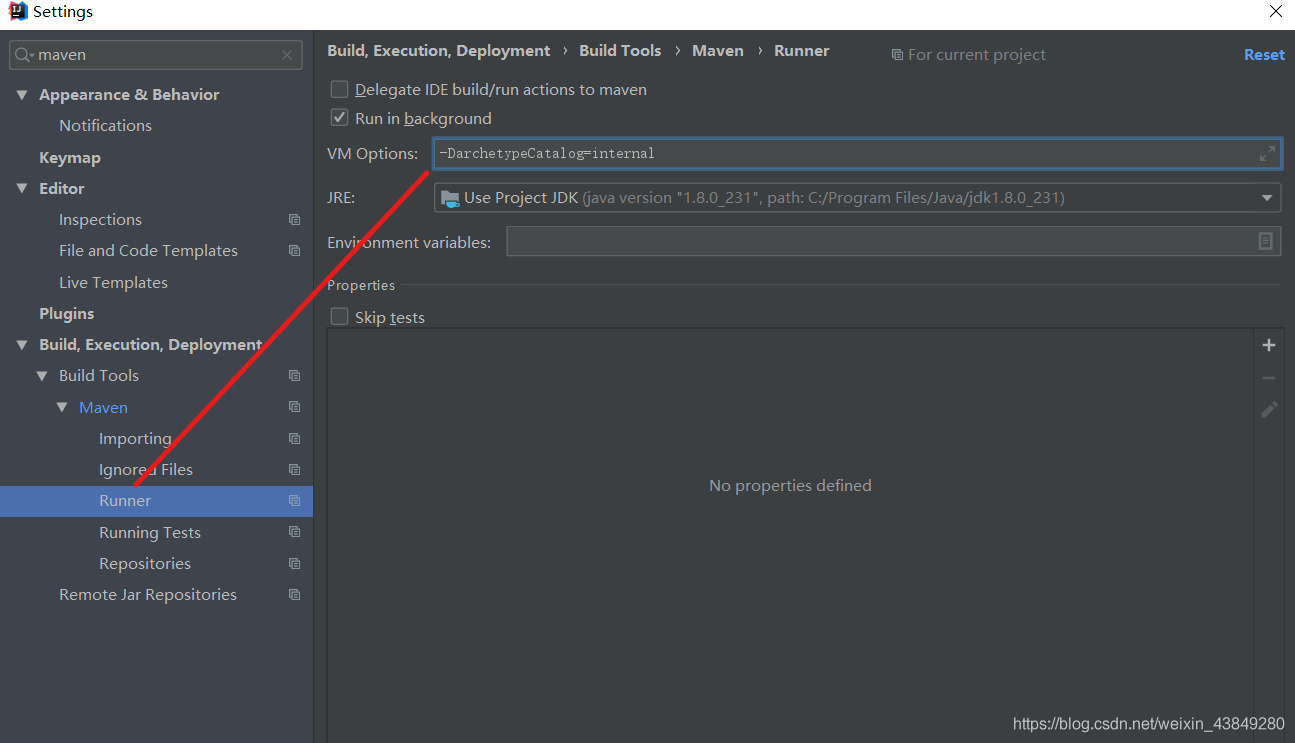
后续还需要配置一个地方是本地仓库的优先,在runner-VM Options里面填写一下代码
-DarchetypeCatalog=internal
5.如果想要修改maven的镜像,修改conf中的settings.xml文件
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
在mirror中按照规则添加就可以,例如下面的添加aliyun镜像,有些时候国内镜像会不全。
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>


















 19万+
19万+



 到【灌水乐园】发言
到【灌水乐园】发言







