




 本文详细解析了MySQL中的InnoDB、MyISAM和MEMORY存储引擎,探讨了存储引擎选择的重要性,介绍了事务的ACID特性及隔离级别,并剖析了并发控制和死锁处理。还涵盖了SQL操作,如replaceinto、UNIONALL和数据迁移技巧。
本文详细解析了MySQL中的InnoDB、MyISAM和MEMORY存储引擎,探讨了存储引擎选择的重要性,介绍了事务的ACID特性及隔离级别,并剖析了并发控制和死锁处理。还涵盖了SQL操作,如replaceinto、UNIONALL和数据迁移技巧。
mysql
1、mysql存储引擎
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以获得特定的功能。MySQL的核心就是存储引擎。
1、InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,InnoDB是默认的MySQL引擎。InnoDB主要特性有:
1、将数据存储在表空间中,表空间由一系列的数据文件组成,由InnoDb管理
2、支持每个表的数据和索引存放在单独文件中(innodb_file_per_table);
3、支持事务,采用MVCC来控制并发,并实现标准的4个事务隔离级别,支持外键。
4、索引基于聚簇索引建立,对主键查询有较高性能。
5、数据文件的平台无关性,支持数据在不同的架构平台移植
6、能够通过一些工具支持真正的热备,如XtraBackup等;
7、内部进行自身优化如采取可预测性预读,能够自动在内存中创建bash索引等
2、MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。MyISAM主要特性有:
1、MySQL5.1默认,不支持事务和行级锁
2、提供大量的特性如全文索引、空间函数、压缩、延迟更新等
3、数据库故障后,安全恢复性
4、对于只读数据可以忍受故障恢复,MyISAM依然非常适用
5、日志服务器的场景也比较适用,只需插入和数据读取操作
6、不支持单表一个文件,会将所有的数据和索引内容分别存放在两个文件中
7、MyISAM对整张表加锁而不是对行,所以不适用写操作比较多的场景
8、支持索引缓存不支持数据缓存
使用MyISAM引擎创建数据库,将产生3个文件。文件的名字以表名字开始,扩展名之处文件类型:frm文件存储表定义、数据文件的扩展名为.MYD(MYData)、索引文件的扩展名时.MYI(MYIndex)
3、MEMORY存储引擎
MEMORY存储引擎将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。MEMORY主要特性有:
1、MEMORY表的每个表可以有多达32个索引,每个索引16列,以及500字节的最大键长度
2、MEMORY存储引擎执行HASH和BTREE缩影
3、可以在一个MEMORY表中有非唯一键值
4、MEMORY表使用一个固定的记录长度格式
5、MEMORY不支持BLOB或TEXT列
6、MEMORY支持AUTO_INCREMENT列和对可包含NULL值的列的索引
7、MEMORY表在所由客户端之间共享(就像其他任何非TEMPORARY表)
8、MEMORY表内存被存储在内存中,内存是MEMORY表和服务器在查询处理时的空闲中,创建的内部表共享
9、当不再需要MEMORY表的内容时,要释放被MEMORY表使用的内存,应该执行DELETE FROM或TRUNCATE TABLE,或者删除整个表(使用DROP TABLE)
2、存储引擎的选择
不同的存储引擎都有各自的特点,以适应不同的需求,如下表所示:
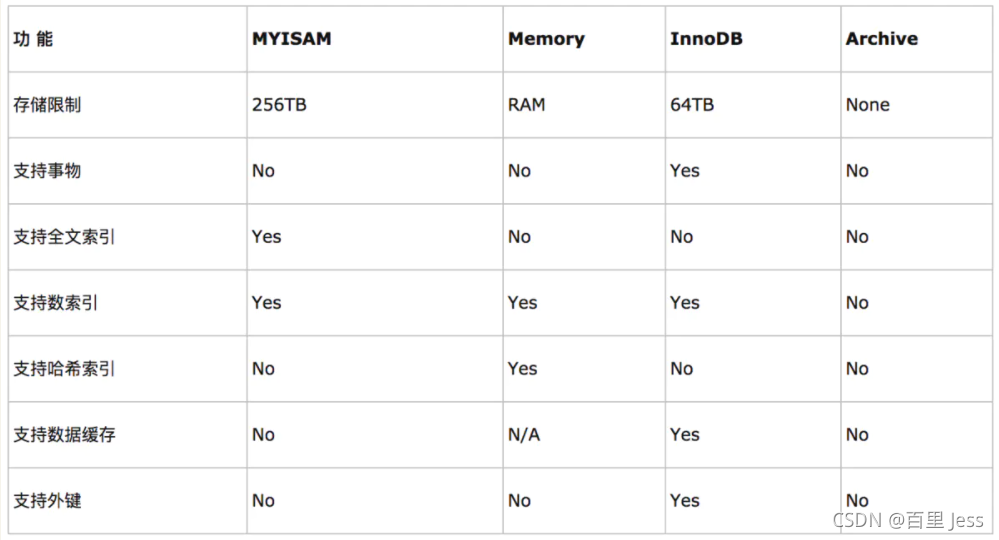
如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
3、并发控制和锁的概念
当数据库中有多个操作需要修改同一数据时,不可避免的会产生数据的脏读。这时就需要数据库具有良好的并发控制能力,这一切在MySQL中都是由服务器和存储引擎来实现的。
解决并发问题最有效的方案是引入了锁的机制,锁在功能上分为共享锁(shared lock)和排它锁(exclusive lock)即通常说的读锁和写锁。当一个select语句在执行时可以施加读锁,这样就可以允许其它的select操作进行,因为在这个过程中数据信息是不会被改变的这样就能够提高数据库的运行效率。当需要对数据更新时,就需要施加写锁了,不在允许其它的操作进行,以免产生数据的脏读和幻读。锁同样有粒度大小,有表级锁(table lock)和行级锁(row lock),分别在数据操作的过程中完成行的锁定和表的锁定。这些根据不同的存储引擎所具有的特性也是不一样的。
MySQL大多数事务型的存储引擎都不只是简单的行级锁,基于性能的考虑,他们一般在行级锁基础上实现了多版本并发控制(MVCC)。这一方案也被Oracle等主流的关系数据库采用。它是通过保存数据中某个时间点的快照来实现的,这样就保证了每个事务看到的数据都是一致的。
4、事务:
简单的说事务就是一组原子性的SQL语句。可以将这组语句理解成一个工作单元,要么全部执行要么都不执行。默认MySQL中自动提交时开启的(start transaction)
操作事务:

事务具有ACID的特性
原子性:
事务中的所有操作要么全部提交成功,要么全部失败回滚
比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱.不可能划了卡,而钱却没出来.这两步必须同时完成.要么就不完成.。
一致性:
数据库总是从给一个一致性的状态转换到另一个一致性的状态
例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变.不管数据怎么改变。一定是符合约束
隔离性:
一个事务所做的修改在提交之前对其它事务是不可见的
两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致.
持久性:
一旦事务提交,其所做的修改便会永久保存在数据库中。
事务的隔离级别:
READ UNCOMMITTED(读未提交):
事务中的修改即使未提交也是对其它事务可见
READ COMMITTED(读提交):
事务提交后所做的修改才会被另一个事务看见,可能产生一个事务中两次查询的结果不同。
REPEATABLE READ(可重读):
只有当前事务提交才能看见另一个事务的修改结果。解决了一个事务中两次查询的结果不同的问题。
SERIALIZABLE(串行化):
只有一个事务提交之后才会执行另一个事务。
5、死锁:
两个或多个事务在同一资源上相互占用并请求锁定对方占用的资源,从而导致恶性循环的现象。
对于死锁的处理:MySQL的部分存储引擎能够检测到死锁的循环依赖并产生相应的错误。InnoDB引擎解决的死锁的方案是将持有最少写锁的事务进行回滚。
为了提供回滚或者撤销未提交的变化的能力,许多数据源采用日志机制。例如:sql server使用一个预写事务日志,在将数据应用于(或提交到)实际数据页面前,先写在事务日志上。但是,其他一些数据源不是关系型数据库管理系统,他们管理未提交事务的方式完全不同。只要事务回滚时,数据源可以撤销所有未提交的改变,那么这种技术可用于事务管理。
6、SQL用法
1. replace into
2. UNION ALL
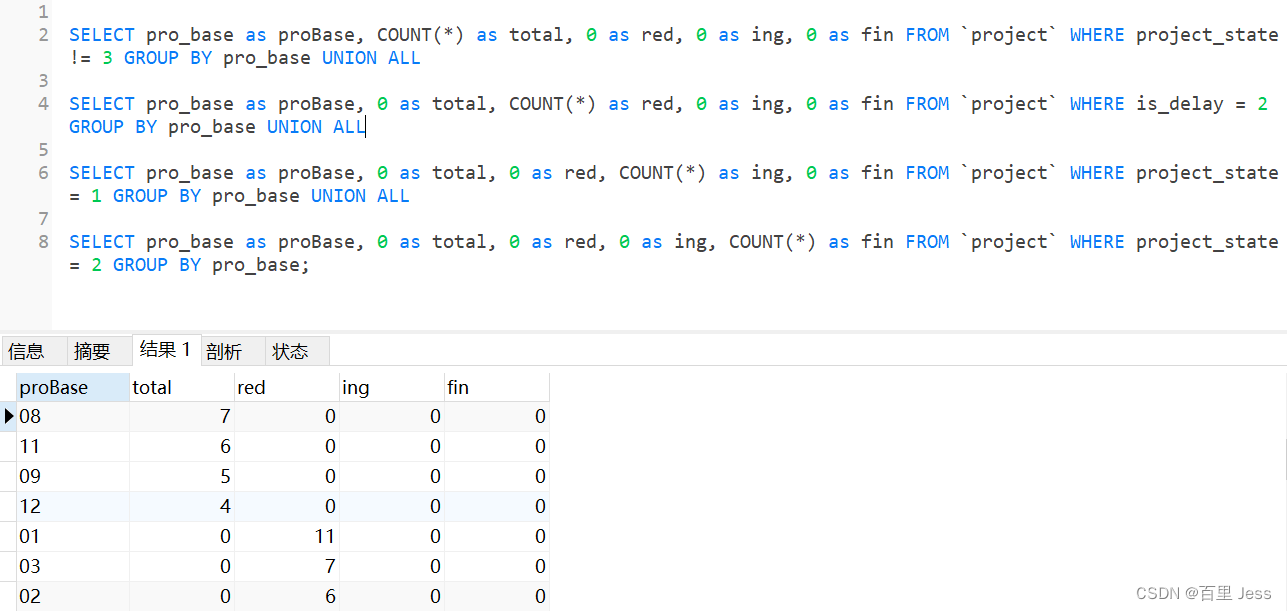
union 或者 union all 关键字可以将多个 select 语句的结果作为一个整体显示出来。
union 会自动压缩多个结果集合中的重复结果,而 union all 则将所有的结果全部显示出来,不管是不是重复。
union all:对两个结果集进行并集操作,包括重复行,不进行排序; 如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
SELECT pro_base as proBase, COUNT(*) as total, 0 as red, 0 as ing, 0 as fin FROM `project`
WHERE project_state != 3 GROUP BY pro_base UNION ALL
SELECT pro_base as proBase, 0 as total, COUNT(*) as red, 0 as ing, 0 as fin FROM `project`
WHERE is_delay = 2 GROUP BY pro_base UNION ALL
SELECT pro_base as proBase, 0 as total, 0 as red, COUNT(*) as ing, 0 as fin FROM `project`
WHERE project_state = 1 GROUP BY pro_base UNION ALL
SELECT pro_base as proBase, 0 as total, 0 as red, 0 as ing, COUNT(*) as fin FROM `project`
WHERE project_state = 2 GROUP BY pro_base;
3.把一个表的数据插入到另一个表中
INSERT INTO 目标表 (字段1, 字段2, ...) SELECT 字段1, 字段2,... FROM 来源表;(字段必须保持一致)
例如:insert into insertTest2(id,name) select id,name from insertTest1;
4.ON DUPLICATE key update
有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有则更新,没有则插入。这个时候就可以用到ON DUPLICATE key update这个sql语句了。
<insert id="saveBatchUUID" parameterType="java.util.List">
INSERT INTO zeeho_mmi_uuid (uuid) VALUES
<foreach collection="list" separator="," item="item">
(#{item})
</foreach>
ON DUPLICATE KEY UPDATE
update_tm = VALUES(update_tm)
</insert>


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











