







要确保Kafka在使用过程中的稳定性,需要从kafka在业务中的使用周期进行依次保障。主要可以分为:事先预防(通过规范的使用、开发,预防问题产生)、运行时监控(保障集群稳定,出问题能及时发现)、故障时解决(有完整的应急预案)这三阶段。
另外的篇幅请参考
1. 事先预防原则
事先预防即通过规范的使用、开发,预防问题产生。主要包含集群/生产端/消费端的一些最佳实践、上线前测试以及一些针对紧急情况(如消息积压等)的临时开关功能。
Kafka调优原则:
-
确定优化目标,并且定量给出目标(Kafka 常见的优化目标是吞吐量、延时、持久性和可用性);
-
确定了目标之后,需要明确优化的维度:
-
通用性优化:操作系统、JVM 等;
-
针对性优化:优化 Kafka 的 TPS、处理速度、延时等。
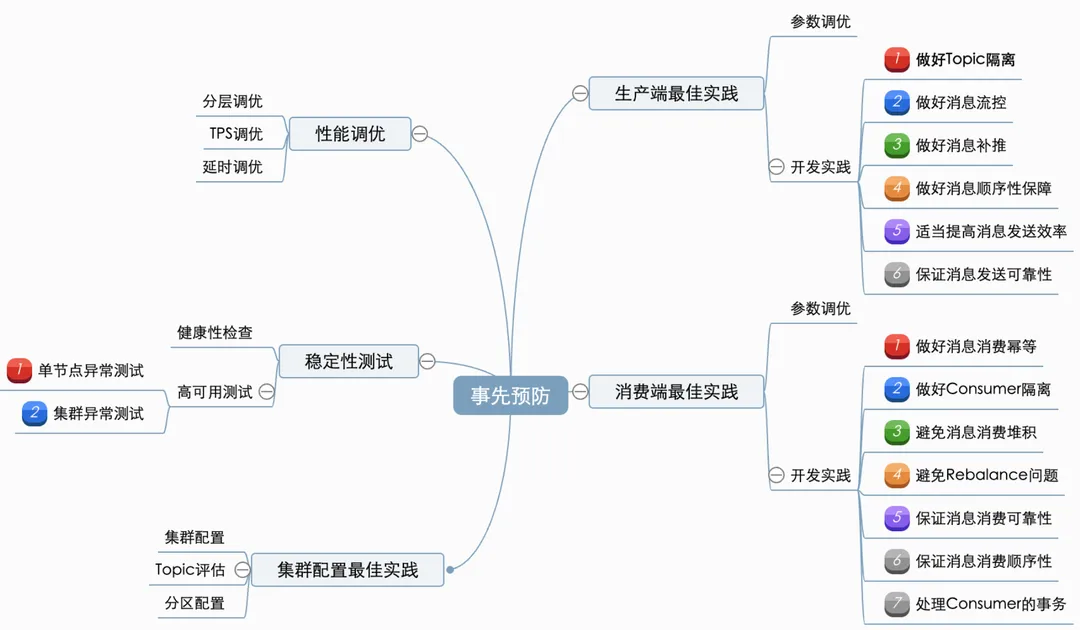
2. 生产端最佳实践
2.1 参数调优
-
使用 Java 版的 Client;
-
使用 kafka-producer-perf-test.sh 测试你的环境;
-
设置内存、CPU、batch 压缩;
-
batch.size:该值设置越大,吞吐越大,但延迟也会越大;
-
linger.ms:表示 batch 的超时时间,该值越大,吞吐越大、但延迟也会越大;
-
max.in.flight.requests.per.connection:默认为5,表示 client 在 blocking 之前向单个连接(broker)发送的未确认请求的最大数,超过1时,将会影响数据的顺序性;
-
compression.type:压缩设置,会提高吞吐量;
-
acks:数据 durability 的设置;
-
避免大消息(占用过多内存、降低broker处理速度);
-
broker调整:增加 num.replica.fetchers,提升 Follower 同步 TPS,避免 Broker Full GC 等;
-
当吞吐量小于网络带宽时:增加线程、提高 batch.size、增加更多 producer 实例、增加 partition 数;
-
设置 acks=-1 时,如果延迟增大:可以增大 num.replica.fetchers(follower 同步数据的线程数)来调解;
-
跨数据中心的传输:增加 socket 缓冲区设置以及 OS tcp 缓冲区设置。
2.2 开发实践
(1) 做好Topic隔离
根据具体场景(是否允许一定延迟、实时消息、定时周期任务等)区分kafka topic,避免挤占或阻塞实时业务消息的处理。
(2) 做好消息流控
如果下游消息消费存在瓶颈或者集群负载过高等,需要在生产端(或消息网关)实施流量生产速率的控制或者延时/暂定消息发送等策略,避免短时间内发送大量消息。
(3) 做好消息补推
手动去查询丢失的那部分数据,然后将消息重新发送到mq里面,把丢失的数据重新补回来。
(4) 做好消息顺序性保障
如果需要在保证Kafka在分区内严格有序的话(即需要保证两个消息是有严格的先后顺序),需要设置key,让某类消息根据指定规则路由到同一个topic的同一个分区中(能解决大部分消费顺序的问题)。
但是,需要避免分区内消息倾斜的问题(例如,按照店铺Id进行路由,容易导致消息不均衡的问题)。
-
生产端:消息发送指定key,确保相同key的消息发送到同一个p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









