







 本文介绍了Cache的不同映射方式及其访问原理,详细解释了全相联映射与直接相联映射的特点,并讨论了Cache的读写操作策略,如写回法、写直达法和写一次法等。此外,还探讨了Cache一致性问题,特别是在DMA操作中可能出现的不一致性问题。
本文介绍了Cache的不同映射方式及其访问原理,详细解释了全相联映射与直接相联映射的特点,并讨论了Cache的读写操作策略,如写回法、写直达法和写一次法等。此外,还探讨了Cache一致性问题,特别是在DMA操作中可能出现的不一致性问题。
访问原理
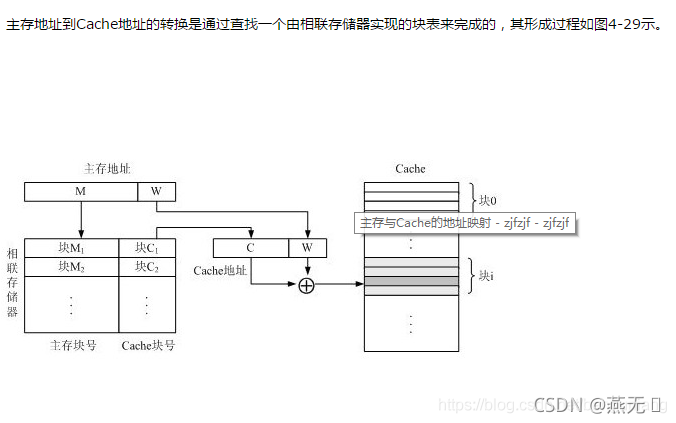
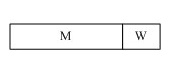
全相联映射方式的优点是Cache的空间利用率高,但缺点是相联存储器庞大,比较电路复杂,因此只适合于小容量的Cache之用
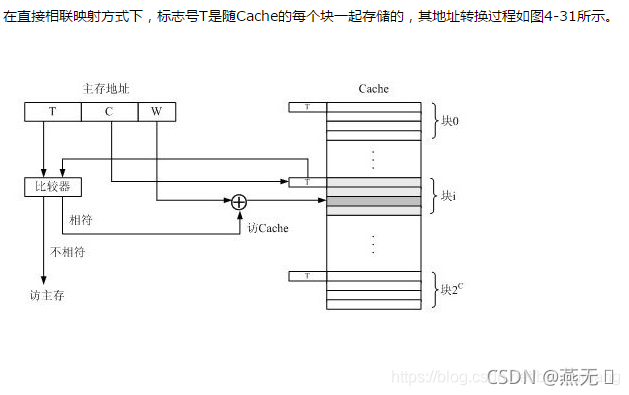
访问过程: 当一个主存块调入 Cache中时,会同时将主存地址的T标志存入Cache块的标志字段中。当CPU送来一个访存地址时,首先,根据该主存地址的C字段找到Cache的相 应块,然后将该块标志字段中存放的标志与主存地址的T标志进行比较,若相符,说明主存的块目前已调入该Cache块中,则命中,于是使用主存地址的W字段 访问该Cache块的相应字单元;若不相符,则未命中,于是使用主存地址直接访主存。
评价: 直接相联映射方式的优点 是比较电路最简单,但缺点是Cache块冲突率较高,从而降低了Cache的利用率。由于主存的每一块只能映射到Cache的一个特定块上,当主存的某块 需调入Cache时,如果对应的Cache特定块已被占用,而Cache中的其它块即使空闲,主存的块也只能通过替换的方式调入特定块的位置,不能放置到 其它块的位置上。
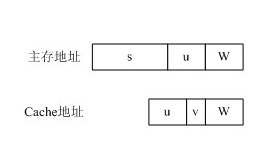
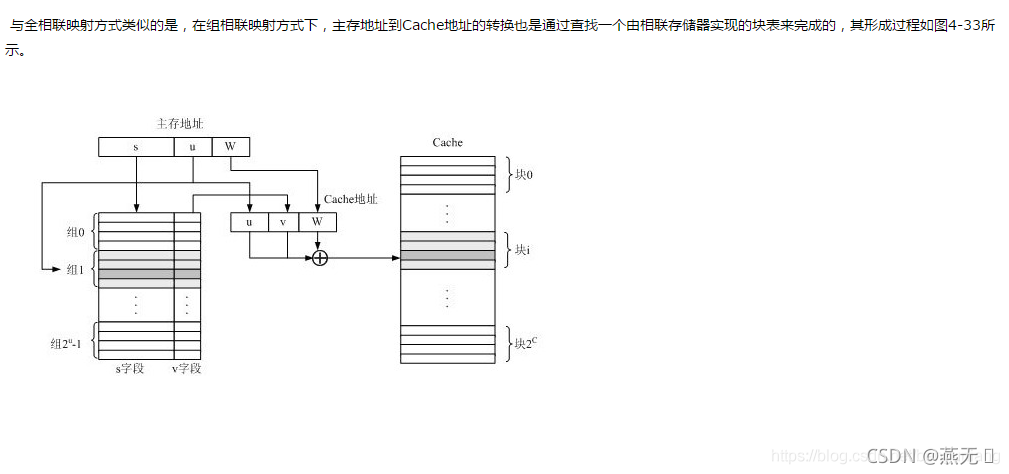
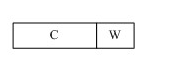
当一个主存块调入Cache中时,会同时将其主存块地址的前s位写入一个由相联存储器实现的快表的对应Cache块项的s字段中。例如,设主存的某块调入Cache的第1组的第2块中,则在快表的组1第3项的s字段会登记下该主存块地址的前s位。
CPU访存时,首先,根据主存地址中的主存块号中的u字段找到快表的相应组,然后将该组的所有项的前s位同时与主
存地址的s字段作比较,若相符,则说明主存块在Cache中,于是将Cache中该项的v字段取出,作为Cache地址的v字段,而Cache地址的u、
W字段直接由主存地址的u、W字段形成,最后形成一个完整的访Cache地址。当然,若比较结果是没有相符项,则未命中,由主存地址直接访主存。
其实,全相联映射和直接相联映射可以看成是组相联映射的两个极端情况。若u=0,v=C,则Cache只包含1组,此即全相联映射方式;若u=C,v=0,则组内的块数等于1,此即直接相联映射。
cache的读写操作
因为cache的内容是部分主存内容的副本,应该与主存内容保持一致。而CPU对cache的写入更改了cache内容,如何与主存内容保持一致就有几种写操作工作方式可供选择,统称为写策略。
1.写回法(write–back)
当CPU对cache写命中时,只修改cache的内容不立即写入主存,只当此行被换出时才写回主存。这种策略使cache在CPU-主存之间,不仅在读方向而且在写方向上都起到高速缓存作用。对一cache行的多次写命中都在cache中快速完成修改, 只是需被替换时才写回速度较慢的主存,减少了访问主存的次数从而提高了效率。为支持这种策略,每个cache行必须配置一个修改位,以反映此行是否被CPU修改过。当某行被换出时,根据此行修改位为1还是为0,决定是将该行内容写回主存还是简单地弃之 而不顾。
对于cache写未命中,写回法的处理是为包含欲写字的主存块在cache分配一行,将此块整个拷贝到Cache后对其进行修改, 因为尔后对此块的多次读/写访问的可能性很大。拷贝主存块时虽已读访问到主存,但此时并不对主存块修改。因为换出的cache很可能此期间要写回主存,为避免此过程耗时太长,写未命中对将新块读入后,只在cache中进行写修改。统一地将主存写修改操作留待换出时进行。
这种写cache与写主存分开进行方式可显著减少写主存次数,但写回法也带来了cache / 主存严重的不一致性。后面将要介绍的MESI协议,就是一个针对写回法的维护cache一致性的协议。
2.写直达法(write–through)
又称全写法,写透。是当cache写命中时,cache与主存同时发生写修改。这种策略 显然较好地维护了cache与主存的内容一致性,但这并不等于说全部解决了一致性问题。例如在多处理器系统中各CPU都有自己的cache,一个主存块若在多个cache中都有一份拷贝的话,某个CPU以写直达法来修改它的cache和主存时,其它cache中的原拷贝就过时了。即使在单处理器系统中,也有I/O设备不经过cache向主存写入的情况。总之,仍要关注一致性问题。
当cache写未命中时,只有直接向主存写入了,但此时是否将修改过的主存块取到cache,写直达法却有两种选择。一种是取来并且为它分配一个行位置,称为WTWA法(Write–Through–with–Write–Allocate)。另一种是不取称为WTNWA法(WriteThrough–with.NO-Write–Allocate)。前 一种方法保持了cache / 主存的一致性,但操作复杂,而后一种方法操作简化,但命中率降低,内存的修改块只有在读未命中对cache 进行替换时,才有可能映射到cache 。
写直达法是写cache与写主存同步进行,其优点是cache每行无需设置一个修改位以及相应的判测逻辑。写直达法的缺点是,cache对CPU向主存的写操作无高速缓冲功能,降低了cache的功效。
3.写一次法(write–once)
写一次法是一种基于写回法又结合了写直达法的写策略,即写命中和写未命中的处理与写回法基本相 同,只是第一次写命中时要同时写入主存。这种策略主要用于某些处理器的片内cache,例如Pentium处理器的片内数据cache就采用的是写一次 法。因为片内cache写命中时,写操作就在CPU内部高速完成,若没有 内存地址及其它指示信号送出,就不便于系统中的其它cache监听(snoop)。采用写一次法,在第一次片内cache写命中时, CPU要在总线上启动一个存储写周期。其它cache监听到此主存块地址及写信号后,即可把它们各自保存可能有的该块拷贝及时作废(无效处理)。尔后若有 对片内cache此行的再次或多次写命中,则按回写法处理,无需再送出信号了。这样虽然第一次写命中时花费了一个存 储周期,但对维护系统全部cache的一致性有利。而大多的cache写操作不涉及到片 外,对指令流水执行有利
cache 一致性问题
CPU在访问内存时,首先判断所要访问的内容是否在Cache中,如果在,就称为“命中(hit)”,此时CPU直接从Cache中调用该内容;否则,就 称为“ 不命中”,CPU只好去内存中调用所需的子程序或指令了。CPU不但可以直接从Cache中读出内容,也可以直接往其中写入内容。由于Cache的存取速 率相当快,使得CPU的利用率大大提高,进而使整个系统的性能得以提升。
Cache的一致性就是直Cache中的数据,与对应的内存中的数据是一致的。
DMA是直接操作总线地址的,这里先当作物理地址来看待吧(系统总线地址和物理地址只是观察内存的角度不同)。如果cache缓存的内存区域不包括DMA分配到的区域,那么就没有一致性的问题。但是如果cache缓存包括了DMA目的地址的话,会出现什么什么问题呢?
问题出在,经过DMA操作,cache缓存对应的内存数据已经被修改了,而CPU本身不知道(DMA传输是不通过CPU的),它仍然认为cache中的数 据就是内存中的数据,以后访问Cache映射的内存时,它仍然使用旧的Cache数据。这样就发生Cache与内存的数据“不一致性”错误。
dma_alloc_coherent 在 arm 平台上会禁止页表项中的 C (Cacheable) 域以及 B (Bufferable)域。
而 dma_alloc_writecombine 只禁止 C (Cacheable) 域.
C 代表是否使用高速缓冲存储器, 而 B 代表是否使用写缓冲区。
这样,dma_alloc_writecombine 分配出来的内存不使用缓存,但是会使用写缓冲区。而 dma_alloc_coherent 则二者都不使用。
C B 位的具体含义
0 0 无cache,无写缓冲;任何对memory的读写都反映到总线上。对 memory 的操作过程中CPU需要等待。
0 1 无cache,有写缓冲;读操作直接反映到总线上;写操作,CPU将数据写入到写缓冲后继续运行,由写缓冲进行写回操作。
1 0 有cache,写通模式;读操作首先考虑cache hit;写操作时直接将数据写入写缓冲,如果同时出现cache hit,那么也更新cache。
1 1 有cache,写回模式;读操作首先考虑cache hit;写操作也首先考虑cache hit
效率最高的写回,其次写通,再次写缓冲,最次非CACHE一致性操作。
其实,写缓冲也是一种非常简单得CACHE,为何这么说呢。
我们知道,DDR是以突发读写的,一次读写总线上实际会传输一个burst的长度,这个长度一般等于一个cache line的长度。
cache line是32bytes。即使读1个字节数据,也会传输32字节,放弃31字节。
写缓冲是以CACHE LINE进行的,所以写效率会高很多


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









