




 本文详细介绍了C++程序的编译流程,包括预处理、编译、汇编和链接四个阶段,以及如何使用MakeFile实现自动化编译。同时,深入解析了ELF目标文件的分类与内容,解释了代码段与数据段分离的原因。
本文详细介绍了C++程序的编译流程,包括预处理、编译、汇编和链接四个阶段,以及如何使用MakeFile实现自动化编译。同时,深入解析了ELF目标文件的分类与内容,解释了代码段与数据段分离的原因。
一、编译与链接
编译与链接主要分为四个步骤:预处理、编译、汇编和链接。
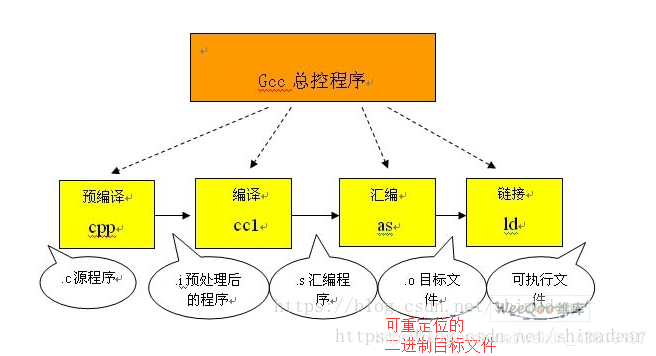
1 预处理
将源代码文件和相关的头文件,如 iostream 等被预处理器 cpp 预处理成 .i 文件。第一步预处理的过程相当于如下命令:
g++ -E hello.cpp -o hello.i
预处理过程主要处理那些源代码文件只能够的以“#”开始的预编译指令。比如#include 、#define等,主要处理规则有:
(1)将所有的#define删除,并且展开所有的宏定义,如:
#define a b
对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的a则不被替换。
#undef:如果标识符当前没有被定义成一个宏名称,那么就会忽略该指令。一旦定义预处理器标识符,它将保持已定义状态且在作用域内,直到程序结束或者使用#undef 指令取消定义。
(2)处理所有条件预编译指令,比如#if、#ifdef、#ifndef、#elif、#else、#endif。
#ifdef 宏
逻辑1
#else
逻辑2
#endif
#ifdef 只关心宏是否被定义,不关心宏逻辑的真假
#if 宏
逻辑1
#else
逻辑2
#endif
#if 不仅关心宏是否被定义,而且关心宏逻辑的真假
(3)处理#include 预编译指令,将被包含的文件插入到该预编译指令的位置。
(4)过滤所有的注释“ // ”和“/* */ ”中的内容。
(5)添加行号和文件名标识,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时能够显示行号。
(6)保留所有的#pragma 编译器指令,因为编译器需要使用它们。
2 编译
将hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。编译会从词法、语法和语义上对文件进行分析, 并进行汇编代码生成, 形成的还是文本文件------汇编语言文件。以.s作为文件扩展名,然后-o保存在hello.s里。
g++ -S hello.i -o hello.s
3 汇编
汇编器将hello.s翻译成二进制机器语言指令,所以我们就看不懂了,把这些指令打包成一种叫做可重定位目标程序格式,并保存在.o文件中。
g++ hello.s -c -o hello.o
4 链接
表示让gcc只进行“预处理编译汇编链接”。最后将二进制机器语言指令转换成二进制的可执行程序。
g++ hello.o -o a.out
二、MakeFile
makefile 带来的好处就是“自动化编译”,一旦写好,只需要一个make 命令,整个工程完全自动编译,极大地提高了软件开发的效率。makefile 就像一个shell 脚本一样,其中也可以执行操作系统的命令。下面将用一个示例来说明makefile 的书写规则。
准备3 个文件:
file1.h file1 .cpp file2.cpp
file1.h:
#ifndef FILE1_H_
#define FILE1_H_ //防止重定义
#ifdef __cplusplus
extern "C" {
#endif
void File1Print();
#ifdef __cplusplus
}
#endif
#endif
file1.cpp:
#include <iostream>
#include "file1.h"
using namespace std;
void File1Print(){
cout << "Print file1 ******************"<< endl;
}
file2.cpp:
#include <iostream>
#include "file1.h"
using namespace std;
int main(){
cout<<"Print file2**********************"<< endl;
File1Print();
return 0;
}
makefile直接编译文件:
helloworld:file1.o file2.o
g++ file1.o file2.o -o helloworld
file2.o: file2.cpp
g++ -c file2.cpp -o file2.o
file1.o: file1.cpp file1.h
g++ -c file1.cpp -o file1.o
clean:
rm -rf *.o helloworld
一个makefile 主要含有一系列的规则:
A:B
(tab)
(tab)
…
makefile中变量的使用:
OBJS = file1.o file2.o
XX = g++
CFLAGS = -Wall -O -g
helloworld : $(OBJS)
$(XX) $(OBJS) -o helloworld
file2.o: file2.cpp
$(XX) $(CFLAGS) -c file2.cpp -o file2.o
file1.o: file1.cpp file1.h
$(XX) $(CFLAGS) -c file1.cpp -o file1.o
clean:
rm -rf *.o helloworld
三、目标文件
前面已经多次提到目标文件,究竟目标文件是什么? ELF 是一种用于二进制文件、可执行文件、目标代码、共享库和核心转储的标准文件格式。ELF 标准的目的是为软件开发人员提供一组二进制接口定义,这些接口可以延伸到多种操作环境中,从而减少重新编码、编译程序的需要。
UNIX 最早的可执行文件格式为a. out 格式,它的设计非常地简单,以至于后来当共享库这个概念出现的时候, a. out 格式就变得捉襟见肘了。于是人们设计了 COFF 格式标准来解决这些问题,这个设计非常通用。而 ELF 正是从 COFF 继承来的。
COFF 的主要贡献是在目标文件里面引人了“段”的机制,不同的目标文件可以拥有不同数量及不同类型的“段” 。另外,它还定义了调试数据格式。 ELF 格式比 COFF 更具可扩展性与灵活性,被用来取代COFF 。现在, ELF 的使用已经非常广泛了。
ELF的分类:
- 可重定位的目标文件
汇编生成的.o文件。连接器将器做为目标文件的输入,链接处理后生成一个可执行的目标文件或者一个可被共享的对象文件(.so文件)。 - 可被执行的目标文件(.exe)
除了.exe,还有一种是可执行的脚本(如shell脚本)文件。 - 可被共享的目标文件 就是动态库文件,.so文件。如果拿前面的静态库来生成可执行程序中都会有一份库代码的拷贝。如果磁盘中存储这些可执行程序,就会占用额外的磁盘空间。
ELF内容:
ELF文件主要由文件头(ELF header)、代码段(.text)、数据段(.data)、.bss段、只读数据段(.rodata)、段表(section table)、符号表(.symtab)、字符串表(.strtab)、重定位表组成

代码段与数据段分开的原因:
1.权限分别管理。对进程来说,数据段是可读写的,指令段是只读的。这样可以防止程序指令被改写。
2.指令区与数据区的分离有助于提高程序的局部性,有助于对CPU缓存命中率的提高。
3.当系统运行多个改程序的副本的时候,他们对应的指令都是一样的,此时内存只需要保留一份改程序的指令即可。当然,每个副本进程的数据区域是不一样的,他们是进程私有的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









