







Redis中的hash存储
- Redis中的一大数据类型hash存储原理。
- 以执行
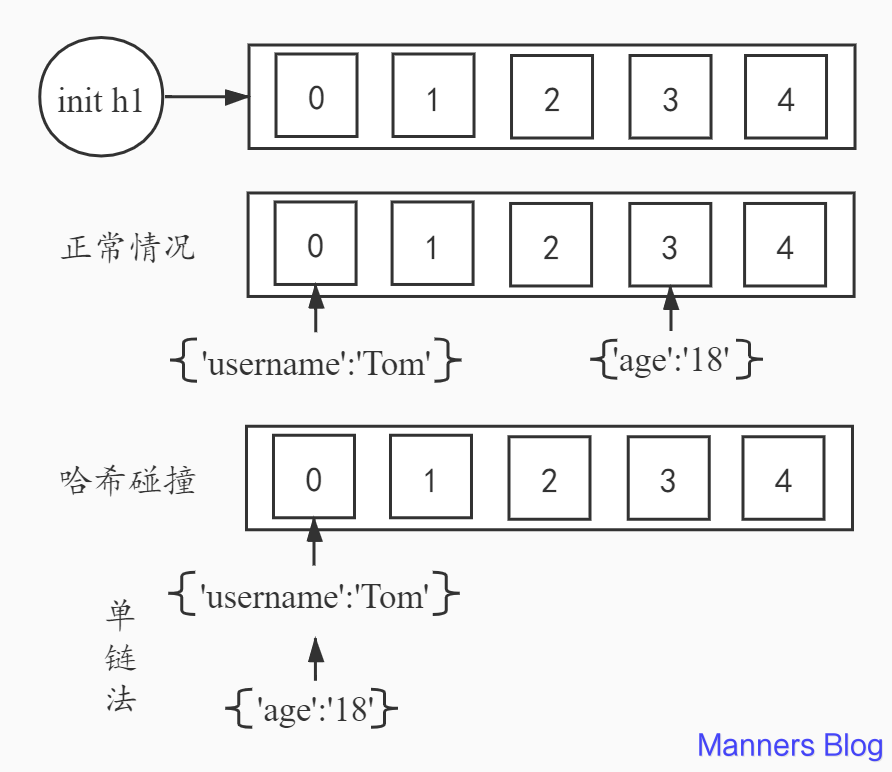
hset h1 username Tom为例,首先初始化h1为5个位置长度。 - 对
filed哈希计算- hash(‘username’) % 5 = 0 得到位置索引为0。
- 将
username为Tom的数据存放在h1的位置0处。
- 继续执行
hset h1 age 18- 进行hash计算
hash('age')得到相应的存储位置并存储。 - 如果位置索引仍为0,两字段的哈希值对应的存储空间索引位置发生冲突。 ----- 哈希碰撞
- 解决方案:单链法,在0位置下方开辟存储空间进行存储。
- 进行hash计算
- 扩容:当一维存储位置不够时,需要进行扩容。
- Redi触发扩容条件:当总字段个数等于一维数组的长度时,开始扩容。
- Redis采用渐进式扩容,并且保留新旧两份数据。
python中的hash存储
-
python中的字典和集合的hash存储原理。
-
执行以下程序为例,初始化dict为5个位置长度。
dict = {} dict['a'] = 1 -
对
key值哈希计算:hash(‘a’) % 5 = 0得到位置索引为0,将a对应的value存到位置0处。 -
继续执行
dict['b'] = 2- 如果发生哈希碰撞,采取二次计算。以座位号为参数,进行伪随机探测,直到找到自己的位置。
- 为了保障可以科学的进行查找b,python在执行删除操作时,会在位置上进行标记,从而维护了完整的探测链,对于哈希碰撞的key值可以原链路查找。
-
扩容:当空闲位置的数量少于总容量的1/3时,进行扩容。

















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









