







 本文深入探讨了数据库索引的本质,解析了不同索引结构如HASH表、二叉树、B树及B+树的特点与应用场景,重点讲解了MySQL中InnoDB引擎的B+树索引如何提高查询效率,以及在创建索引时应考虑的因素。
本文深入探讨了数据库索引的本质,解析了不同索引结构如HASH表、二叉树、B树及B+树的特点与应用场景,重点讲解了MySQL中InnoDB引擎的B+树索引如何提高查询效率,以及在创建索引时应考虑的因素。
索引的本质
索引是一种数据结构。
分享一个可以观察各种树形结构变化的网站
https://www.cs.usfca.edu/~galles/visualization/BTree.html
HASH表索引
目前mysql数据库支持hash和BTREE两种索引方式
HASH表索引图:
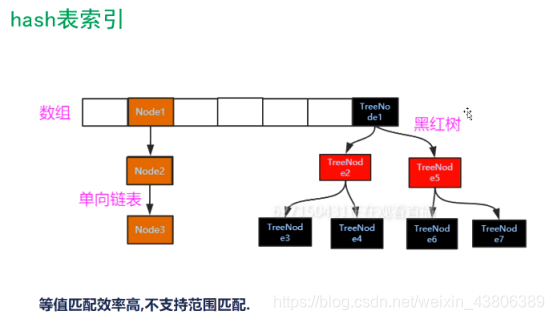
对于等值查找HASH索引有天然的优势,只需要HASHCODE方法便可以查找,但是对于范围查询不好匹配。假如有2条数据,第一条hashcode=1,另一条hashcode=1000000,此时使用范围查找,会有很多空值hashcode。
所以MYSQL放弃了HASH表索引结构。
二叉树
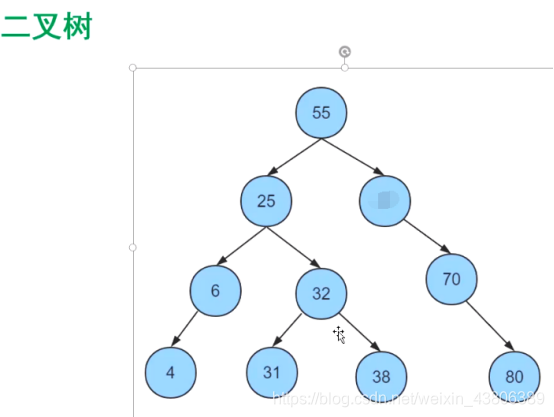
二叉树有很明显的缺陷,当数据主见是int递增的情况下,二叉树会变成一条链表,所以不选择二叉树。
平衡二叉树
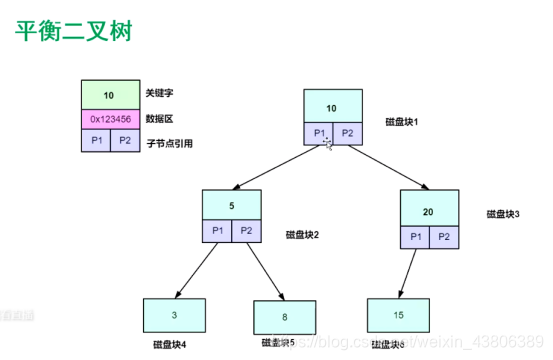
平衡二叉树解决了主键递增情况树变成链表的结果,但是依然有很多问题。
当数据量太多的时候,数高不可控,需要的io操作太多。
从操作系统磁盘交互特性的角度考虑,4K是一页,但是每个磁盘节点的数据不够4K,所以导致磁盘的利用率太低。
B树
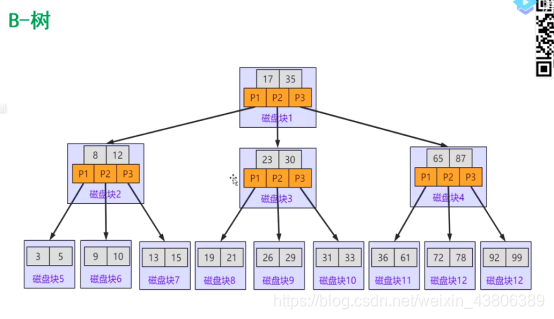
B树又称为多路平衡查找树,有效的解决了磁盘利用率低的问题。因为每个 节点有n个关键词,n+1个数据区,以16K计算的话,在理想状况下关键字为512个,刚好完美利用磁盘。(具体计算为关键词为4个bit,数据区为2k,这里也说不太清,有兴趣可以自行了解一下)
B树也存在一定的问题,就是io操作多,因为当要查找的数据在叶子节点的话每次的磁盘查找会带有数据区的数据,然而这些数据是不需要使用的,MYSQL在B树的基础上做了调整,从而选择了B+树
B+树
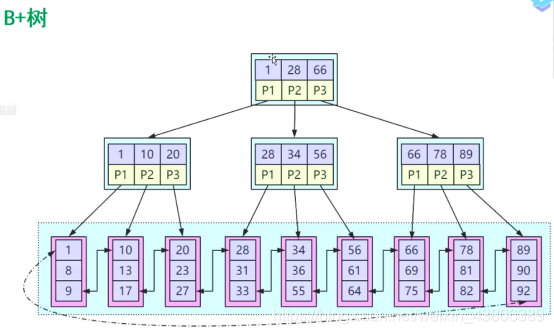
B+树在B树的前提下,只有叶子节点存在数据,根节点和枝节点只有数据的指向,叶子节点采用了左闭合的方式,形成了一个天然的排序,这也就是说为什么order by id DESC效率很高。同样,在排序的时候尽量选用索引列排序防止二次排序。
order by id DESC和order by create_time DESC结果一样,但是前者效率高。
也因为这种左闭合的叶子节点模式,无论是等值查找还是范围查找都非常的效率。
Innodb引擎
在mysql5.5以后,引擎变为Innodb
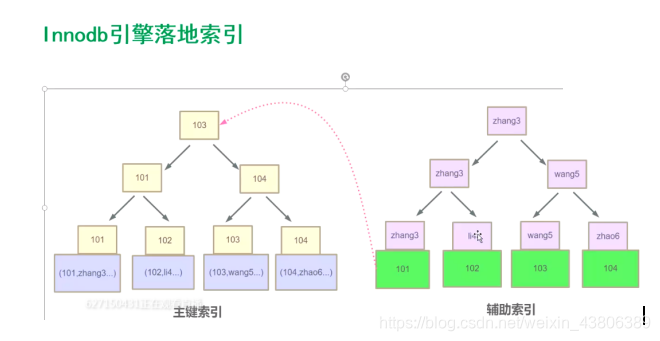
这种索引结构如果只需要查询辅助索引的内容,则不需要回表,效率很高。
创建索引字段的选择
一般选择离散度好的字段。离散度好可以理解为字段重复读少的字段。例如性别字段(1:男2:女),字段只有1和2,重复读高,当离散率在15%(记不清了)以下时候,mysql查询会强制不采用此索引。
创建索引
select * from user where name = ?;
select * from user where name = ? and phone = ?;
假如以上2句sql,在公司数据库频繁使用,则只需要创建联合索引即可,不需要针对name字段创建辅助索引。因为会变成冗余索引,导致cup的飙升,由于索引的最左前缀原则,此时创建联合索引即可,会包括辅助索引。联合索引需要注意字段的前后顺序,因为会遵循最左前缀原则。
create index idx_name_phone on user(name,phone);

















 6026
6026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









