






导读:学习架构类数据标准中数据目录、数据模型、数据交换、数据服务之间的关系,对于构建高效、安全、可持续的数据体系具有重要意义。这有助于提高数据管理的效率、促进数据共享和协作、保障数据的质量和准确性、支持业务决策和创新以及提升企业的竞争力。本质是将数据从无序资源转化为有序资产,再通过服务化释放业务价值。
一、架构类数据标准-核心组件的功能定位
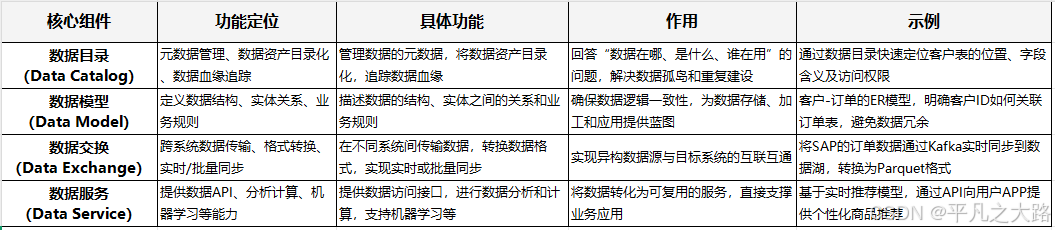
二、核心组件协同关系的价值与必要性
1. 实现数据资产的全生命周期管理
- 流程闭环:
- 发现(数据目录)→ 定义(数据模型)→ 流动(数据交换)→ 应用(数据服务)。
- 价值:从元数据管理到服务化输出,覆盖数据从产生到消费的全流程,避免“数据沉睡”。
- 案例:零售企业通过数据目录发现客户行为数据,建模后通过数据交换清洗存储,最终通过数据服务生成实时用户画像,驱动精准营销。
2. 提升数据一致性与可信度
- 数据模型与目录的协同:数据目录记录表的元数据(如字段类型、业务含义),数据模型定义其逻辑关系,两者结合确保数据定义的一致性和可解释性。
- 必要性:避免因字段同名不同义(如“销售额”在财务与业务部门的定义差异)导致的决策错误。
3. 加速数据流动与业务敏捷性
- 数据交换的核心作用:通过标准化传输协议(如REST API、Kafka)和格式转换(JSON→Parquet),消除系统间数据壁垒。
- 价值:支持快速响应业务需求,例如实时同步供应链数据到数据湖,供数据服务生成库存预警。
4. 推动数据服务化与价值释放
- 数据服务的核心能力:将数据封装为API、BI报表或机器学习模型,直接赋能业务场景(如风控、推荐)。
- 必要性:避免重复开发,例如多个业务部门共享同一客户分群模型API,而非各自重建。
5. 支持治理与合规要求
- 数据目录的治理功能:记录数据血缘(如“客户表数据来源为SAP系统”),追踪敏感数据(如GDPR合规字段)。
- 数据模型的安全约束:在模型设计阶段定义权限规则(如“订单表仅开放给财务部门”)。
- 价值:满足审计要求,减少数据滥用风险。
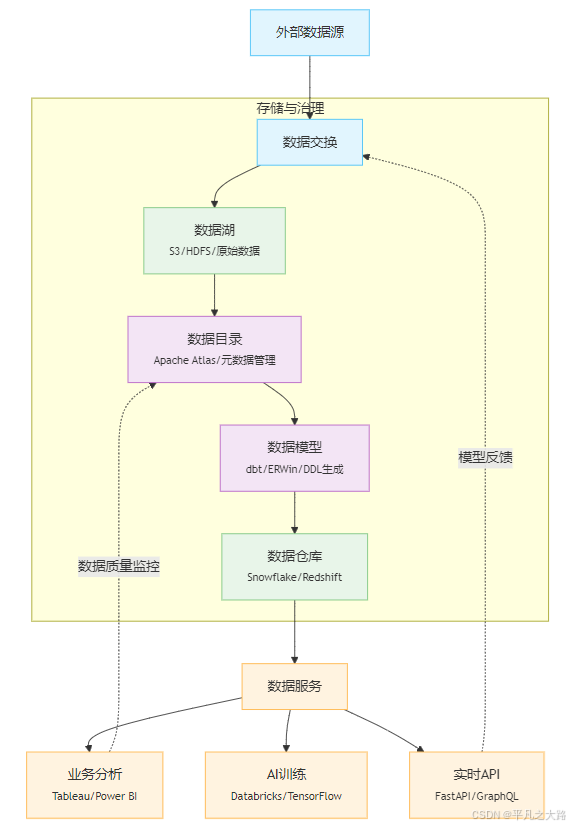
三、分层架构图(技术组件嵌入)
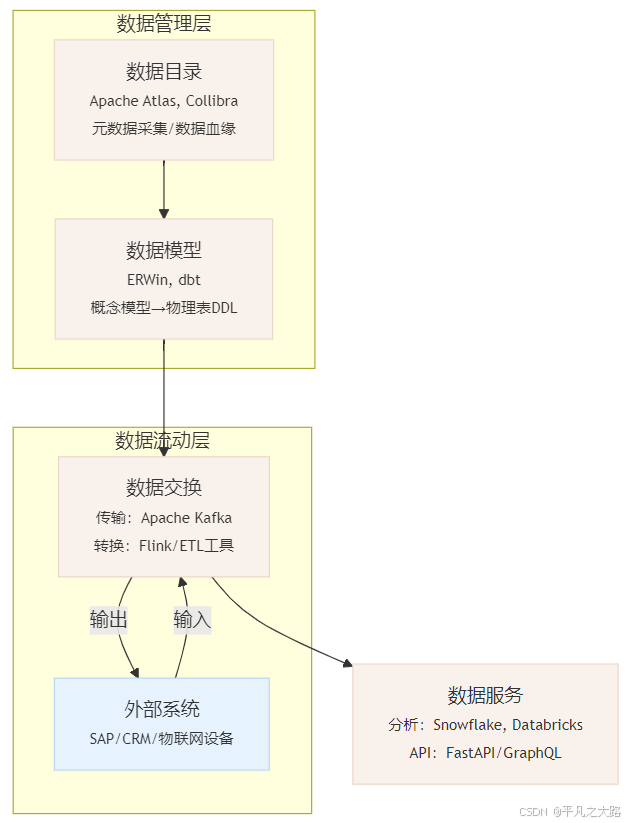
关键层级关系说明
1、自上而下的数据流
数据目录 → 数据模型 → 数据交换 → 数据服务
- 从元数据发现到服务化输出的完整链路,体现数据从定义到应用的闭环。
2、双向交互
- 数据交换 ↔ 外部系统/应用:支持跨系统数据输入与输出(如API、文件传输)。
- 数据服务:作为终端层,直接向业务提供价值(如报表、机器学习模型)。
3、核心依赖
- 数据模型依赖数据目录的元数据定义(如字段类型、业务含义)。
- 数据服务依赖数据交换的标准化输入(如清洗后的数据表、实时流)。
四、分层架构图(技术组件嵌入)
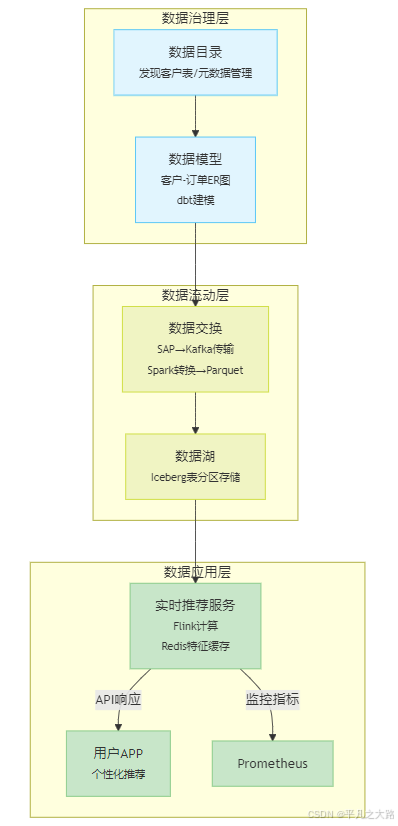
五、扩展型架构(含治理与存储)
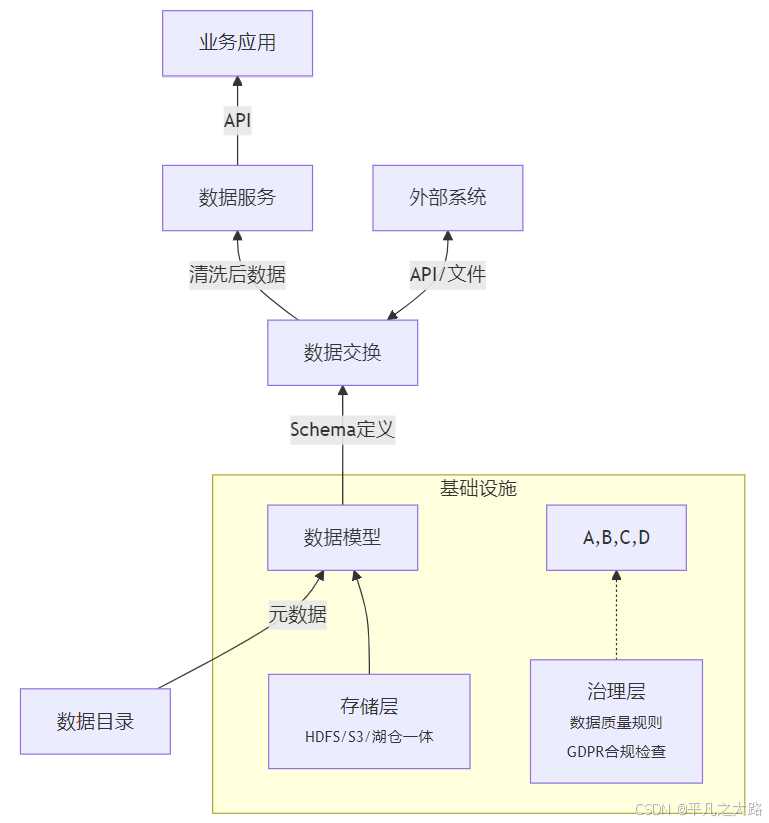
六、数据流强调版
七、典型场景的协同流程示例
7.1 金融行业:实时反欺诈系统
场景:银行需实时监控交易流水,识别欺诈行为并拦截高风险交易。
- 数据目录发现交易流水表、用户画像表的位置,明确字段含义(如交易金额、IP地址、设备指纹)。
- 数据模型构建欺诈检测模型:定义用户行为基线(如正常交易频率、地理位置模式)、黑名单规则(如高风险IP库)。
- 数据交换Kafka实时接收交易数据 → Flink流处理(特征提取) → 写入Redis(实时特征库)。
- 数据服务提供实时风控API:交易发生时调用模型计算风险评分,返回拦截或放行指令。
- 结果:欺诈交易识别准确率提升30%,平均响应时间<50ms,满足金融级实时性要求。
7.2 医疗行业:跨机构电子健康记录(EHR)共享
场景:医院与科研机构协作,安全共享患者数据以支持疾病研究。
- 数据目录登记患者EHR表、基因组数据表,标注隐私字段(如姓名、身份证号需脱敏)。
- 数据模型设计标准化数据模型:遵循FHIR标准,统一病历结构(如诊断编码、用药记录)。
- 数据交换通过API网关(OAuth2鉴权)传输脱敏数据 → 格式转换为Parquet → 存储到医疗数据湖。
- 数据服务提供研究分析平台:支持SQL查询、统计建模(如癌症发病率关联分析)。
- 结果:数据共享效率提升60%,符合HIPAA/GDPR隐私合规要求,加速新药研发进程。
7.3 制造业:设备预测性维护
场景:工厂通过物联网数据预测设备故障,减少停机损失。
- 数据目录发现传感器数据表(温度、振动频率)、维修记录表,记录数据更新频率(如1秒/条)。
- 数据模型构建设备健康度模型:定义故障特征(如振动频谱异常阈值)、维修工单关联规则。
- 数据交换MQTT协议采集设备数据 → Kafka流式传输 → Spark实时计算(异常检测) → 写入时序数据库。
- 数据服务提供预警看板(如Power BI)和工单API:触发维修工单自动派发至工程师APP。
- 结果:设备故障预测准确率达85%,停机时间减少40%,维修成本降低25%。
7.4 智慧城市:交通流量优化
场景:城市交管部门整合多源数据,动态调整红绿灯时长。
- 数据目录登记摄像头实时视频流、出租车GPS轨迹表、气象数据表,标注数据所有者(如交管局、出租车公司)。
- 数据模型构建交通流模型:定义拥堵指数(如车辆密度、平均速度)、红绿灯优化策略(如动态配时算法)。
- 数据交换视频流(RTSP协议)→ 边缘计算(车辆识别) → Kafka传输结构化数据(车辆计数、位置)。
- 数据服务提供交通控制API:实时下发红绿灯时长指令至路口设备;公众可通过APP获取拥堵预警。
- 结果:高峰时段通行效率提升20%,市民出行满意度提高35%。
7.5 电商行业:个性化推荐引擎
场景:电商平台基于用户行为数据提供实时商品推荐。
- 数据目录发现用户点击流表、订单表、商品画像表,记录数据敏感等级(如用户ID需加密)。
- 数据模型构建协同过滤模型:定义用户-商品交互矩阵、特征权重(如点击率、购买转化率)。
- 数据交换Flink实时处理点击事件 → 生成用户特征向量 → 写入Redis(低延迟读取)。
- 数据服务提供推荐API:根据用户特征返回Top-N商品列表,支持AB测试(如不同算法版本对比)。
- 结果:推荐点击率提升25%,GMV(成交总额)增长18%,用户停留时长增加15%。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









