






 本文详细介绍了如何使用Java API操作HDFS,包括上传文件至HDFS、从HDFS下载文件到本地,以及分块下载大型文件的具体实现。通过实例演示了输入输出流的使用,展示了HDFS文件系统的灵活性。
本文详细介绍了如何使用Java API操作HDFS,包括上传文件至HDFS、从HDFS下载文件到本地,以及分块下载大型文件的具体实现。通过实例演示了输入输出流的使用,展示了HDFS文件系统的灵活性。
一:把本地文件通过输入输出流上传到HDFS上(一般会在公司中使用,会有相应的架构)源头是输入流,去向是输出流
public class HDFSIO {
@Test
public void putFIleToHDFS() throws IOException, InterruptedException, URISyntaxException {
//获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop132:9000"), conf, "root");
//获取输入流
FileInputStream fis = new FileInputStream(new File("f:/TestData/banhua.txt"));
//获取输出流
FSDataOutputStream fos = fs.create(new Path("/banhua.txt"));
//流的对拷
org.apache.hadoop.io.IOUtils.copyBytes(fis, fos, conf);
//关闭资源 //先关闭输出流,在关闭输入流
org.apache.hadoop.io.IOUtils.closeStream(fos);
org.apache.hadoop.io.IOUtils.closeStream(fis);
fs.close();
}
//在HDFS上下载文件到本地
@Test
public void FIleFromHDFS() throws IOException, InterruptedException, URISyntaxException {
//获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop132:9000"), conf, "root");
//获取输入流
FSDataInputStream fis = fs.open(new Path("/yanjing.txt"));
//获取输出流
FileOutputStream fos = new FileOutputStream(new File("f:/TestData/yaning.txt"));
//流的对拷
org.apache.hadoop.io.IOUtils.copyBytes(fis, fos, conf);
//关闭资源 //先关闭输出流,在关闭输入流
org.apache.hadoop.io.IOUtils.closeStream(fos);
org.apache.hadoop.io.IOUtils.closeStream(fis);
fs.close();
}
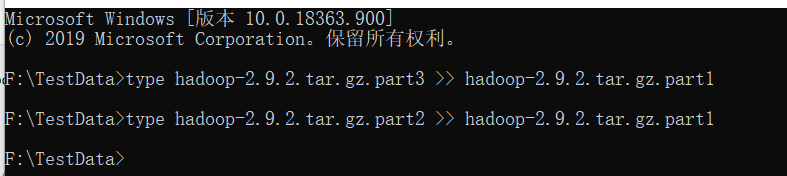
实现分块从HDFS上下载文件
//下载第一块(分块下载大的文件)
@Test
public void readFileSeek1() throws IOException, InterruptedException, URISyntaxException {
//获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop132:9000"), conf, "root");
//获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.9.2.tar.gz"));
//获取输出流
FileOutputStream fos = new FileOutputStream(new File("f:/TestData/hadoop-2.9.2.tar.gz.part1"));
//流的对拷(只拷贝128M)
byte[] buf = new byte[1024];
for(int i =0;i < 1024 * 128; i++) {
fis.read(buf);
fos.write(buf);
}
//关闭资源 //先关闭输出流,在关闭输入流
org.apache.hadoop.io.IOUtils.closeStream(fos);
org.apache.hadoop.io.IOUtils.closeStream(fis);
fs.close();
}
//下载第二个块
@Test
public void readFileSeek2() throws IOException, InterruptedException, URISyntaxException {
//获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop132:9000"), conf, "root");
//获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.9.2.tar.gz"));
//设置指定的读取的起点
fis.seek(1024*1024*128); //1B*1024=1kb*1024=1M*128=128M
//获取输出流
FileOutputStream fos = new FileOutputStream(new File("f:/TestData/hadoop-2.9.2.tar.gz.part2"));
//流的拷贝
byte[] buf = new byte[1024];
for(int i =0;i < 1024 * 128; i++) {
fis.read(buf);
fos.write(buf);
}
//关闭资源 //先关闭输出流,在关闭输入流
org.apache.hadoop.io.IOUtils.closeStream(fos);
org.apache.hadoop.io.IOUtils.closeStream(fis);
fs.close();
}
//下载剩下的第三块
@Test
public void readFileSeek3() throws IOException, InterruptedException, URISyntaxException {
//获取对象
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop132:9000"), conf, "root");
//获取输入流
FSDataInputStream fis = fs.open(new Path("/hadoop-2.9.2.tar.gz"));
//设置指定的读取的起点 在256M之后进行读取
fis.seek(1024*1024*128*2);
//获取输出流
FileOutputStream fos = new FileOutputStream(new File("f:/TestData/hadoop-2.9.2.tar.gz.part3"));
//流的拷贝
org.apache.hadoop.io.IOUtils.copyBytes(fis, fos, conf);
//关闭资源 //先关闭输出流,在关闭输入流
org.apache.hadoop.io.IOUtils.closeStream(fos);
org.apache.hadoop.io.IOUtils.closeStream(fis);
fs.close();
}


















 9411
9411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









