







第一章:数据载入及初步观察
- 1.4 知道你的数据叫什么
- 1.4.1 任务一:pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们。然后自己写一个关于这两个数据类型的小例子🌰[开放题]
- 1.4.2 任务二:根据上节课的方法载入"train.csv"文件
- 1.4.3 任务三:查看DataFrame数据的每列的名称
- 1.4.4任务四:查看"Cabin"这列的所有值[有多种方法]
- 1.4.5 任务五:加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除
- 1.4.6 任务六: 将['PassengerId','Name','Age','Ticket']这几个列元素隐藏,只观察其他几个列元素
- 1.5 筛选的逻辑
1.4 知道你的数据叫什么
我们学习pandas的基础操作,那么上一节通过pandas加载之后的数据,其数据类型是什么呢?
开始前导入numpy和pandas
import numpy as np
import pandas as pd
1.4.1 任务一:pandas中有两个数据类型DateFrame和Series,通过查找简单了解他们。然后自己写一个关于这两个数据类型的小例子🌰[开放题]
具体区别可以看看上面的文章。
例子的话就试一个简单的:
df=pd.Series([[1,2,3],[4,5,6],[7,8,9]])
df1=pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]])
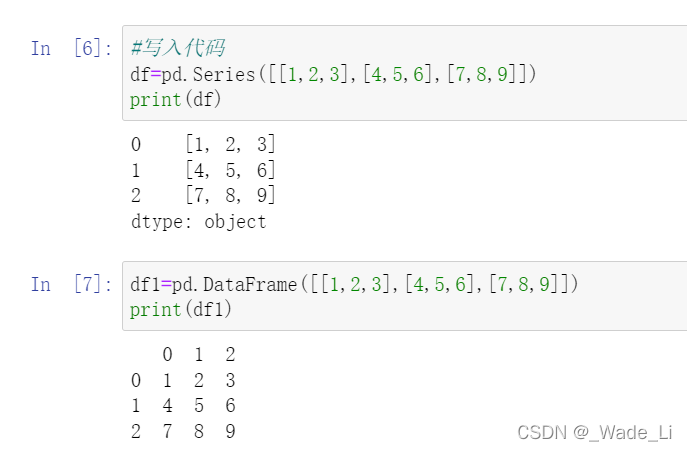
可以很明显看出区别,series只是一个一维数组,没有把数据【1,2,3】分开,而是看成一个整体,放在索引0.
而dataframe是一个二维的数据,把数据的每个值分开。
1.4.2 任务二:根据上节课的方法载入"train.csv"文件
data = pd.read_csv('train.csv')
也可以加载上一节课保存的"train_chinese.csv"文件。通过翻译版train_chinese.csv熟悉了这个数据集,然后我们对trian.csv来进行操作
1.4.3 任务三:查看DataFrame数据的每列的名称
#写入代码
data.columns
#结果
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
1.4.4任务四:查看"Cabin"这列的所有值[有多种方法]
Python笔记:df.loc[]和df.iloc[]的区别
上面博客介绍了提取指定列的方法,学习到了两个函数
df.loc和df.iloc
– loc利用index的名称,来获取想要的行(或列)。
– iloc利用index的具体位置(所以它只能是整数型参数),来获取想要的行(或列)。
感觉loc是具体提取df对象里面的某个值(需要满足行,列,两个条件)
可以用来提取指定行的指定列。
那么实现任务的方法代码是:
data['Cabin']
data.loc[:,'Cabin']
data.iloc[:,10]#Cabin是在第11个标签,索引值为10
1.4.5 任务五:加载文件"test_1.csv",然后对比"train.csv",看看有哪些多出的列,然后将多出的列删除

导入test_1.csv的行标签,对比train.csv的行标签,发现是多了一个a列。
使用drop函数删除列。
【思考】还有其他的删除多余的列的方式吗?
答:观察到a列是在最后一列,我们可以使用loc函数,取前14列的数值。
# 思考回答
test.iloc[:,:13].columns
1.4.6 任务六: 将[‘PassengerId’,‘Name’,‘Age’,‘Ticket’]这几个列元素隐藏,只观察其他几个列元素
#写入代码
df = data.drop(labels=['PassengerId','Name','Age','Ticket'],axis=1)
【思考】对比任务五和任务六,是不是使用了不一样的方法(函数),如果使用一样的函数如何完成上面的不同的要求呢?
【思考回答】这题目的应该是告诉我们,drop函数如果inpace没有设置为1的话,实际上drop函数只是另外新建了个dataframe。如果设置为1,则是在原来的dataframe上修改。
别的方法隐藏列元素的话,想法是读取csv的时候,设置列元素columns的具体列名。
如果想要完全的删除你的数据结构,使用inplace=True,因为使用inplace就将原数据覆盖了,所以这里没有用
答案:
# 删除多余的列
del test_1['a']
test_1.head(3)
del这个真的没用过,学到了!!!
1.5 筛选的逻辑
4、pandas的数据筛选之isin和str.contains函数
筛选可以看这篇博客,挺齐全的。
1.5.1 任务一: 我们以"Age"为筛选条件,显示年龄在10岁以下的乘客信息。
#写入代码
data[data['Age']<10]
1.5.2 任务二: 以"Age"为条件,将年龄在10岁以上和50岁以下的乘客信息显示出来,并将这个数据命名为midage
先给个错误示范:
#写入代码
data[10<data['Age']<50]
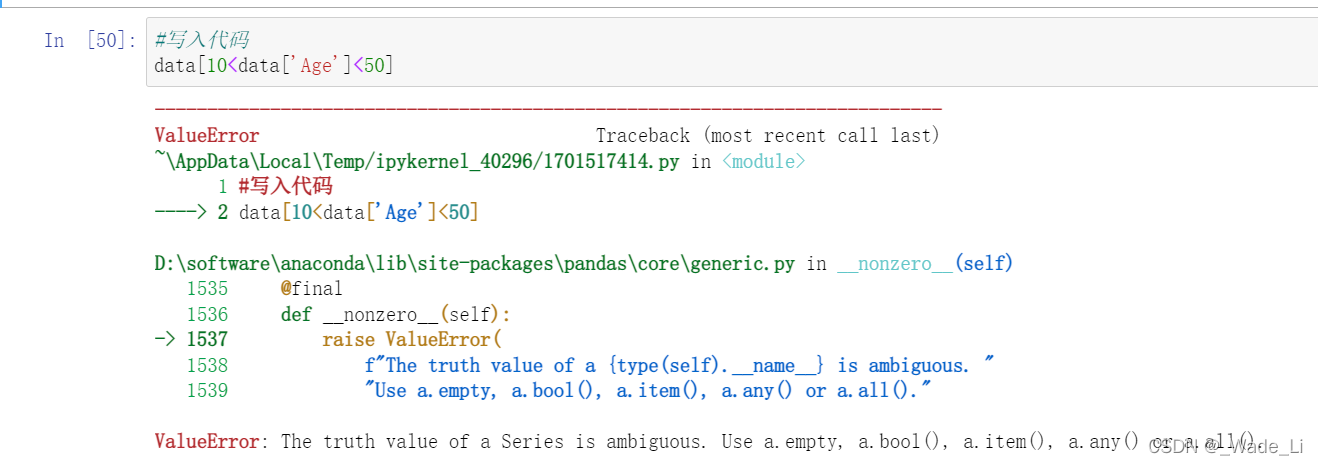
一开始我想当然的就写成10<x<50,但直接报错了,后来看见
原来使用dataframe是需要多种条件结合。于是改为
#写入代码
data[(data['Age']>10)&(data['Age']<50)]
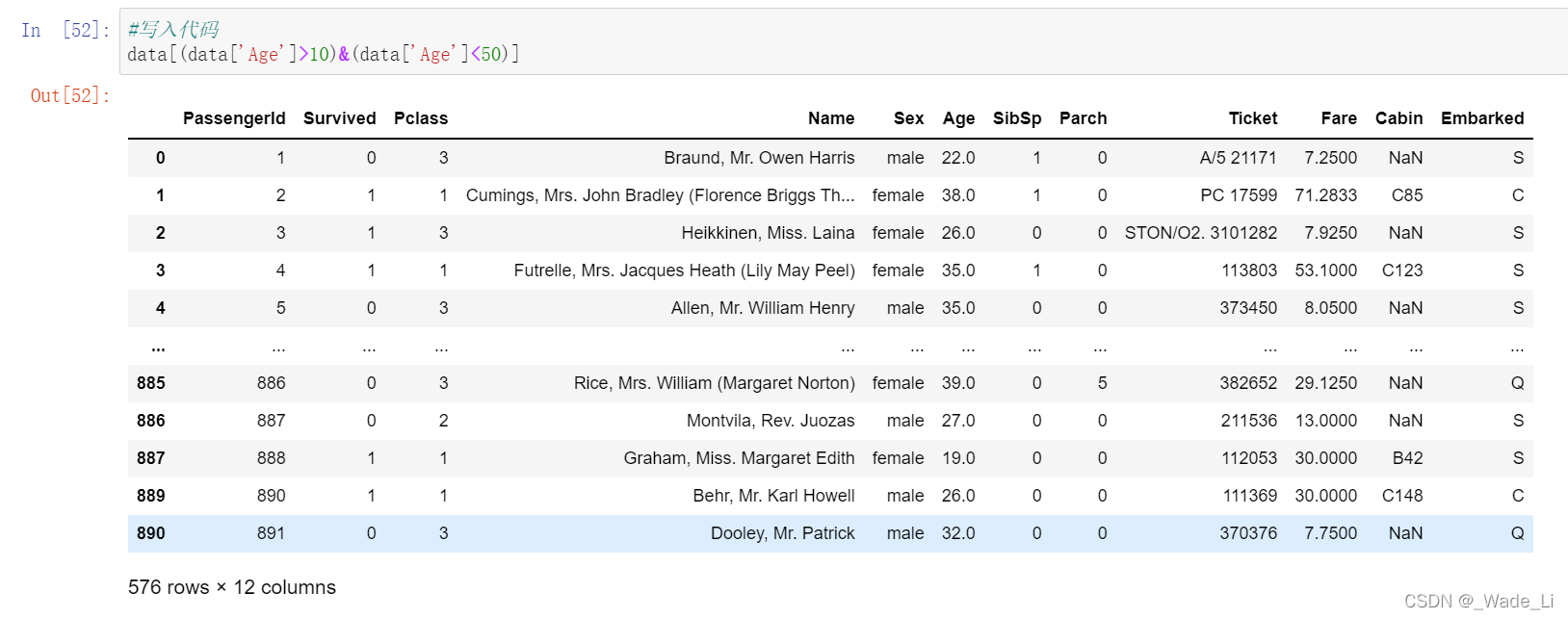
【提示】了解pandas的条件筛选方式以及如何使用交集和并集操作
1.5.3 任务三:将midage的数据中第100行的"Pclass"和"Sex"的数据显示出来
提取具体某行数据,思路是使用loc函数。
错误示范;TypeError: call() takes from 1 to 2 positional arguments but 3 were given
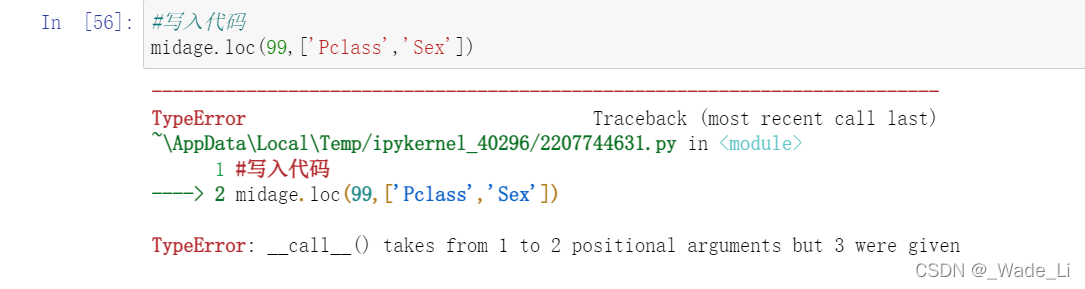
为啥会报这个错呢,哎,还是小白问题,因为loc函数是使用筛选功能是用【】中括号,而不是小括号。
正确示范:
#写入代码
midage.loc[99,['Pclass','Sex']]
#结果
Pclass 2
Sex male
Name: 99, dtype: object
【提示】在抽取数据中,我们希望数据的相对顺序保持不变,用什么函数可以达到这个效果呢?
1.5.4 任务四:使用loc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
1.5.5 任务五:使用iloc方法将midage的数据中第100,105,108行的"Pclass","Name"和"Sex"的数据显示出来
任务四和任务五做完后发现一个奇怪的错误。
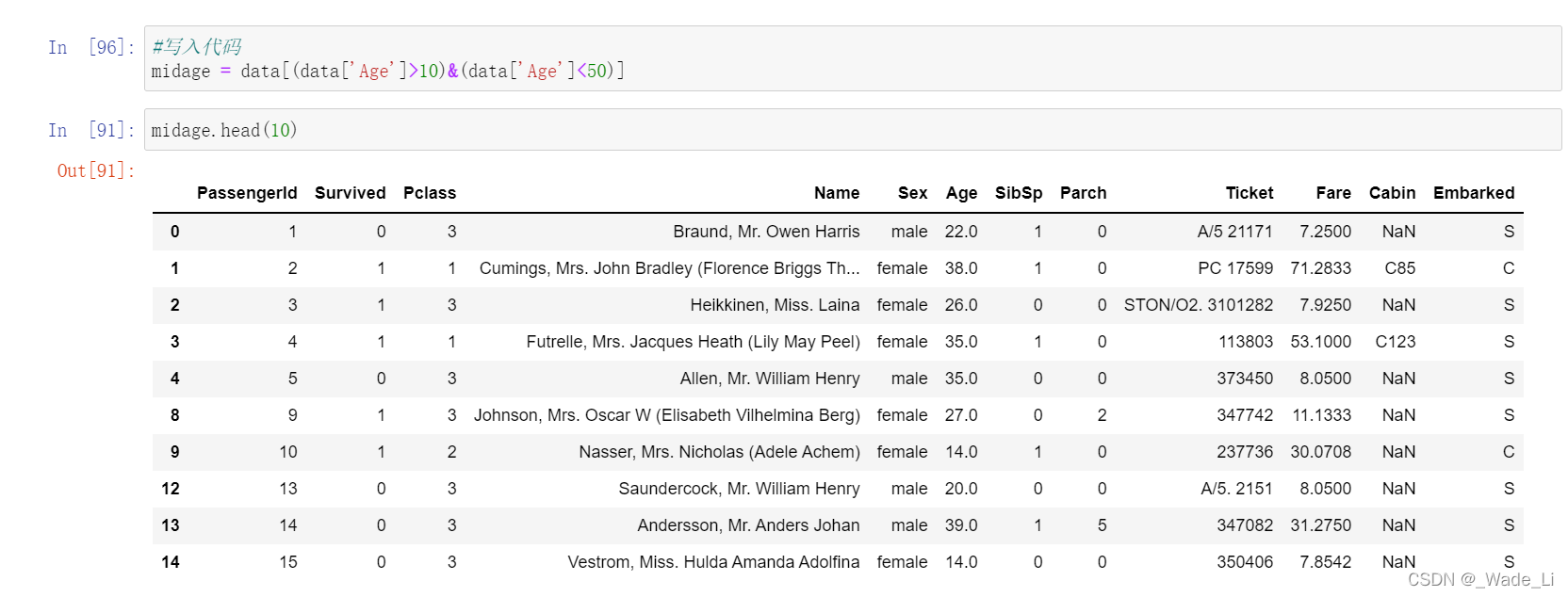
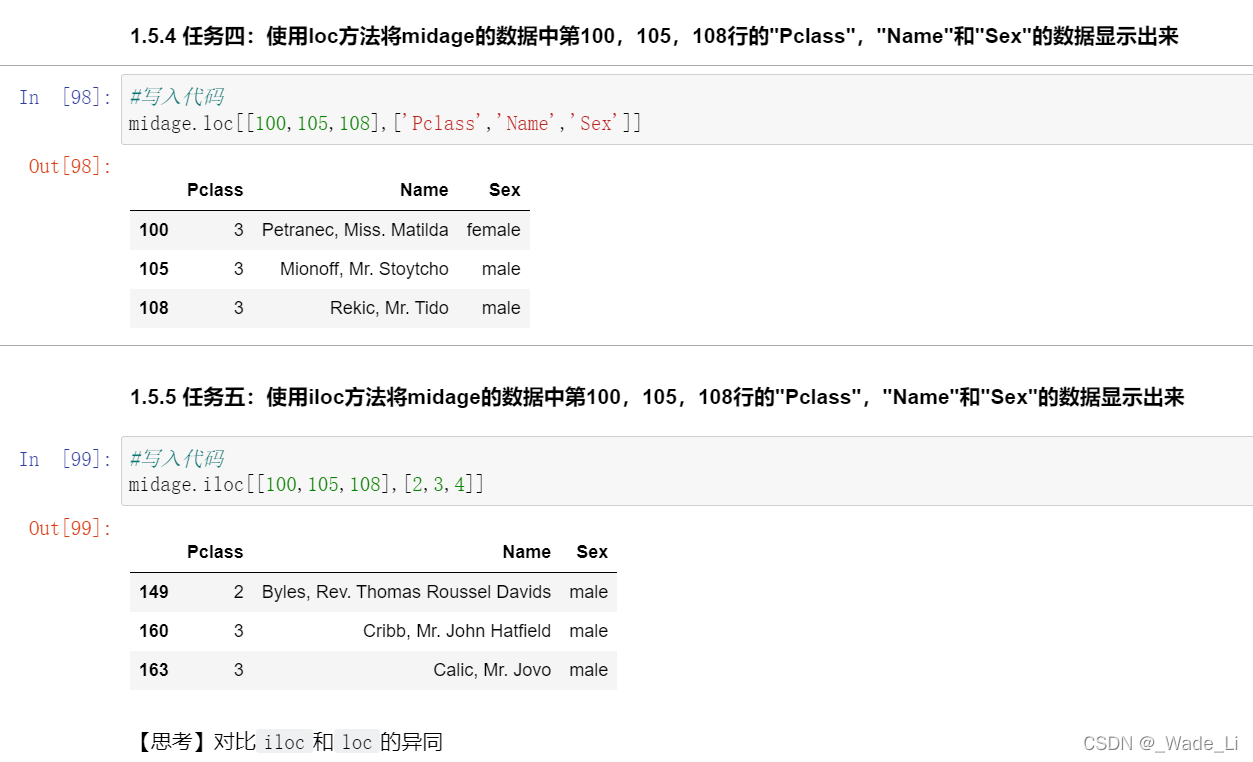
使用loc函数和iloc函数,输出的数据是不一样的。
后来思考发现原因,是因为loc函数是使用的名称索引,它索引出了对应名称为100,105,108行的数据。
但iloc是索引的行数据索引值,所以iloc索引出来的对应实际行的100,105,108行。
对比了答案,发现答案里面有个操作。
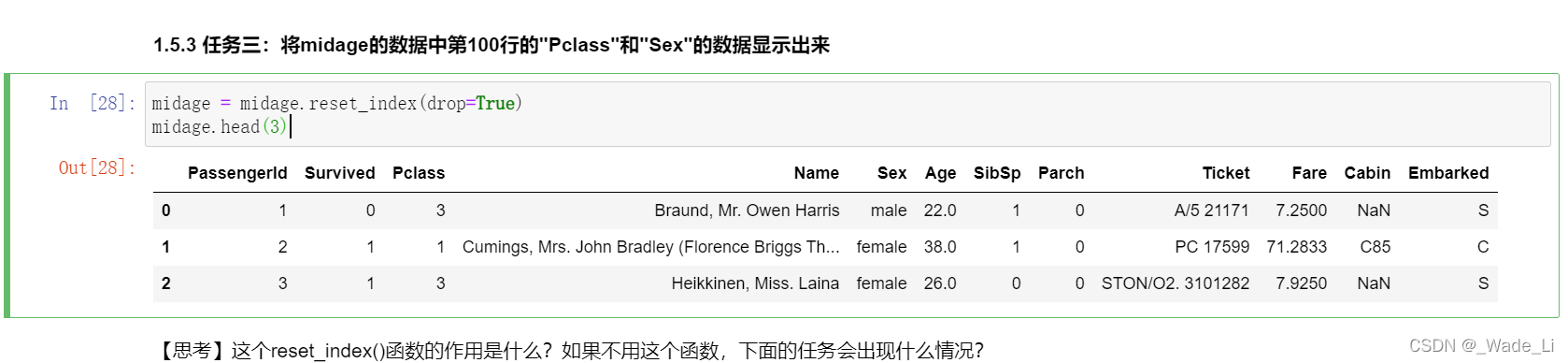
答案里面有这部操作:
midage = midage.reset_index(drop=True)
midage.head(3)
所以reset_index函数有什么作用呢?
(Python)Pandas reset_index()用法总结
作用是重置索引,并抛弃旧索引。这样的话就会使得所有的索引重新按顺序排列。
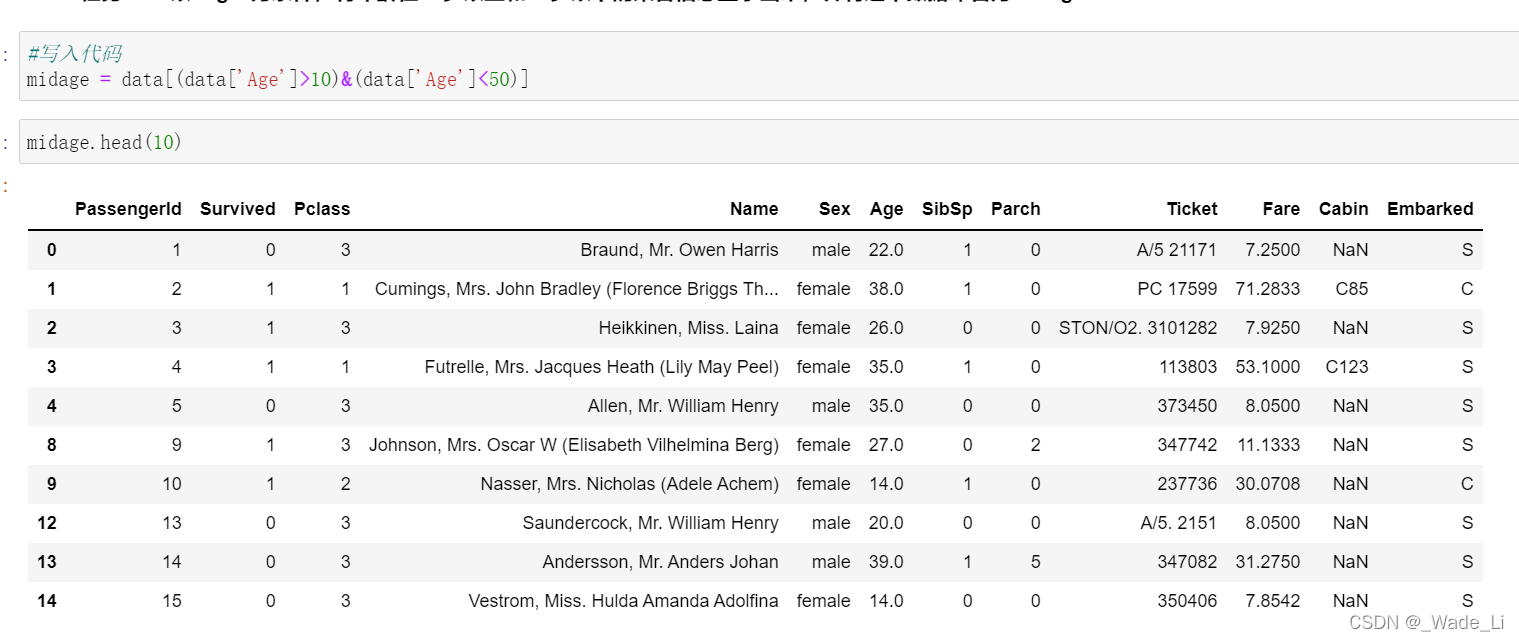
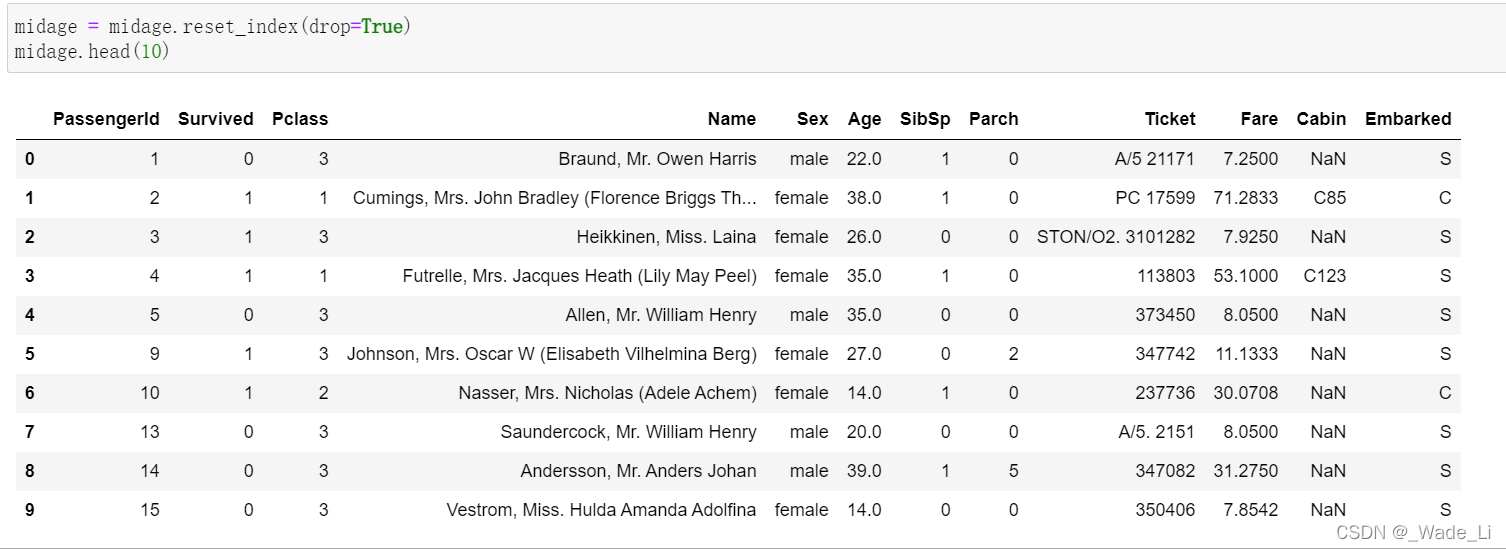
我们可以对比一下使用了reset_index函数之后的midage和使用之前的midage区别。就是索引值变了。
后面使用loc和iloc函数就输出一样的结果了。
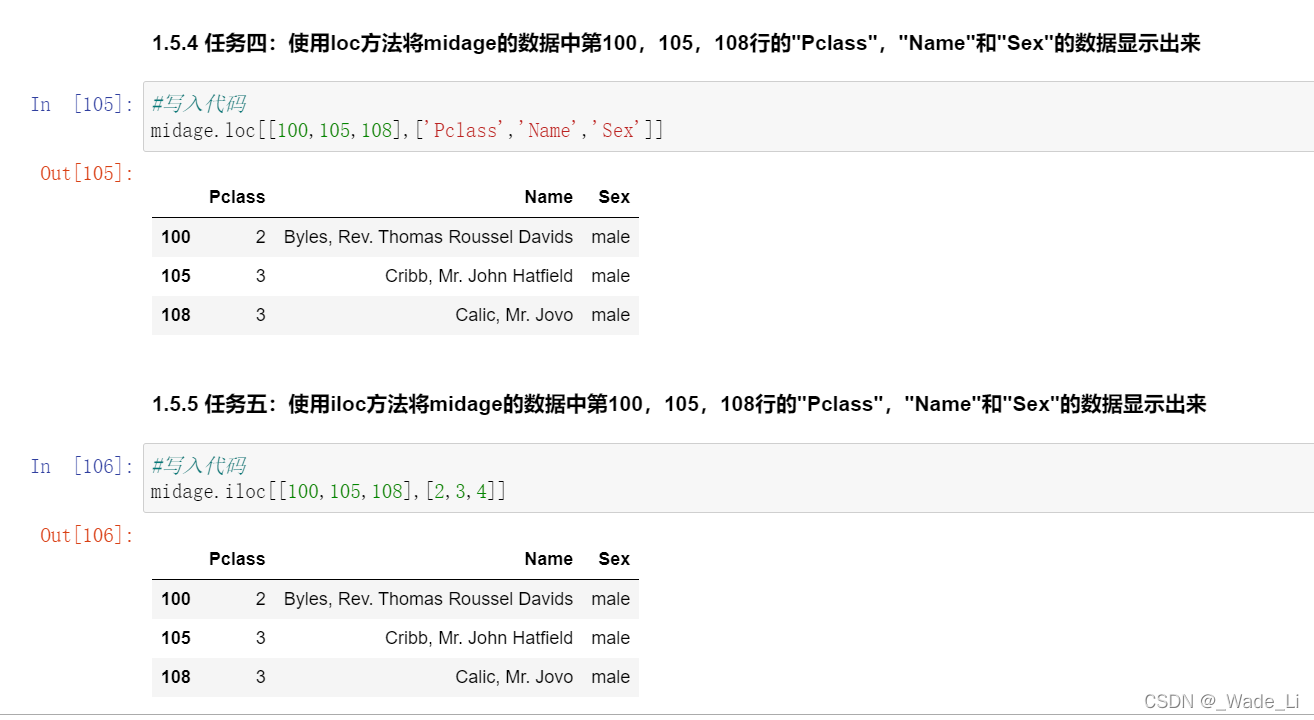
所以说,在使用条件筛选后,记得要用reset_index()函数进行重置索引。
loc是使用名称进行索引
iloc是使用索引值进行索引。
在筛选条件后,名称和索引值会发生变化,不再一一对应。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









