







 本文介绍了在爬取网页时遇到中文以uxxxx格式显示的问题,通过使用requests库获取网页内容,并结合unicode-escape进行解码,成功将Unicode编码转换为汉字。此方法对于处理含有Unicode编码的网页数据具有实用性。
本文介绍了在爬取网页时遇到中文以uxxxx格式显示的问题,通过使用requests库获取网页内容,并结合unicode-escape进行解码,成功将Unicode编码转换为汉字。此方法对于处理含有Unicode编码的网页数据具有实用性。
我用爬虫遇到一个网站,爬到的网页代码如下:
爬的中文全是\uxxxx格式的,使用下面一行代码就可以解决:
get = requests.get(url, proxies=ip, headers=headers)
html = get.text.encode('utf-8').decode("unicode-escape")
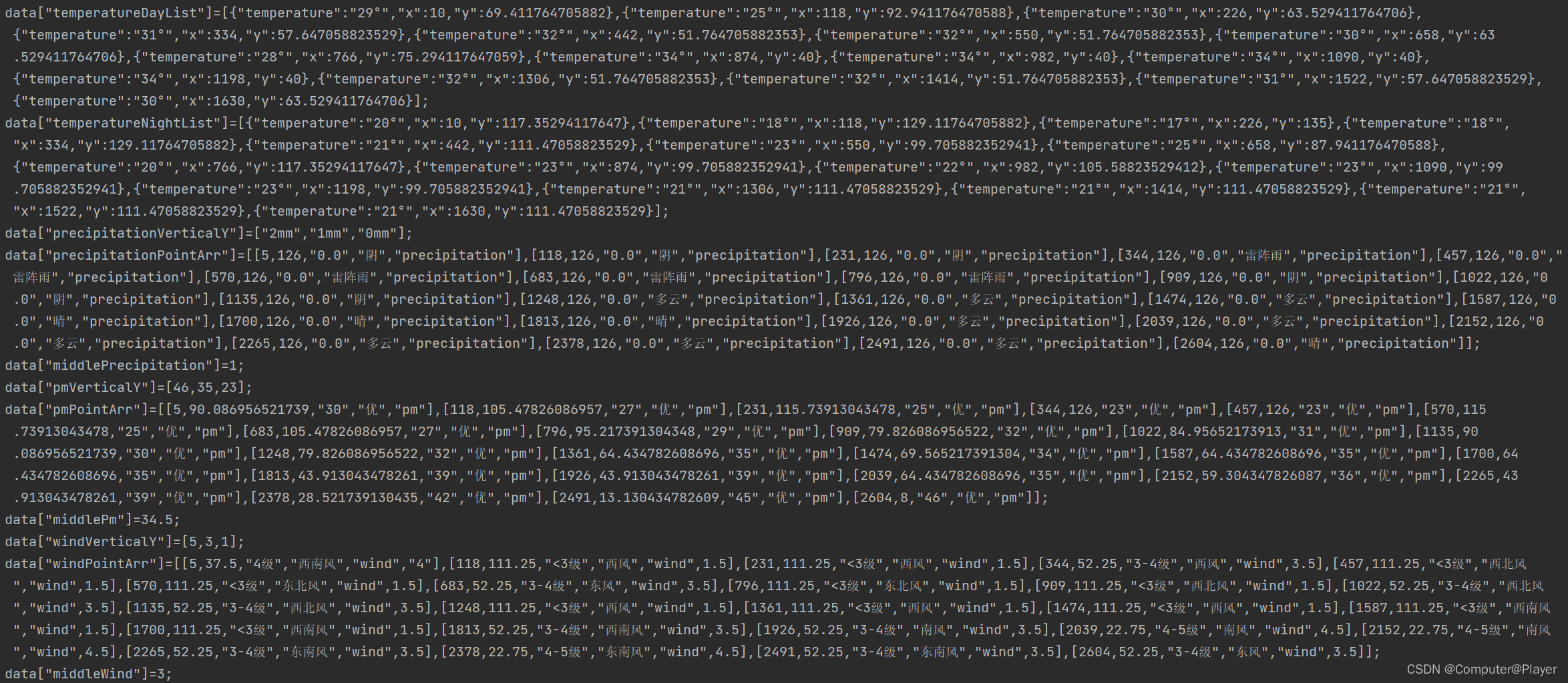
使用unicode-escape进行反编码后得到其对应的汉字。
我用爬虫遇到一个网站,爬到的网页代码如下:
爬的中文全是\uxxxx格式的,使用下面一行代码就可以解决:
get = requests.get(url, proxies=ip, headers=headers)
html = get.text.encode('utf-8').decode("unicode-escape")
使用unicode-escape进行反编码后得到其对应的汉字。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























