







 本文深入浅出地探讨了JavaScript数据类型、类型转换、执行上下文、闭包、原型链、内存管理、性能优化等核心概念,还涉及Vue与React框架的使用技巧,以及Webpack配置详解,最后讲解跨域解决方案与网络原理,适合前端开发者全面复习。
本文深入浅出地探讨了JavaScript数据类型、类型转换、执行上下文、闭包、原型链、内存管理、性能优化等核心概念,还涉及Vue与React框架的使用技巧,以及Webpack配置详解,最后讲解跨域解决方案与网络原理,适合前端开发者全面复习。
部分面试题来自 身为三本的我就是凭借这些前端面试题拿到百度京东offer的,前端面试题2021及答案 对一些面试题做了补充,补全了一些面试题。
JS
数据类型
面 试 官 : J a v a S c r i p t 中 什 么 是 基 本 数 据 类 型 什 么 是 引 用 数 据 类 型 ? 以 及 各 个 数 据 类 型 是 如 何 存 储 的 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:JavaScript中什么是基本数据类型什么是引用数据类型?以及各个数据类型是如何存储的?⭐⭐⭐⭐⭐} 面试官:JavaScript中什么是基本数据类型什么是引用数据类型?以及各个数据类型是如何存储的?⭐⭐⭐⭐⭐
- 基本的数据类型有:
- Number
- String
- Boolean
- Null
- Undefined
- Symbol(ES6新增数据类型,表示独一无二)
- bigInt(一种数据类型,任意长度的整数)
- 引用数据类型统称为Object类型,细分的话有
- Object
- Array
- Date
- Function
- RegExp
- 基本数据类型的数据直接存储在栈中;而引用数据类型的数据存储在堆中,在栈中保存数据的引用地址,这个引用地址指向的是对应的数据,以便快速查找到堆内存中的对象。
- 顺便提一句,栈内存是自动分配内存的。而堆内存是动态分配内存的,不会自动释放。所以每次使用完对象的时候都要把它设置为null,从而减少无用内存的消耗
类型转换
面 试 官 : 在 J S 中 为 什 么 0.2 + 0.1 > 0.3 ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:在JS中为什么0.2+0.1>0.3?⭐⭐⭐⭐} 面试官:在JS中为什么0.2+0.1>0.3?⭐⭐⭐⭐
因为在JS中,浮点数是使用64位固定长度来表示的,其中的1位表示符号位,11位用来表示指数位,剩下的52位尾数位,由于只有52位表示尾数位。
而0.1转为二进制是一个无限循环数0.0001100110011001100......(1100循环)
小数的十进制转二进制方法:https://jingyan.baidu.com/article/425e69e6e93ca9be15fc1626.html
要知道,小数的十进制转二进制的方法是和整数不一样的,推荐看一看
由于只能存储52位尾数位,所以会出现精度缺失,把它存到内存中再取出来转换成十进制就不是原来的0.1了,就变成了0.100000000000000005551115123126,而为什么02+0.1是因为
// 0.1 和 0.2 都转化成二进制后再进行运算
0.00011001100110011001100110011001100110011001100110011010 +
0.0011001100110011001100110011001100110011001100110011010 =
0.0100110011001100110011001100110011001100110011001100111
面
试
官
:
那
为
什
么
0.2
+
0.3
=
0.5
呢
?
⭐
⭐
⭐
⭐
\color{#0000FF}{面试官:那为什么0.2+0.3=0.5呢?⭐⭐⭐⭐}
面试官:那为什么0.2+0.3=0.5呢?⭐⭐⭐⭐
// 0.2 和 0.3 都转化为二进制后再进行计算
0.001100110011001100110011001100110011001100110011001101 +
0.0100110011001100110011001100110011001100110011001101 =
0.10000000000000000000000000000000000000000000000000001 //尾数为大于52位
// 而实际取值只取52位尾数位,就变成了
0.1000000000000000000000000000000000000000000000000000//0.5
答:0.2 和0.3分别转换为二进制进行计算:在内存中,它们的尾数位都是等于52位的,而他们相加必定大于52位,而他们相加又恰巧前52位尾数都是0,截取后恰好是01000000000000000000000000000000000000000000000000000也就是0.5
// 转成十进制正好是 0.30000000000000004
面 试 官 : 那 既 然 0.1 不 是 0.1 了 , 为 什 么 在 c o n s o l e . l o g ( 0.1 ) 的 时 候 还 是 0.1 呢 ? ⭐ ⭐ ⭐ \color{#0000FF}{面试官:那既然0.1不是0.1了,为什么在console.log(0.1)的时候还是0.1呢?⭐⭐⭐} 面试官:那既然0.1不是0.1了,为什么在console.log(0.1)的时候还是0.1呢?⭐⭐⭐
在console.log的时候会二进制转换为十进制,十进制再会转为字符串的形式,在转换的过程中发生了取近似值,所以打印出来的是一个近似值的字符串
面
试
官
:
判
断
数
据
类
型
有
几
种
方
法
⭐
⭐
⭐
⭐
⭐
\color{#0000FF}{面试官:判断数据类型有几种方法⭐⭐⭐⭐⭐}
面试官:判断数据类型有几种方法⭐⭐⭐⭐⭐
四种
typeof
缺点:typeof null的值为Object,无法分辨是null还是Objectinstanceof
缺点:只能判断对象是否存在于目标对象的原型链上constructor
缺点:不能判断undefined和nullObject.prototype.toString.call()
缺点:不能细分为谁谁的实例
一种最好的基本类型检测方式 Object.prototype.toString.call() ;它可以区分 null 、 string 、boolean 、 number 、 undefined 、 array 、 function 、 object 、 date 、 math 数据类型。
// -----------------------------------------typeof
typeof undefined // 'undefined'
typeof '10' // 'String'
typeof 10 // 'Number'
typeof false // 'Boolean'
typeof Symbol() // 'Symbol'
typeof Function // ‘function'
typeof null // ‘Object’
typeof [] // 'Object'
typeof {} // 'Object'
// -----------------------------------------instanceof
function Foo() { }
var f1 = new Foo();
var d = new Number(1)
console.log(f1 instanceof Foo);// true
console.log(d instanceof Number); //true
console.log(123 instanceof Number); //false -->不能判断字面量的基本数据类型
// -----------------------------------------constructor
var d = new Number(1)
var e = 1
function fn() {
console.log("ming");
}
var date = new Date();
var arr = [1, 2, 3];
var reg = /[hbc]at/gi;
console.log(e.constructor);//ƒ Number() { [native code] }
console.log(e.constructor.name);//Number
console.log(fn.constructor.name) // Function
console.log(date.constructor.name)// Date
console.log(arr.constructor.name) // Array
console.log(reg.constructor.name) // RegExp
//-----------------------------------------Object.prototype.toString.call()
console.log(Object.prototype.toString.call(undefined)); // "[object Undefined]"
console.log(Object.prototype.toString.call(null)); // "[object Null]"
console.log(Object.prototype.toString.call(123)); // "[object Number]"
console.log(Object.prototype.toString.call("abc")); // "[object String]"
console.log(Object.prototype.toString.call(true)); // "[object Boolean]"
function fn() {
console.log("ming");
}
var date = new Date();
var arr = [1, 2, 3];
var reg = /[hbc]at/gi;
console.log(Object.prototype.toString.call(fn));// "[object Function]"
console.log(Object.prototype.toString.call(date));// "[object Date]"
console.log(Object.prototype.toString.call(arr)); // "[object Array]"
console.log(Object.prototype.toString.call(reg));// "[object RegExp]"
i n s t a n c e o f 原 理 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{instanceof原理⭐⭐⭐⭐⭐} instanceof原理⭐⭐⭐⭐⭐
//instanceof原理实际上就是查找目标对象的原型链
function myInstance(L, R) {//L代表instanceof左边,R代表右边
var RP = R.prototype
var LP = L.__proto__
while (true) {
if(LP == null) {
return false
}
if(LP == RP) {
return true
}
LP = LP.__proto__
}
}
console.log(myInstance({},Object));
面 试 官 : 为 什 么 t y p e o f n u l l 是 O b j e c t ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:为什么typeof null是Object⭐⭐⭐⭐} 面试官:为什么typeofnull是Object⭐⭐⭐⭐
因为在JavaScript中,不同的对象都是使用二进制存储的,如果二进制前三位都是0的话,系统会判断为是Object类型,而null的二进制全是0,自然也就判断为Object
这个bug是初版本的JavaScript中留下的,扩展一下其他五种标识位:
000 对象
1 整型
010 双精度类型
100字符串
110布尔类型
面 试 官 : = = 和 = = = 有 什 么 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:==和===有什么区别⭐⭐⭐⭐⭐} 面试官:==和===有什么区别⭐⭐⭐⭐⭐
- ===是严格意义上的相等,会比较两边的数据类型和值大小
- 数据类型不同返回false
- 数据类型相同,但值大小不同,返回false
- ==是非严格意义上的相等,
- 两边类型相同,比较大小
- 两边类型不同,根据下方表格,再进一步进行比较。
Null == Undefined ->true
String == Number ->先将String转为Number,在比较大小
Boolean == Number ->现将Boolean转为Number,在进行比较
Object == String,Number,Symbol -> Object 转化为原始类型
面 试 官 : 手 写 c a l l 、 a p p l y 、 b i n d ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:手写call、apply、bind⭐⭐⭐⭐⭐} 面试官:手写call、apply、bind⭐⭐⭐⭐⭐
- call和apply实现思路主要是:
- 判断是否是函数调用,若非函数调用抛异常
- 通过新对象(context)来调用函数
- 给context创建一个fn设置为需要调用的函数
- 结束调用完之后删除fn
- bind实现思路
- 判断是否是函数调用,若非函数调用抛异常
- 返回函数
- 判断函数的调用方式,是否是被new出来的
- new出来的话返回空对象,但是实例的__proto__指向_this的prototype
- 完成函数柯里化
Array.prototype.slice.call()
call:
Function.prototype.myCall = function (context) {
// 先判断调用myCall是不是一个函数
// 这里的this就是调用myCall的
if (typeof this !== 'function') {
throw new TypeError("Not a Function")
}
// 不传参数默认为window
context = context || window
// 保存this
context.fn = this
// 保存参数
let args = Array.from(arguments).slice(1) //Array.from 把伪数组对象转为数组
// 调用函数
let result = context.fn(...args)
delete context.fn
return result
}
apply
Function.prototype.myApply = function (context) {
// 判断this是不是函数
if (typeof this !== "function") {
throw new TypeError("Not a Function")
}
let result
// 默认是window
context = context || window
// 保存this
context.fn = this
// 是否传参
if (arguments[1]) {
result = context.fn(...arguments[1])
} else {
result = context.fn()
}
delete context.fn
return result
}
bind
Function.prototype.myBind = function(context){
// 判断是否是一个函数
if(typeof this !== "function") {
throw new TypeError("Not a Function")
}
// 保存调用bind的函数
const _this = this
// 保存参数
const args = Array.prototype.slice.call(arguments,1)
// 返回一个函数
return function F () {
// 判断是不是new出来的
if(this instanceof F) {
// 如果是new出来的
// 返回一个空对象,且使创建出来的实例的__proto__指向_this的prototype,且完成函数柯里化
return new _this(...args,...arguments)
}else{
// 如果不是new出来的改变this指向,且完成函数柯里化
return _this.apply(context,args.concat(...arguments))
}
}
}
面 试 官 : 字 面 量 创 建 对 象 和 n e w 创 建 对 象 有 什 么 区 别 , n e w 内 部 都 实 现 了 什 么 , 手 写 一 个 n e w ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:字面量创建对象和new创建对象有什么区别,new内部都实现了什么,手写一个new⭐⭐⭐⭐⭐} 面试官:字面量创建对象和new创建对象有什么区别,new内部都实现了什么,手写一个new⭐⭐⭐⭐⭐
- 字面量:
- 字面量创建对象更简单,方便阅读
- 不需要作用域解析,速度更快
- new内部:
- 创建一个新对象
- 使新对象的__proto__指向原函数的prototype
- 改变this指向(指向新的obj)并执行该函数,执行结果保存起来作为result
- 判断执行函数的结果是不是null或Undefined,如果是则返回之前的新对象,如果不是则返回result
- 手写new
// 手写一个new
function myNew(fn, ...args) {
// 创建一个空对象
let obj = {}
// 使空对象的隐式原型指向原函数的显式原型
obj.__proto__ = fn.prototype
// this指向obj
let result = fn.apply(obj, args)
// 返回
return result instanceof Object ? result : obj
}
面 试 官 : 字 面 量 n e w 出 来 的 对 象 和 O b j e c t . c r e a t e ( n u l l ) 创 建 出 来 的 对 象 有 什 么 区 别 ⭐ ⭐ ⭐ \color{#0000FF}{面试官:字面量new出来的对象和 Object.create(null)创建出来的对象有什么区别⭐⭐⭐} 面试官:字面量new出来的对象和Object.create(null)创建出来的对象有什么区别⭐⭐⭐
- 字面量new创建出来的对象会继承Object的方法和属性,他们的隐式原型会指向Object的显式原型,
- 而 Object.create(null)创建出来的对象原型为null,作为原型链的顶端,自然也没有继承Object的方法和属性
数组
常用的数组方法:map, forEach, sort, filter, every, some, reduce, push, pop, shift, unshift, isArray, contact, toString, join, splice, slice, find
// map: 能操作数组中的元素,返回一个新的数组,不会更改原数组
const arr1 = arr.map(i => i * 2);
console.log(arr, arr1)
// forEach: 遍历数组,没有返回值
const arr2 = arr;
arr2.forEach(i => i * 2);
console.log(arr2);
// sort: 数组排序
const arr3 = [5, 32, 1, 6, 432];
console.log(arr3.sort());
// filter: 过滤满足条件的数据,返回一个新的数组
const arr4 = arr.filter(i => i === 1);
console.log(arr4);
// every: 数组中的所有元素满足条件,返回true,否则false
const arr5 = arr.every(i => typeof i !== Number);
console.log(arr5);
// some: 数组中有一个元素满足条件,返回true, 否则false
const arr6 = arr.some(i => typeof i === Number);
console.log(arr6);
// reduce: 可以作为一个累加器;可以作为一个高阶函数,用于函数的compose
const total = arr.reduce((total, i) => {
return total + i;
})
console.log('total', total);
// push: 向数组末尾添加元素
console.log(arr.push(8));
// pop: 删除数组末尾元素
console.log(arr.pop());
// shift: 删除数组第一个元素
console.log(arr.shift());
// unshift: 向数组头部添加元素
console.log(arr.unshift(1));
// isArray: 判断是否是数组
console.log(Array.isArray(arr));
// contact: 拼接多个数组为一个数组
const arr7 = [55, 66];
console.log(arr.concat(arr7));
// toString: 将数组转为字符串
console.log(arr.toString());
// join: 将字符转为字符串
console.log(arr.join(""))
// splice: 能实现数组的增删改,三个参数:开始位置,删除个数,元素
// 增加一个元素
console.log(arr)
let arr8 = arr;
console.log(arr8.splice(2, 0, 23))
// 修改一个元素
const arr9 = arr;
console.log(arr.splice(2, 1, 22));
// 删除一个元素
const arr10 = arr;
console.log(arr.splice(2,1))
// slice: 在一个数组中,按照条件查出其中的部分内容,返回一个新数组;两个参数:开始索引位置,结束索引位置,不包括结束索引位置的数据
console.log(arr.slice(1,3))
// find: 查找数组中第一个满足条件的数据;find的参数为function
const arr11 = [1, 1, 2, 2, 3, 3]
console.log(arr11.find((i) => {
return i == 2
}))
r e d u c e 的 高 阶 用 法 \color{#0000FF}{reduce的高阶用法} reduce的高阶用法
- reduce语法
- callback:回调函数
- initValue:初始值
arr.reduce(callback, initValue)
- 用作累加器
function total(arr) {
return arr.reduce((pre, cur) => pre + cur, 0);
}
- 替代reverse
// reduceRight() 方法接受一个函数作为累加器(accumulator)和数组的每个值(从右到左)将其减少为单个值
function reverseStr() {
return str.split('').reduceRight((items, item) => items + item);
}
- 替代map和filter
// 替代map
function replaceMap(arr) {
return arr.reduce((pre,cur) => {
return [...pre, cur * 2]
}, [])
}
// 替代filter
function replaceFilter(arr) {
return arr.reduce((pre, cur) => {
return cur > 2 ? [...pre, cur] : pre
}, [])
}
// 替代map和filer
function replaceMapAndFilter(arr) {
return arr.reduce((pre, cur) => {
return cur * 2 > 4 ? [...pre, cur * 2] : pre
}, [])
}
console.log(replaceMap([1, 2, 3])); // [2, 4, 6]
console.log(replaceFilter([1, 2, 3, 4])); // [3, 4]
console.log(replaceMapAndFilter([1, 2, 3, 4])) // [6, 8]
- 替代some和every
// 替代some
function replaceSome(arr) {
return arr.reduce((pre, cur) => {
return pre || cur > 2;
}, false)
}
// 替代every
function replaceEvery(arr) {
return arr.reduce((pre, cur) => {
return pre && cur > 2
}, true)
}
console.log(replaceSome([1, 2, 3])) // true
console.log(replaceEvery([1, 2, 3])) // false
- 数组分割
// 数组分割
function chunk(arr, size = 1) {
return arr.length ? arr.reduce((pre, cur) => {
return pre[pre.length - 1].length == size ?
pre.push([cur]) : pre[pre.length - 1].push(cur), pre
}, [[]]) : []
}
console.log(chunk([1, 2, 3, 4, 5, 6], 2)) //[ [ 1, 2 ], [ 3, 4 ], [ 5, 6 ] ]
- 计算数组中每个元素出现的次数
function count(arr) {
return arr.reduce((pre, cur) => {
return pre[cur] = (pre[cur] || 0) + 1, pre
}, {})
}
console.log(count([1, 1, 2, 3, 4])) { '1': 2, '2': 1, '3': 1, '4': 1 }
- 将二维数组降为一维数组
//reduce+concat封装函数递归实现数组降维
function flat(arr) {
if (!Array.isArray(arr)) {
return
}
// return arr.reduce((pre, cur) => {
// return pre.concat(Array.isArray(cur) ? flat(cur) : cur)
// }, [])
return arr.reduce((pre, cur) => {
return Array.isArray(cur) ? pre.concat(flat(cur)) : pre.concat(cur)
}, [])
}
console.log(flat([1, [23], 2, [12]])) //[ 1, 23, 2, 12 ]
执行栈和执行上下文
面 试 官 : 什 么 是 作 用 域 , 什 么 是 作 用 域 链 ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:什么是作用域,什么是作用域链?⭐⭐⭐⭐} 面试官:什么是作用域,什么是作用域链?⭐⭐⭐⭐
- 规定变量和函数的可使用范围称作作用域
- 每个函数都有一个作用域链,查找变量或者函数时,需要从局部作用域到全局作用域依次查找,这些作用域的集合称作作用域链。
面 试 官 : 什 么 是 执 行 栈 , 什 么 是 执 行 上 下 文 ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:什么是执行栈,什么是执行上下文?⭐⭐⭐⭐} 面试官:什么是执行栈,什么是执行上下文?⭐⭐⭐⭐
执行上下文分为:
-
全局执行上下文
创建一个全局的window对象,并规定this指向window,执行js的时候就压入栈底,关闭浏览器的时候才弹出 -
函数执行上下文
-
每次函数调用时,都会新创建一个函数执行上下文
-
执行上下文分为创建阶段和执行阶段
- 创建阶段:函数环境会创建变量对象:arguments对象(并赋值)、函数声明(并赋值)、变量声明(不赋值),函数表达式声明(不赋值);会确定this指向;会确定作用域
- 执行阶段:变量赋值、函数表达式赋值,使变量对象编程活跃对象
-
-
eval执行上下文
-
执行栈:
- 首先栈特点:先进后出
- 当进入一个执行环境,就会创建出它的执行上下文,然后进行压栈,当程序执行完成时,它的执行上下文就会被销毁,进行弹栈。
- 栈底永远是全局环境的执行上下文,栈顶永远是正在执行函数的执行上下文
- 只有浏览器关闭的时候全局执行上下文才会弹出
闭包
很多人都吃不透js闭包,这里推荐一篇文章:彻底理解闭包
面 试 官 : 什 么 是 闭 包 ? 闭 包 的 作 用 ? 闭 包 的 应 用 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:什么是闭包?闭包的作用?闭包的应用?⭐⭐⭐⭐⭐} 面试官:什么是闭包?闭包的作用?闭包的应用?⭐⭐⭐⭐⭐
函数执行,形成私有的执行上下文,使内部私有变量不受外界干扰,起到保护和保存的作用
作用:
- 保护
- 避免命名冲突
- 保存
- 解决循环绑定引发的索引问题
- 变量不会销毁
- 可以使用函数内部的变量,使变量不会被垃圾回收机制回收
应用:
- 设计模式中的单例模式
- for循环中的保留i的操作
- 防抖和节流
- 函数柯里化
缺点:
- 会出现内存泄漏的问题
原型和原型链
面 试 官 : 什 么 是 原 型 ? 什 么 是 原 型 链 ? 如 何 理 解 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:什么是原型?什么是原型链?如何理解⭐⭐⭐⭐⭐} 面试官:什么是原型?什么是原型链?如何理解⭐⭐⭐⭐⭐
- 原型: 原型分为隐式原型和显式原型,每个对象都有一个隐式原型,它指向自己的构造函数的显式原型。
- 原型链: 多个__proto__组成的集合成为原型链
- 所有实例的__proto__都指向他们构造函数的prototype
- 所有的prototype都是对象,自然它的__proto__指向的是Object()的prototype
- 所有的构造函数的隐式原型指向的都是Function()的显示原型
- Object的隐式原型是null
继承
面 试 官 : 说 一 说 J S 中 的 常 用 的 继 承 方 式 有 哪 些 ? 以 及 各 个 继 承 方 式 的 优 缺 点 。 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:说一说 JS 中的常用的继承方式有哪些?以及各个继承方式的优缺点。⭐⭐⭐⭐⭐} 面试官:说一说JS中的常用的继承方式有哪些?以及各个继承方式的优缺点。⭐⭐⭐⭐⭐
原型继承、组合继承、寄生组合继承、ES6的extend
原型继承
// ----------------------方法一:原型继承
// 原型继承
// 把父类的实例作为子类的原型
// 缺点:子类的实例共享了父类构造函数的引用属性 不能传参
var person = {
friends: ["a", "b", "c", "d"]
}
var p1 = Object.create(person)
p1.friends.push("aaa")//缺点:子类的实例共享了父类构造函数的引用属性
console.log(p1);
console.log(person);//缺点:子类的实例共享了父类构造函数的引用属性
组合继承
// ----------------------方法二:组合继承
// 在子函数中运行父函数,但是要利用call把this改变一下,
// 再在子函数的prototype里面new Father() ,使Father的原型中的方法也得到继承,最后改变Son的原型中的constructor
// 缺点:调用了两次父类的构造函数,造成了不必要的消耗,父类方法可以复用
// 优点可传参,不共享父类引用属性
function Father(name) {
this.name = name
this.hobby = ["篮球", "足球", "乒乓球"]
}
Father.prototype.getName = function () {
console.log(this.name);
}
function Son(name, age) {
Father.call(this, name)
this.age = age
}
Son.prototype = new Father()
Son.prototype.constructor = Son
var s = new Son("ming", 20)
console.log(s);
寄生组合继承
// ----------------------方法三:寄生组合继承
function Father(name) {
this.name = name
this.hobby = ["篮球", "足球", "乒乓球"]
}
Father.prototype.getName = function () {
console.log(this.name);
}
function Son(name, age) {
Father.call(this, name)
this.age = age
}
Son.prototype = Object.create(Father.prototype)
Son.prototype.constructor = Son
var s2 = new Son("ming", 18)
console.log(s2);
extend
// ----------------------方法四:ES6的extend(寄生组合继承的语法糖)
// 子类只要继承父类,可以不写 constructor ,一旦写了,则在 constructor 中的第一句话
// 必须是 super 。
class Son3 extends Father { // Son.prototype.__proto__ = Father.prototype
constructor(y) {
super(200) // super(200) => Father.call(this,200)
this.y = y
}
}
内存泄露、垃圾回收机制
面 试 官 : 什 么 是 内 存 泄 漏 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:什么是内存泄漏⭐⭐⭐⭐⭐} 面试官:什么是内存泄漏⭐⭐⭐⭐⭐
内存泄露是指不再用的内存没有被及时释放出来,导致该段内存无法被使用就是内存泄漏
面 试 官 : 为 什 么 会 导 致 的 内 存 泄 漏 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:为什么会导致的内存泄漏⭐⭐⭐⭐⭐} 面试官:为什么会导致的内存泄漏⭐⭐⭐⭐⭐
内存泄漏指我们无法在通过js访问某个对象,而垃圾回收机制却认为该对象还在被引用,因此垃圾回收机制不会释放该对象,导致该块内存永远无法释放,积少成多,系统会越来越卡以至于崩溃
面 试 官 : 垃 圾 回 收 机 制 都 有 哪 些 策 略 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:垃圾回收机制都有哪些策略?⭐⭐⭐⭐⭐} 面试官:垃圾回收机制都有哪些策略?⭐⭐⭐⭐⭐
-
标记清除法
垃圾回收机制获取根并标记他们,然后访问并标记所有来自它们的引用,然后在访问这些对象并标记它们的引用…如此递进结束后若发现有没有标记的(不可达的)进行删除,进入执行环境的不能进行删除
-
引用计数法
当声明一个变量并给该变量赋值一个引用类型的值时候,该值的计数+1,当该值赋值给另一个变量的时候,该计数+1,当该值被其他值取代的时候,该计数-1,当计数变为0的时候,说明无法访问该值了,垃圾回收机制清除该对象
缺点: 当两个对象循环引用的时候,引用计数无计可施。如果循环引用多次执行的话,会造成崩溃等问题。所以后来被标记清除法取代。
深拷贝和浅拷贝
手 写 浅 拷 贝 深 拷 贝 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{手写浅拷贝深拷贝⭐⭐⭐⭐⭐} 手写浅拷贝深拷贝⭐⭐⭐⭐⭐
// ----------------------------------------------浅拷贝
// 只是把对象的属性和属性值拷贝到另一个对象中
var obj1 = {
a: {
a1: { a2: 1 },
a10: { a11: 123, a111: { a1111: 123123 } }
},
b: 123,
c: "123"
}
// 方式1
function shallowClone1(o) {
let obj = {}
for (let i in o) {
obj[i] = o[i]
}
return obj
}
// 方式2
var shallowObj2 = { ...obj1 }
// 方式3
var shallowObj3 = Object.assign({}, obj1)
let shallowObj = shallowClone1(obj1);
shallowObj.a.a1 = 999
shallowObj.b = true
console.log(obj1); //第一层的没有被改变,一层以下就被改变了
// ----------------------------------------------深拷贝
// 简易版
function deepClone(o) {
let obj = {}
for (var i in o) {
// if(o.hasOwnProperty(i)){
if (typeof o[i] === "object") {
obj[i] = deepClone(o[i])
} else {
obj[i] = o[i]
}
// }
}
return obj
}
var myObj = {
a: {
a1: { a2: 1 },
a10: { a11: 123, a111: { a1111: 123123 } }
},
b: 123,
c: "123"
}
var deepObj1 = deepClone(myObj)
deepObj1.a.a1 = 999
deepObj1.b = false
console.log(myObj);
// 简易版存在的问题:参数没有做检验,传入的可能是 Array、null、regExp、Date
function deepClone2(o) {
if (Object.prototype.toString.call(o) === "[object Object]") { //检测是否为对象
let obj = {}
for (var i in o) {
if (o.hasOwnProperty(i)) {
if (typeof o[i] === "object") {
obj[i] = deepClone2(o[i])
} else {
obj[i] = o[i]
}
}
}
return obj
} else {
return o
}
}
function isObject(o) {
return Object.prototype.toString.call(o) === "[object Object]" || Object.prototype.toString.call(o) === "[object Array]"
}
// 继续升级,没有考虑到数组,以及ES6中的map、set、weakset、weakmap
function deepClone3(o) {
if (isObject(o)) {//检测是否为对象或者数组
let obj = Array.isArray(o) ? [] : {}
for (let i in o) {
if (isObject(o[i])) {
obj[i] = deepClone3(o[i])
} else {
obj[i] = o[i]
}
}
return obj
} else {
return o
}
}
// 有可能碰到循环引用问题 var a = {}; a.a = a; clone(a);//会造成一个死循环
// 循环检测
// 继续升级
function deepClone4(o, hash = new map()) {
if (!isObject(o)) return o//检测是否为对象或者数组
if (hash.has(o)) return hash.get(o)
let obj = Array.isArray(o) ? [] : {}
hash.set(o, obj)
for (let i in o) {
if (isObject(o[i])) {
obj[i] = deepClone4(o[i], hash)
} else {
obj[i] = o[i]
}
}
return obj
}
// 递归易出现爆栈问题
// 将递归改为循环,就不会出现爆栈问题了
var a1 = { a: 1, b: 2, c: { c1: 3, c2: { c21: 4, c22: 5 } }, d: 'asd' };
var b1 = { b: { c: { d: 1 } } }
function cloneLoop(x) {
const root = {};
// 栈
const loopList = [ //->[]->[{parent:{a:1,b:2},key:c,data:{ c1: 3, c2: { c21: 4, c22: 5 } }}]
{
parent: root,
key: undefined,
data: x,
}
];
while (loopList.length) {
// 深度优先
const node = loopList.pop();
const parent = node.parent; //{} //{a:1,b:2}
const key = node.key; //undefined //c
const data = node.data; //{ a: 1, b: 2, c: { c1: 3, c2: { c21: 4, c22: 5 } }, d: 'asd' } //{ c1: 3, c2: { c21: 4, c22: 5 } }}
// 初始化赋值目标,key 为 undefined 则拷贝到父元素,否则拷贝到子元素
let res = parent; //{}->{a:1,b:2,d:'asd'} //{a:1,b:2}->{}
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
for (let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === 'object') {
// 下一次循环
loopList.push({
parent: res,
key: k,
data: data[k],
})
} else {
res[k] = data[k];
}
}
}
}
return root
}
function deepClone5(o) {
let result = {}
let loopList = [
{
parent: result,
key: undefined,
data: o
}
]
while (loopList.length) {
let node = loopList.pop()
let { parent, key, data } = node
let anoPar = parent
if (typeof key !== 'undefined') {
anoPar = parent[key] = {}
}
for (let i in data) {
if (typeof data[i] === 'object') {
loopList.push({
parent: anoPar,
key: i,
data: data[i]
})
} else {
anoPar[i] = data[i]
}
}
}
return result
}
let cloneA1 = deepClone5(a1)
cloneA1.c.c2.c22 = 5555555
console.log(a1);
console.log(cloneA1);
// ------------------------------------------JSON.stringify()实现深拷贝
function cloneJson(o) {
return JSON.parse(JSON.stringify(o))
}
// let obj = { a: { c: 1 }, b: {} };
// obj.b = obj;
// console.log(JSON.parse(JSON.stringify(obj)))
// 报错
// Converting circular structure to JSON
// ------------------------------------------lodash库实现深拷贝
lodash.cloneDeep(obj)
// ------------------------------------------JQ中的extend实现深拷贝
var array = [1,2,3,4];
var newArray = $.extend(true,[],array);
深拷贝能使用hash递归的方式写出来就可以了
不过技多不压身,推荐还是看一看使用while实现深拷贝方法
单线程,同步异步
面 试 官 : 为 什 么 J S 是 单 线 程 的 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:为什么JS是单线程的?⭐⭐⭐⭐⭐} 面试官:为什么JS是单线程的?⭐⭐⭐⭐⭐
因为JS里面有可视的Dom,如果是多线程的话,这个线程正在删除DOM节点,另一个线程正在编辑Dom节点,导致浏览器不知道该听谁的
面 试 官 : 如 何 实 现 异 步 编 程 ? \color{#0000FF}{面试官:如何实现异步编程?} 面试官:如何实现异步编程?
回调函数
面 试 官 : G e n e r a t o r 是 怎 么 样 使 用 的 以 及 各 个 阶 段 的 变 化 如 何 ? ⭐ ⭐ ⭐ \color{#0000FF}{面试官:Generator是怎么样使用的以及各个阶段的变化如何?⭐⭐⭐} 面试官:Generator是怎么样使用的以及各个阶段的变化如何?⭐⭐⭐
- 首先生成器是一个函数,用来返回迭代器的
- 调用生成器后不会立即执行,而是通过返回的迭代器来控制这个生成器的一步一步执行的
- 通过调用迭代器的next方法来请求一个一个的值,返回的对象有两个属性,一个是value,也就是值;另一个是done,是个布尔类型,done为true说明生成器函数执行完毕,没有可返回的值了,
- done为true后继续调用迭代器的next方法,返回值的value为undefined
状态变化:
- 每当执行到yield属性的时候,都会返回一个对象
- 这时候生成器处于一个非阻塞的挂起状态
- 调用迭代器的next方法的时候,生成器又从挂起状态改为执行状态,继续上一次的执行位置执行 直到遇到下一次yield依次循环
- 直到代码没有yield了,就会返回一个结果对象done为true,value为undefined
promise
面 试 官 : 说 说 P r o m i s e 的 原 理 ? 你 是 如 何 理 解 P r o m i s e 的 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:说说 Promise 的原理?你是如何理解 Promise 的?⭐⭐⭐⭐⭐} 面试官:说说Promise的原理?你是如何理解Promise的?⭐⭐⭐⭐⭐
Promise 是异步编程的一种解决方案。promise的核心原理其实就是发布订阅模式,通过两个队列来缓存成功的回调(onResolve)和失败的回调(onReject。所谓Promise,简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。从语法上说,Promise 是一个对象,从它可以获取异步操作的消息。Promise 提供统一的 API,各种异步操作都可以用同样的方法进行处理。
// 极简版promise
function MyPromise(fn) {
let value = '';
let callbacks = [];
this.then = function(onFulfilled) {
callbacks.push(onFulfilled);
}
function reslove(value) {
callbacks.forEach(callback => {
callback(value)
})
}
fn(reslove)
}
class Promise{
constructor(executor) {
// 状态
this.state = 'pending';
// reslove的值
this.value = null;
// rejected的值
this.reason = null;
// reslove 函数数组
this.successCB = [];
// reject 函数数组
this.failCB = [];
let reslove = value => {
if (this.state === 'pending') {
this.state = 'fulfilled';
this.value = value;
this.successCB.forEach(fn => fn())
}
}
let reject = reason => {
if (this.state === 'pending') {
this.state = 'rejected';
this.reason = reason;
this.failCB.forEach(fn => fn())
}
}
try {
// 执行reslove reject
executor(reslove, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
if (this.state == 'fulfilled') {
onFulfilled(this.value);
}
if (this.state == 'rejected') {
onRejected(this.reason);
}
if (this.state == 'pending') {
this.successCB.push(() => {
onFulfilled(this.value);
})
this.onFulfilled.push(() => {
onRejected(this.reason);
})
}
}
}
Promise.all = function (promises) {
let list = []
let count = 0
function handle(i, data) {
list[i] = data
count++
if (count == promises.length) {
resolve(list)
}
}
return Promise((resolve, reject) => {
for (let i = 0; i < promises.length; i++) {
promises[i].then(res => {
handle(i, res)
}, err => reject(err))
}
})
}
面 试 官 : p r o m i s e 的 状 态 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:promise的状态⭐⭐⭐⭐} 面试官:promise的状态⭐⭐⭐⭐
- pending:初始状态,既不是成功,也不是失败状态
- reslove:操作成功
- reject:操作失败
面 试 官 : p r o m i s e 的 常 用 方 法 ⭐ ⭐ ⭐ \color{#0000FF}{面试官:promise的常用方法⭐⭐⭐} 面试官:promise的常用方法⭐⭐⭐
- then方法:then方法返回的是一个新的promise实例。注意:如果采用链式的then,可以指定一组按照次序调用的回调函数,如果前一个回调函数返回的是promise,后一个函数会等前一个状态发生改变才会调用。
- catch方法:catch方法是在promise发生错误时的回调。注意:如果promise状态已经变成resolved,在抛出错误时无效的。promise错误具有‘冒泡’性质,会一直往上传递,直到被捕获。
- finally方法:finally方法指定无伦最后promise最后状态如何都会执行的函数。注意:finally不接受任何参数,这就意味着无法知道前面的promise状态。
- all方法:all方法用于将多个实例包装成一个新的promise实例。注意:只有当所有的实例都变成fulfilled时,包装的实例状态,才会变成fulfilled,此时他们的返回值会传递给新的回调函数,只要其中有一个被rejected,包装的实例状态就会变成rejected,此时第一个被rejected的实例返回值会传递给新的回调。
- race方法:race方法同样是将多个实例包装成一个新的实例。跟上面的all方法类似。与Promise.all不同的是,多个Promise实例,只要有一个率先改变,race方法就跟着改变,并返回那个率先改变的Promise实例的返回值,传递给回调函数。
- allSettled方法:allSettled方法接收一组promise实例作为参数,包装成一个新的实例。注意:只有等所有的实例都返回结果,才会结束。返回的结果不论成功失败,状态总是fulfilled,不会是失败。
- any方法:接收一组promise实例作为参数,只要有一个变为fulfilled状态,包装的实例就会变成fulfilled状态,如果所有的参数都变成rejected状态,就会变成rejected状态。
- reject方法:reject方法会返回一个新的实例,状态为rejected。回调函数立即执行。
- try方法:在实际开发中遇到无法区分函数是同步还是异步操作时,但是还想用promise来处理,可以使用try方法。
- resolve方法:将现有对象转为promise对象
面 试 官 : 以 下 代 码 的 执 行 顺 序 是 什 么 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:以下代码的执行顺序是什么⭐⭐⭐⭐⭐} 面试官:以下代码的执行顺序是什么⭐⭐⭐⭐⭐
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
async1()
console.log('script start')
//执行到await时,如果返回的不是一个promise对象,await会阻塞下面代码(当前async代码块的代码),会先执行async外的同步代码(在这之前先看看await中函数的同步代码,先把同步代码执行完),等待同步代码执行完之后,再回到async内部继续执行
//执行到await时,如果返回的是一个promise对象,await会阻塞下面代码(当前async代码块的代码),会先执行async外的同步代码(在这之前先看看await中函数的同步代码,先把同步代码执行完),等待同步代码执行完之后,再回到async内部等promise状态达到fulfill的时候再继续执行下面的代码
//所以结果为
//async1 start
//async2
//script start
//async1 end
面 试 官 : 宏 任 务 和 微 任 务 都 有 哪 些 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:宏任务和微任务都有哪些⭐⭐⭐⭐⭐} 面试官:宏任务和微任务都有哪些⭐⭐⭐⭐⭐
宏任务:script、setTimeOut、setInterval、setImmediate
微任务:promise.then,process.nextTick、Object.observe、MutationObserver
注意:Promise是同步任务
面 试 官 : 宏 任 务 和 微 任 务 都 是 怎 样 执 行 的 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:宏任务和微任务都是怎样执行的⭐⭐⭐⭐⭐} 面试官:宏任务和微任务都是怎样执行的⭐⭐⭐⭐⭐
执行宏任务script,
进入script后,所有的同步任务主线程执行
所有宏任务放入宏任务执行队列
所有微任务放入微任务执行队列
先清空微任务队列,
再取一个宏任务,执行,再清空微任务队列
依次循环
//例题1
setTimeout(function(){
console.log('1')
});
new Promise(function(resolve){
console.log('2');
resolve();
}).then(function(){
console.log('3')
});
console.log('4');
new Promise(function(resolve){
console.log('5');
resolve();
}).then(function(){
console.log('6')
});
setTimeout(function(){
console.log('7')
});
function bar(){
console.log('8')
foo()
}
function foo(){
console.log('9')
}
console.log('10')
bar()
解析
- 首先浏览器执行Js代码由上至下顺序,遇到setTimeout,把setTimeout分发到宏任务Event Queue中
new Promise属于主线程任务直接执行打印2 - Promis下的then方法属于微任务,把then分到微任务 Event Queue中console.log(‘4’)属于主线程任务,直接执行打印4
- 又遇到new Promise也是直接执行打印5,Promise 下到then分发到微任务Event Queue中
- 又遇到setTimouse也是直接分发到宏任务Event Queue中,等待执行console.log(‘10’)属于主线程任务直接执行
- 遇到bar()函数调用,执行构造函数内到代码,打印8,在bar函数中调用foo函数,执行foo函数到中代码,打印9
- 主线程中任务执行完后,就要执行分发到微任务Event Queue中代码,实行先进先出,所以依次打印3,6
- 微任务Event Queue中代码执行完,就执行宏任务Event Queue中代码,也是先进先出,依次打印1,7。
最终结果:2,4,5,10,8,9,3,6,1,7
例题2
setTimeout(() => {
console.log('1');
new Promise(function (resolve, reject) {
console.log('2');
setTimeout(() => {
console.log('3');
}, 0);
resolve();
}).then(function () {
console.log('4')
})
}, 0);
console.log('5'); //5 7 10 8 1 2 4 6 3
setTimeout(() => {
console.log('6');
}, 0);
new Promise(function (resolve, reject) {
console.log('7');
// reject();
resolve();
}).then(function () {
console.log('8')
}).catch(function () {
console.log('9')
})
console.log('10');
运行结果: 5 7 10 8 1 2 4 6 3
变量提升
面 试 官 : 变 量 和 函 数 怎 么 进 行 提 升 的 ? 优 先 级 是 怎 么 样 的 ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:变量和函数怎么进行提升的?优先级是怎么样的?⭐⭐⭐⭐} 面试官:变量和函数怎么进行提升的?优先级是怎么样的?⭐⭐⭐⭐
ps: 只有函数声明形式才有函数提升
对所有函数声明进行提升(除了函数表达式和箭头函数),引用类型的赋值
开辟堆空间
存储内容
将地址赋给变量
对变量进行提升,只声明,不赋值,值为undefined
面 试 官 : v a r 、 l e t 、 c o n s t 有 什 么 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:var、let、 const 有什么区别⭐⭐⭐⭐⭐} 面试官:var、let、const有什么区别⭐⭐⭐⭐⭐
-
var
var声明的变量可进行变量提升,let和const不会
var可以重复声明
var在非函数作用域中定义是挂在到window上的 -
let
let声明的变量只在局部起作用
let防止变量污染
不可在声明 -
const
具有let的所有特征
不可被改变
如果使用const声明的是对象的话,是可以修改对象里面的值的
面 试 官 : 箭 头 函 数 和 普 通 函 数 的 区 别 ? 箭 头 函 数 可 以 当 做 构 造 函 数 n e w 吗 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:箭头函数和普通函数的区别?箭头函数可以当做构造函数 new 吗?⭐⭐⭐⭐⭐} 面试官:箭头函数和普通函数的区别?箭头函数可以当做构造函数new吗?⭐⭐⭐⭐⭐
箭头函数是普通函数的简写,但是它不具备很多普通函数的特性
- 第一点,this指向问题,箭头函数的this指向它定义时所在的对象,而不是调用时所在的对象 不会进行函数提升
- 没有arguments对象,不能使用arguments,如果要获取参数的话可以使用rest运算符
- 没有yield属性,不能作为生成器Generator使用
- 不能new
- 没有自己的this,不能调用call和apply
- 没有prototype,new关键字内部需要把新对象的_proto_指向函数的prototype
面 试 官 : 说 说 你 对 代 理 的 理 解 ⭐ ⭐ ⭐ \color{#0000FF}{面试官:说说你对代理的理解⭐⭐⭐} 面试官:说说你对代理的理解⭐⭐⭐
代理有几种定义方式
- 字面量定义,对象里面的 get和set
- 类定义, class 中的get和set
- Proxy对象,里面传两个对象,第一个对象是目标对象target,第二个对象是专门放get和set的handler对象。Proxy和上面两个的区别在于Proxy专门对对象的属性进行get和set
代理的实际应用有
- Vue的双向绑定 vue2用的是Object.defineProperty,vue3用的是proxy
- 校验值
- 计算属性值(get的时候加以修饰)
面 试 官 : 为 什 么 要 使 用 模 块 化 ? 都 有 哪 几 种 方 式 可 以 实 现 模 块 化 , 各 有 什 么 特 点 ? ⭐ ⭐ ⭐ \color{#0000FF}{面试官:为什么要使用模块化?都有哪几种方式可以实现模块化,各有什么特点?⭐⭐⭐} 面试官:为什么要使用模块化?都有哪几种方式可以实现模块化,各有什么特点?⭐⭐⭐
- 为什么要使用模块化
- 防止命名冲突
- 更好的分离,按需加载
- 更好的复用性
- 更高的维护性
- 模块化的方式
- CommonJS:主要用于服务端编程,加载模块是同步的,这并不适合在浏览器环境,因为同步意味着阻塞加载,浏览器资源是异步加载的,因此有了AMD CMD解决方案
- AMD:在浏览器环境中异步加载模块,而且可以并行加载多个模块。不过,AMD规范开发成本高,代码的阅读和书写比较困难,模块定义方式的语义不顺畅。
- CMD:CMD规范与AMD规范很相似,都用于浏览器编程,依赖就近,延迟执行,可以很容易在Node.js中运行。不过,依赖SPM 打包,模块的加载逻辑偏重
- ES6模块化:在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代 CommonJS 和 AMD 规范,成为浏览器和服务器通用的模块解决方案。
面 试 官 : e x p o r t s 和 m o d u l e . e x p o r t 有 什 么 区 别 ? ⭐ ⭐ ⭐ \color{#0000FF}{面试官:exports和module.export有什么区别?⭐⭐⭐} 面试官:exports和module.export有什么区别?⭐⭐⭐
- 导出方式不一样
- exports.xxx=‘xxx’
- module.exports = {}
- exports是module.export的引用,两个指向的是用一个地址,而require能看到的只有module.export
面 试 官 : J S 模 块 包 装 格 式 有 哪 些 ? ⭐ ⭐ ⭐ \color{#0000FF}{面试官:JS模块包装格式有哪些?⭐⭐⭐} 面试官:JS模块包装格式有哪些?⭐⭐⭐
-
commonjs
同步运行,不适合前端
-
AMD
异步运行
异步模块定义,主要采用异步的方式加载模块,模块的加载不影响后面代码的执行。所有依赖这个模块的语句都写在一个回调函数中,模块加载完毕,再执行回调函数 -
CMD
异步运行
seajs 规范
面 试 官 : E S 6 和 c o m m o n j s 的 区 别 ⭐ ⭐ ⭐ \color{#0000FF}{面试官:ES6和commonjs的区别⭐⭐⭐} 面试官:ES6和commonjs的区别⭐⭐⭐
- commonjs模块输出的是值的拷贝,而ES6输出的值是值的引用
- commonjs是在运行时加载,是一个对象,ES6是在编译时加载,是一个代码块
- commonjs的this指向当前模块,ES6的this指向undefined
跨域
面 试 官 : 跨 域 的 方 式 都 有 哪 些 ? 他 们 的 特 点 是 什 么 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:跨域的方式都有哪些?他们的特点是什么 ⭐⭐⭐⭐⭐} 面试官:跨域的方式都有哪些?他们的特点是什么⭐⭐⭐⭐⭐
-
JSONP⭐⭐⭐⭐⭐
JSONP通过同源策略涉及不到的"漏洞",也就是像img中的src,link标签的href,script的src都没有被同源策略限制到
JSONP只能get请求
源码:
function addScriptTag(src) {
var script = document.createElement("script")
script.setAttribute('type','text/javascript')
script.src = src
document.appendChild(script)
}
// 回调函数
function endFn(res) {
console.log(res.message);
}
// 前后端商量好,后端如果传数据的话,返回`endFn({message:'hello'})`
-
document.domain⭐
只能跨一级域名相同的域(www.qq.om和www.id.qq.com , 二者都有qq.com)
使用方法
表示输入, <表示输出 ,以下是在www.id.qq.com网站下执行的操作
var w = window.open(“https://www.qq.com”)
< undefined
w.document
✖ VM3061:1 Uncaught DOMException: Blocked a frame with origin “https://id.qq.com” from accessing a cross-origin frame.
at :1:3
document.domain
< “id.qq.com”
document.domain = ‘qq.com’
< “qq.com”
w.document
< #document -
location.hash+iframe⭐⭐
因为hash传值只能单向传输,所有可以通过一个中间网页,a若想与b进行通信,可以通过一个与a同源的c作为中间网页,a传给b,b传给c,c再传回a
具体做法:在a中放一个回调函数,方便c回调。放一个iframe标签,随后传值
<iframe id="iframe" src="http://www.domain2.com/b.html" style="display:none;"></iframe>
<script>
var iframe = document.getElementById('iframe');
// 向b.html传hash值
setTimeout(function() {
iframe.src = iframe.src + '#user=admin';
}, 1000);
// 开放给同域c.html的回调方法
function onCallback(res) {
alert('data from c.html ---> ' + res);
}
</script>
在b中监听哈希值改变,一旦改变,把a要接收的值传给c
<iframe id="iframe" src="http://www.domain1.com/c.html" style="display:none;"></iframe>
<script>
var iframe = document.getElementById('iframe');
// 监听a.html传来的hash值,再传给c.html
window.onhashchange = function () {
iframe.src = iframe.src + location.hash;
};
</script>
在c中监听哈希值改变,一旦改变,调用a中的回调函数
<script>
// 监听b.html传来的hash值
window.onhashchange = function () {
// 再通过操作同域a.html的js回调,将结果传回
window.parent.parent.onCallback('hello: ' + location.hash.replace('#user=', ''));
};
</script>
-
window.name+iframe⭐⭐
利Access用window.name不会改变(而且很大)来获取数据,a要获取b的数据,b中把数据转为json格式放到window.name中
-
postMessage⭐
a窗口向b窗口发送数据,先把data转为json格式,在发送。提前设置好messge监听b窗口进行message监听,监听到了以同样的方式返回数据,a窗口监听到message,在进行一系列操作
-
CORS⭐⭐⭐⭐⭐
通过自定义请求头来让服务器和浏览器进行沟通
有简单请求和非简单请求- 满足以下条件,就是简单请求
- 请求方法是HEAD、POST、GET
- 请求头只有Accept、AcceptLanguage、ContentType、ContentLanguage、Last-Event-Id
简单请求,浏览器自动添加一个Origin字段 - 同时后端需要设置的请求头
- Access-Control-Allow-Origin --必须
- Access-Control-Expose-Headers
- XMLHttpRequest只能拿到六个字段,要想拿到其他的需要在这里指定
- Access-Control-Allow-Credentials --是否可传cookie
- 要是想传cookie,前端需要设置xhr.withCredentials =true,后端设置Access-Control-Allow-Credentials
- 非简单请求,浏览器判断是否为简单请求,如果是非简单请求,则 浏览器先发送一个header头为option的请求进行预检
- 预检请求格式(请求行 的请求方法为OPTIONS(专门用来询问的))
- Origin
- Access-Control-Request-Method
- Access-Control-Request-Header
- 浏览器检查了Origin、Access-Control-Allow-Method和Access-Control-Request-Header之后确认允许就可以做出回应了
- 通过预检后,浏览器接下来的每次请求就类似于简单请求了
- 满足以下条件,就是简单请求
-
nginx代理跨域⭐⭐⭐⭐
- nginx模拟一个虚拟服务器,因为服务器与服务器之间是不存在跨域的,
- 发送数据时 ,客户端->nginx->服务端
- 返回数据时,服务端->nginx->客户端
网络原理
面 试 官 : 讲 一 讲 三 次 握 手 四 次 挥 手 , 为 什 么 是 三 次 握 手 而 不 是 两 次 握 手 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:讲一讲三次握手四次挥手,为什么是三次握手而不是两次握手?⭐⭐⭐⭐⭐} 面试官:讲一讲三次握手四次挥手,为什么是三次握手而不是两次握手?⭐⭐⭐⭐⭐
- 客户端和服务端之间通过三次握手建立连接,四次挥手释放连接
- 三次握手,客户端先向服务端发起一个SYN包,进入SYN_SENT状态,服务端收到SYN后,给客户端返回一个ACK+SYN包,表示已收到SYN,并进入SYN_RECEIVE状态,最后客户端再向服务端发送一个ACK包表示确认,双方进入establish状态。
- 之所以是三次握手而不是两次,是因为如果只有两次,在服务端收到SYN后,向客户端返回一个ACK确认就进入establish状态,万一这个请求中间遇到网络情况而没有传给客户端,客户端一直是等待状态,后面服务端发送的信息客户端也接受不到了。
- 四次挥手,首先客户端向服务端发送一个FIN包,进入FIN_WAIT1状态,服务端收到后,向客户端发送ACK确认包,进入CLOSE_WAIT状态,然后客户端收到ACK包后进入FIN_WAIT2状态,然后服务端再把自己剩余没传完的数据发送给客户端,发送完毕后在发送一个FIN+ACK包,进入LAST_ACK(最后确认)状态,客户端收到FIN+ACK包后,再向服务端发送ACK包,在等待两个周期后在关闭连接
- 之所以等待两个周期是因为最后服务端发送的ACK包可能会丢失,如果不等待2个周期的话,服务端在没收收到ACK包之前,会不停的重复发送FIN包而不关闭,所以得等待两个周期
面 试 官 : H T T P 的 结 构 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:HTTP的结构⭐⭐⭐⭐} 面试官:HTTP的结构⭐⭐⭐⭐
- 请求行 请求头 空行 请求体
- 请求行包括 http版本号,url,请求方式
- 响应行包括版本号,状态码,原因
H T T P 头 都 有 哪 些 字 段 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{HTTP头都有哪些字段⭐⭐⭐⭐} HTTP头都有哪些字段⭐⭐⭐⭐
- 请求头
- cache-control 是否使用缓存
- Connection:keep-alive 与服务器的连接状态
- Host 主机域
- 返回头
- cache-control
- etag 唯一标识,缓存用的
- last-modified最后修改时间
面 试 官 : 说 说 你 知 道 的 状 态 码 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:说说你知道的状态码⭐⭐⭐⭐⭐} 面试官:说说你知道的状态码⭐⭐⭐⭐⭐
- 2开头的表示成功
- 一般见到的就是200
- 3开头的表示重定向
- 301永久重定向
- 302临时重定向
- 304表示可以在缓存中取数据(协商缓存)
- 4开头表示客户端错误
- 403跨域
- 404请求资源不存在
- 5开头表示服务端错误
- 500
网 络 O S I 七 层 模 型 都 有 哪 些 ? T C P 是 哪 一 层 的 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{网络OSI七层模型都有哪些?TCP是哪一层的⭐⭐⭐⭐} 网络OSI七层模型都有哪些?TCP是哪一层的⭐⭐⭐⭐
- 七层模型
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
TCP属于传输层
面 试 官 : h t t p 1.0 和 h t t p 1.1 , 还 有 h t t p 2 有 什 么 区 别 ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:http1.0和http1.1,还有http2有什么区别?⭐⭐⭐⭐} 面试官:http1.0和http1.1,还有http2有什么区别?⭐⭐⭐⭐
- http0.9只能进行get请求
- http1.0添加了POST,HEAD,OPTION,PUT,DELETE等
- http1.1增加了长连接keep-alive,增加了host域,而且节约带宽
- http2 多路复用,头部压缩,服务器推送
面 试 官 : h t t p s 和 h t t p 有 什 么 区 别 , h t t p s 的 实 现 原 理 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:https和http有什么区别,https的实现原理?⭐⭐⭐⭐⭐} 面试官:https和http有什么区别,https的实现原理?⭐⭐⭐⭐⭐
- http无状态无连接,而且是明文传输,不安全
- https传输内容加密,身份验证,保证数据完整性
h t t p s 实 现 原 理 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{https实现原理⭐⭐⭐⭐⭐} https实现原理⭐⭐⭐⭐⭐
- 首先客户端向服务端发起一个随机值,以及一个加密算法
- 服务端收到后返回一个协商好的加密算法,以及另一个随机值
- 服务端在发送一个公钥CA
- 客户端收到以后先验证CA是否有效,如果无效则报错弹窗,有过有效则进行下一步操作
- 客户端使用之前的两个随机值和一个预主密钥组成一个会话密钥,在通过服务端传来的公钥加密把会话密钥发送给服务端
- 服务端收到后使用私钥解密,得到两个随机值和预主密钥,然后组装成会话密钥
- 客户端在向服务端发起一条信息,这条信息使用会话秘钥加密,用来验证服务端时候能收到加密的信息
- 服务端收到信息后返回一个会话秘钥加密的信息
- 都收到以后SSL层连接建立成功
面 试 官 : l o c a l S t o r a g e 、 S e s s i o n S t o r a g e 、 c o o k i e 、 s e s s i o n 之 间 有 什 么 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:localStorage、SessionStorage、cookie、session 之间有什么区别⭐⭐⭐⭐⭐} 面试官:localStorage、SessionStorage、cookie、session之间有什么区别⭐⭐⭐⭐⭐
- localStorage
- 生命周期:关闭浏览器后数据依然保留,除非手动清除,否则一直在
- 作用域:相同浏览器的不同标签在同源情况下可以共享localStorage
- sessionStorage
- 生命周期:关闭浏览器或者标签后即失效
- 作用域:只在当前标签可用,当前标签的iframe中且同源可以共享
- cookie
- 是保存在客户端的,一般由后端设置值,可以设置过期时间
- 储存大小只有4K
- 一般用来保存用户的信息的
- 在http下cookie是明文传输的,较不安全
- cookie属性有
- http-only:不能被客户端更改访问,防止XSS攻击(保证cookie安全性的操作)
- Secure:只允许在https下传输
- Max-age: cookie生成后失效的秒数
- expire: cookie的最长有效时间,若不设置则cookie生命期与会话期相同
- session
- session是保存在服务端的
- session的运行依赖sessionId,而sessionId又保存在cookie中,所以如果禁用的cookie,session也是不能用的,不过硬要用也可以,可以把sessionId保存在URL中
- session一般用来跟踪用户的状态
- session 的安全性更高,保存在服务端,不过一般为使服务端性能更加,会考虑部分信息保存在cookie中
l o c a l s t o r a g e 存 满 了 怎 么 办 ? ⭐ ⭐ ⭐ \color{#0000FF}{localstorage存满了怎么办?⭐⭐⭐} localstorage存满了怎么办?⭐⭐⭐
- 划分域名,各域名下的存储空间由各业务组统一规划使用
- 跨页面传数据:考虑单页应用、采用url传输数据
- 最后兜底方案:清除别人的存储
怎 么 使 用 c o o k i e 保 存 用 户 信 息 ⭐ ⭐ ⭐ \color{#0000FF}{怎么使用cookie保存用户信息⭐⭐⭐} 怎么使用cookie保存用户信息⭐⭐⭐
- document.cookie(“名字 = 数据;expire=时间”)
怎 么 删 除 c o o k i e ⭐ ⭐ ⭐ \color{#0000FF}{怎么删除cookie⭐⭐⭐} 怎么删除cookie⭐⭐⭐
- 目前没有提供删除的操作,但是可以把它的Max-age设置为0,也就是立马失效,也就是删除了
面 试 官 : G e t 和 P o s t 的 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:Get和Post的区别⭐⭐⭐⭐⭐} 面试官:Get和Post的区别⭐⭐⭐⭐⭐
- 冪等/不冪等(可缓存/不可缓存)
- get请求是冪等的,所以get请求的数据是可以缓存的
- 而post请求是不冪等的,查询查询对数据是有副作用的,是不可缓存的
- 传参
- get传参,参数是在url中的
- 准确的说get传参也可以放到body中,只不过不推荐使用
- post传参,参数是在请求体中
- 准确的说post传参也可以放到url中,只不过不推荐使用
- 安全性
- get较不安全
- post较为安全
- 准确的说两者都不安全,都是明文传输的,在路过公网的时候都会被访问到,不管是url还是header还是body,都会被访问到,要想做到安全,就需要使用https
- 参数长度
- get参数长度有限,是较小的
- 准确来说,get在url传参的时候是很小的
- post传参长度不受限制
- 发送数据
- post传参发送两个请求包,一个是请求头,一个是请求体,请求头发送后服务器进行验证,要是验证通过的话就会给客户端发送一个100-continue的状态码,然后就会发送请求体
- 字符编码
- get在url上传输的时候只允许ASCII编码
面 试 官 : 讲 讲 h t t p 缓 存 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:讲讲http缓存⭐⭐⭐⭐⭐} 面试官:讲讲http缓存⭐⭐⭐⭐⭐
- 缓存分为强缓存和协商缓存
- 强缓存
- 在浏览器加载资源时,先看看cache-control里的max-age,判断数据有没有过期,如果没有直接使用该缓存
,有些用户可能会在没有过期的时候就点了刷新按钮,这个时候浏览器就回去请求服务端,要想避免这样做,可以在cache-control里面加一个immutable. - public
- 允许客户端和虚拟服务器缓存该资源,cache-control中的一个属性
- private
- 只允许客户端缓存该资源
- no-cache
- 不允许强缓存,可以协商缓存
- no-store
- 不允许缓存
- 在浏览器加载资源时,先看看cache-control里的max-age,判断数据有没有过期,如果没有直接使用该缓存
- 协商缓存
- 浏览器加载资源时,没有命中强缓存,这时候就去请求服务器,去请求服务器的时候,会带着两个参数,一个是If-None-Match,也就是响应头中的etag属性,每个文件对应一个etag;另一个参数是If-Modified-Since,也就是响应头中的Last-Modified属性,带着这两个参数去检验缓存是否真的过期,如果没有过期,则服务器会给浏览器返回一个304状态码,表示缓存没有过期,可以使用旧缓存。
- etag的作用
- 有时候编辑了文件,但是没有修改,但是last-modified属性的时间就会改变,导致服务器会重新发送资源,但是etag的出现就完美的避免了这个问题,他是文件的唯一标识
- 缓存位置:
- 内存缓存Memory-Cache
- 离线缓存Service-Worker
- 磁盘缓存Disk-Cache
- 推送缓存Push-Cache
- 强缓存
面 试 官 : t c p 和 u d p 有 什 么 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:tcp 和udp有什么区别⭐⭐⭐⭐⭐} 面试官:tcp和udp有什么区别⭐⭐⭐⭐⭐
- 连接方面
- tcp面向连接,udp不需要连接
- tcp需要三次握手四次挥手请求连接 - 可靠性
- tcp是可靠传输;一旦传输过程中丢包的话会进行重传
- udp是不可靠传输,但会最大努力交付 - 工作效率
- UDP实时性高,比TCP工作效率高
- 因为不需要建立连接,更不需要复杂的握手挥手以及复杂的算法,也没有重传机制 - 是否支持多对多
- TCP是点对点的
- UDP支持一对一,一对多,多对多 - 首部大小
- tcp首部占20字节
- udp首部占8字节
面 试 官 : 从 浏 览 器 输 入 u r l 后 都 经 历 了 什 么 ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ ⭐ 具 重 要 ! \color{#0000FF}{面试官:从浏览器输入url后都经历了什么⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐具重要!} 面试官:从浏览器输入url后都经历了什么⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐具重要!
- 先进行DNS域名解析,先查看本地hosts文件,查看有没有当前域名对应的ip地址,若有直接发起请求,没有的话会在本地域名服务器去查找,该查找属于递归查找,如果本地域名服务器没查找到,会从根域名服务器查找,该过程属于迭代查找,根域名会告诉你从哪个与服务器查找,最后查找到对应的ip地址后把对应规则保存到本地的hosts文件中。
- 如果想加速以上及之后的http请求过程的话可以使用缓存服务器CDN,CDN过程如下:
- 用户输入url地址后,本地DNS会解析url地址,不过会把最终解析权交给CNAME指向的CDN的DNS服务器
- CDN的DNS服务器会返回给浏览器一个全局负载均衡IP
- 用户会根据全局负载均衡IP去请求全局负载均衡服务器
- 全局负载均衡服务器会根据用户的IP地址,url地址,会告诉用户一个区域负载均衡设备,让用户去请求它。
- 区域负载均衡服务器会为用户选择一个离用户较近的最优的缓存服务器,并把ip地址给到用户
- 用户想缓存服务器发送请求,如果请求不到想要的资源的话,会一层层向上一级查找,知道查找到为止。
- 进行http请求,三次握手四次挥手建立断开连接
- 服务器处理,可能返回304也可能返回200
- 返回304说明客户端缓存可用,直接使用客户端缓存即可,该过程属于协商缓存
- 返回200的话会同时返回对应的数据
- 客户端自上而下执行代码
- 其中遇到CSS加载的时候,CSS不会阻塞DOM树的解析,但是会阻塞DOM树的渲染,并且CSS会阻塞下面的JS的执行
- 然后是JS加载,JS加载会影响DOM的解析,之所以会影响,是因为JS可能会删除添加节点,如果先解析后加载的话,DOM树还得重新解析,性能比较差。如果不想阻塞DOM树的解析的话,可以给script添加一个defer或者async的标签。
- defer:不会阻塞DOM解析,等DOM解析完之后在运行,在DOMContentloaed之前
- async: 不会阻塞DOM解析,等该资源下载完成之后立刻运行
- 进行DOM渲染和Render树渲染
- 获取html并解析为Dom树
- 解析css并形成一个cssom(css树)
- 将cssom和dom合并成渲染树(render树)
- 进行布局(layout)
- 进行绘制(painting)
- 回流重绘
ps:回流必将引起重绘,重绘不一定引起回流
滑 动 窗 口 和 拥 塞 窗 口 有 什 么 区 别 ⭐ ⭐ ⭐ \color{#0000FF}{滑动窗口和拥塞窗口有什么区别⭐⭐⭐} 滑动窗口和拥塞窗口有什么区别⭐⭐⭐
- 解析TCP之滑动窗口(动画演示)
- 以动画的形式解释滑动窗口,
- 滑动窗口
- 发送窗口永远小于或等于接收窗口,发送窗口的大小取决于接收窗口的大小
- 控制流量来保证TCP的可靠传输(不控制流量的话可能会溢出)
- 发送方的数据分为
- 1已发送,接收到ACK的
- 2已发送,未接收到ACK的
- 3未发送,但允许发送的
- 4未发送,但不允许发送的
- 2和3表示发送窗口
- 接收方
- 1.已接收
- 2.未接受但准备接受
- 3.未接受不准备接受
- 拥塞窗口
- 防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。
- 是一个全局性的过程
- 方法
- 慢开始、拥塞避免、快重传、快恢复
什 么 是 C D N ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{什么是CDN?⭐⭐⭐⭐} 什么是CDN?⭐⭐⭐⭐
- 1.首先访问本地的 DNS ,如果没有命中,继续递归或者迭代查找,直到命中拿到对应的 IP 地址。
- 2.拿到对应的 IP 地址之后服务器端发送请求到目的地址。注意这里返回的不直接是 cdn 服务器的 IP 地址,而是全局负载均衡系统的 IP 地址
- 4.全局负载均衡系统会根据客户端的 IP地址和请求的 url 和相应的区域负载均衡系统通信
- 5.区域负载均衡系统拿着这两个东西获取距离客户端最近且有相应资源的cdn 缓存服务器的地址,返回给全局负载均衡系统
- 6.全局负载均衡系统返回确定的 cdn 缓存服务器的地址给客户端。
- 7.客户端请求缓存服务器上的文件
什 么 是 x s s ? 什 么 是 c s r f ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{什么是xss?什么是csrf?⭐⭐⭐⭐⭐} 什么是xss?什么是csrf?⭐⭐⭐⭐⭐
- xss脚本注入
- 不需要你做任何的登录认证,它会通过合法的操作(比如在url中输入、在评论框中输入),向你的页面注入脚本(可能是js、hmtl代码块等)。
- 防御
- 编码:对用户输入的数据进行HTML Entity 编码。把字符转换成转义字符。Encode的作用是将$var等一些字符进行转化,使得浏览器在最终输出结果上是一样的。
- 过滤:移除用户输入的和事件相关的属性。
- csrf跨域请求伪造
- 在未退出A网站的前提下访问B,B使用A的cookie去访问服务器
- 防御:token,每次用户提交表单时需要带上token(伪造者访问不到),如果token不合法,则服务器拒绝请求
O W A S P t o p 10 ( 10 项 最 严 重 的 W e b 应 用 程 序 安 全 风 险 列 表 ) 都 有 哪 些 ? ⭐ ⭐ ⭐ \color{#0000FF}{OWASP top10 (10项最严重的Web应用程序安全风险列表)都有哪些?⭐⭐⭐} OWASPtop10(10项最严重的Web应用程序安全风险列表)都有哪些?⭐⭐⭐
- SQL注入
- 在输入框里输入sql命令
- 失效的身份验证
- 拿到别人的cookie来向服务端发起请求,就可以做到登陆的目的
- 敏感数据泄露
- 明文传输状态下可能被抓包拦截,这时候就造成数据泄露
- 想做到抓包,比如在网吧,共享一个猫上网,这时候抓包就可行,方法网上一搜一大把
- 不过此风险大部分网站都能得到很好的解决,https或者md5加密都可以
- 明文传输状态下可能被抓包拦截,这时候就造成数据泄露
- XML 外部实体
- 失效的访问控制
- 安全配置错误
- XSS
- 不安全的反序列化
- 使用含有已知漏洞的组件
- 不足的日志记录和监控
面 试 官 : 什 么 是 回 流 什 么 是 重 绘 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:什么是回流 什么是重绘?⭐⭐⭐⭐⭐} 面试官:什么是回流什么是重绘?⭐⭐⭐⭐⭐
- 回流
- render树中一部分或全部元素需要改变尺寸、布局、或着需要隐藏而需要重新构建,这个过程叫做回流
- 回流必将引起重绘
- 重绘
- render树中一部分元素改变,而不影响布局的,只影响外观的,比如颜色。该过程叫做重绘
页面至少经历一次回流和重绘(第一次加载的时候)
f e t c h 直 接 请 求 一 个 跨 域 地 址 失 败 了 , 前 后 端 分 别 做 什 么 改 造 \color{#0000FF}{fetch直接请求一个跨域地址失败了,前后端分别做什么改造 } fetch直接请求一个跨域地址失败了,前后端分别做什么改造
(mode:cors + access control)
箭 头 函 数 和 普 通 函 数 的 区 别 \color{#0000FF}{箭头函数和普通函数的区别} 箭头函数和普通函数的区别
- 外形不同
- 箭头函数全都是匿名函数
- 箭头函数不能用于构造函数
- 箭头函数不具有arguments对象
- 箭头函数的this指向不同,箭头函数的 this 永远指向其上下文的 this ,任何方法都改变不了其指向,如 call() , bind() , apply();普通函数的this指向调用它的那个对象
- 箭头函数不能Generator函数,不能使用yeild关键字。
- 箭头函数不具有prototype原型对象。
- 箭头函数不具有super。
- 箭头函数不具有new.target。
杂项
s e t 返 回 什 么 类 型 , 怎 么 转 为 数 组 \color{#0000FF}{set返回什么类型,怎么转为数组} set返回什么类型,怎么转为数组
- set返回都是一个没有重复元素得对象合集
- 转为数组得方式有以下几种:
- Array.from(new Set())
- […new Set()]
事 件 冒 泡 和 事 件 捕 捉 有 什 么 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{事件冒泡和事件捕捉有什么区别⭐⭐⭐⭐⭐} 事件冒泡和事件捕捉有什么区别⭐⭐⭐⭐⭐
- 事件冒泡
- 在addEventListener中的第三属性设置为false(默认)
- 从下至上(儿子至祖宗)执行
- 事件捕捉
- 在addEventListener中的第三属性设置为true
- 从上至下(祖宗到儿子)执行
什 么 是 防 抖 ? 什 么 是 节 流 ? 手 写 一 个 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{什么是防抖?什么是节流?手写一个⭐⭐⭐⭐⭐} 什么是防抖?什么是节流?手写一个⭐⭐⭐⭐⭐
- 防抖
- n秒后在执行该事件,若在n秒内被重复触发,则重新计时
- 节流
- n秒内只运行一次,若在n秒内重复触发,只有一次生效
// ---------------------------------------------------------防抖函数
function debounce(func, delay) {
let timeout
return function () {
let arg = arguments
if (timeout) clearTimeout(timeout)
timeout = setTimeout(() => {
func(arg)
}, delay);
}
}
// ---------------------------------------------------------立即执行防抖函数
function debounce2(fn, delay) {
let timer
return function () {
let args = arguments
if (timer) clearTimeout(timer)
let callNow = !timer
timer = setTimeout(() => {
timer = null
}, delay);
if (callNow) { fn(args) }
}
}
// ---------------------------------------------------------立即执行防抖函数+普通防抖
function debounce3(fn, delay, immediate) {
let timer
return function () {
let args = arguments
let _this = this
if (timer) clearTimeout(timer)
if (immediate) {
let callNow = !timer
timer = setTimeout(() => {
timer = null
}, delay);
if (callNow) { fn.apply(_this, args) }
} else {
timeout = setTimeout(() => {
func.apply(_this, arguments)
}, delay);
}
}
}
// ---------------------------------------------------------节流 ,时间戳版
function throttle(fn, wait) {
let previous = 0
return function () {
let now = Date.now()
let _this = this
let args = arguments
if (now - previous > wait) {
fn.apply(_this, arguments)
previous = now
}
}
}
// ---------------------------------------------------------节流 ,定时器版
function throttle2(fn, wait) {
let timer
return function () {
let _this = this
let args = arguments
if (!timer) {
timer = setTimeout(() => {
timer = null
fn.apply(_this, arguments)
}, wait);
}
}
}
函
数
柯
里
化
原
理
⭐
⭐
⭐
⭐
⭐
\color{#0000FF}{函数柯里化原理⭐⭐⭐⭐⭐}
函数柯里化原理⭐⭐⭐⭐⭐
原理:柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术
function add() {
var args = Array.prototype.slice.call(arguments)
var adder = function () {
args.push(...arguments)
return adder
}
adder.toString = function () {
return args.reduce((prev, curr) => {
return prev + curr
}, 0)
}
return adder
}
let a = add(1, 2, 3)
let b = add(1)(2)(3)
console.log(a)
console.log(b)
console.log(add(1, 2)(3));
console.log(Function.toString)
什 么 是 r e q u e s t A n i m a t i o n F r a m e ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{什么是requestAnimationFrame?⭐⭐⭐⭐} 什么是requestAnimationFrame?⭐⭐⭐⭐
- requestAnimationFrame请求数据帧可以用做动画执行
- 可以自己决定什么时机调用该回调函数
- 能保证每次频幕刷新的时候只被执行一次
- 页面被隐藏或者最小化的时候暂停执行,返回窗口继续执行,有效节省CPU
var s = 0
function f() {
s++
console.log(s);
if (s < 999) {
window.requestAnimationFrame(f)
}
}
window.requestAnimationFrame(f)
j s 常 见 的 设 计 模 式 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{js常见的设计模式⭐⭐⭐⭐⭐} js常见的设计模式⭐⭐⭐⭐⭐
单例模式、工厂模式、构造函数模式、发布订阅者模式、迭代器模式、代理模式
单例模式:不管创建多少个对象都只有一个实例
var Single = (function () {
var instance = null
function Single(name) {
this.name = name
}
return function (name) {
if (!instance) {
instance = new Single(name)
}
return instance
}
})()
var oA = new Single('hi')
var oB = new Single('hello')
console.log(oA);
console.log(oB);
console.log(oB === oA);
工厂模式:代替new创建一个对象,且这个对象想工厂制作一样,批量制作属性相同的实例对象(指向不同)
function Animal(o) {
var instance = new Object()
instance.name = o.name
instance.age = o.age
instance.getAnimal = function () {
return "name:" + instance.name + " age:" + instance.age
}
return instance
}
var cat = Animal({name:"cat", age:3})
console.log(cat);
构造函数模式发布订阅者模式
class Watcher {
// name模拟使用属性的地方
constructor(name, cb) {
this.name = name
this.cb = cb
}
update() {//更新
console.log(this.name + "更新了");
this.cb() //做出更新回调
}
}
class Dep {//依赖收集器
constructor() {
this.subs = []
}
addSubs(watcher) {
this.subs.push(watcher)
}
notify() {//通知每一个观察者做出更新
this.subs.forEach(w => {
w.update()
});
}
}
// 假如现在用到age的有三个地方
var w1 = new Watcher("我{{age}}了", () => { console.log("更新age"); })
var w2 = new Watcher("v-model:age", () => { console.log("更新age"); })
var w3 = new Watcher("I am {{age}} years old", () => { console.log("更新age"); })
var dep = new Dep()
dep.addSubs(w1)
dep.addSubs(w2)
dep.addSubs(w3)
// 在Object.defineProperty 中的 set中运行
dep.notify()
-
代理模式 -
迭代器模式
J S 性 能 优 化 的 方 式 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{JS性能优化的方式⭐⭐⭐⭐⭐} JS性能优化的方式⭐⭐⭐⭐⭐
- 垃圾回收
- 闭包中的对象清除
- 防抖节流
- 分批加载(setInterval,加载10000个节点)
- 事件委托
- 少用with
- requestAnimationFrame的使用
- script标签中的defer和async
- CDN
t s 是 什 么 , 为 什 么 要 用 t s , 是 标 准 吗 \color{#0000FF}{ts是什么,为什么要用ts,是标准吗} ts是什么,为什么要用ts,是标准吗
- TypeScript是JavaScript的超集,具有可选的类型并可以编译为纯JavaScript。从技术上讲TypeScript就是具有静态类型的JavaScript
- 模块管理更佳 、类型检查更严格、它使我们的开发严谨而自由
- TypeScript不是标准
e s 5 和 e s 6 的 继 承 有 什 么 区 别 \color{#0000FF}{es5和es6的继承有什么区别} es5和es6的继承有什么区别
es5
- ES5的继承是先创建子类的实例, 然后再创建父类的方法添加到this上
- 通过原型和构造函数机制实现的
es6
- ES6的继承是先创建父类的实例对象this(必须先调用super方法), 再调用子类的构造函数修改this
- 通过关键字class定义类, extends关键字实现继承.
- 子类必须在constructor方法中调用super方法否则创建实例报错. 因为子类没有this对象, 而是使用父类的this, 然后对其进行加工
super关键字指代父类的this, 在子类的构造函数中, 必须先调用super, 然后才能使用this
列 举 几 个 e s 6 新 特 性 \color{#0000FF}{列举几个es6新特性} 列举几个es6新特性
变量定义:let Const
解构赋值
扩展运算符
Symbol数据类型
Set 和 Map 数据结构
Promise
Class
箭头函数
Proxy拦截
imoprt模块导入
新增了一些数组的方法
新增了一些对象的方法
- 变量定义:let Const
- 解构赋值
- 扩展运算符
- Symbol数据类型
- Set 和 Map 数据结构
- Promise
- Class
- 箭头函数
- Proxy拦截
- imoprt模块导入
- 新增了一些数组的方法
- 新增了一些对象的方法

数 组 m a p 和 f o r E a c h 的 区 别 \color{#0000FF}{数组map和forEach的区别} 数组map和forEach的区别
- map会返回一个新的数组
- map方法不会对空数组进行检测,map方法不会改变原始数组
- forEach不会返回任何东西
s p l i c e 和 s l i c e 的 区 别 \color{#0000FF}{splice和slice的区别} splice和slice的区别
- .slice(start,end):方法可从已有数组中返回选定的元素,返回一个新数组,包含从start到end(不包含该元素)的数组元素
- splice():该方法向数组中添加或者删除项目,返回被删除的项目(是个数组)。(该方法会改变原数组)
p r o m i s e 、 a s y n c / a w a i t \color{#0000FF}{promise、async/await} promise、async/await
promise和async都是做异步处理的, 使异步转为同步
- Promise是es6里的,async是es7了
- Promise原来有规范的意义,Promise a、b、c、d等规范,最终确定的是promise a+规范
- Promise链式操作,自己catch异常。async则要在函数内catch,好在现在catch成本较低。
- Promise有很多并行神器,比如Promise.all\Promise.race等。这些是async没法搞定的。
- Promise是显式的异步,而 让你的代码看起来是同步的,你依然需要注意异步。
- Promise即使不支持es6,你依然可以用promise的库或polyfil,而async就很难做,当然也不是不能,成本会高很多。
- async functions 和 Array.forEach等结合,很多tc39提案都在路上或者已经实现,处于上升期,而promise也就那样了。
js问题实现思路
统计字符串中的哪个字符出现次数最多
// 实现思路:先将字符串遍历,存为map对象,统计唯一字符出现得个数
const str = "dasdwqsdgdgretwq";
// 两个for方式实现
function twoFor(str) {
let strMap = {};
let num = 0;
let resStr = [];
for (let i=0; i<str.length; i++) {
if (str[i] in strMap){
strMap[str[i]].num++;
} else {
strMap[str[i]] = {
num: 1
}
}
}
for (let k in strMap) {
if (strMap[k].num > num) {
resStr = [k];
num = strMap[k].num;
} else if (strMap[k].num == num) {
resStr.push(k);
num = strMap[k].num;
}
}
console.log("出现次数最多得字符是:" + resStr.join(","), "出现次数为:" + num)
}
towFor(str); //出现次数最多得字符是:d 出现次数为:4
// 使用reduce + for的方式
function reduceAndFor(str) {
let num = 0;
let resStr = []
const strMap = str.split("").reduce((pre, cur) => {
if (cur in pre) {
pre[cur]++;
} else {
pre[cur] = 1;
}
return pre;
}, {})
for (let k in strMap) {
if (strMap[k]> num) {
resStr = [k];
num = strMap[k];
} else if (strMap[k]== num) {
resStr.push(k);
num = strMap[k];
}
}
console.log("出现次数最多得字符是:" + resStr.join(","), "出现次数为:" + num)
}
reduceAndFor(str); // 出现次数最多得字符是:d 出现次数为:4
字符串反转
// 方式一:将字符串转为数组,通过unshift
const str = "qwertyyy";
function reverse1(str) {
let strArr = [];
for (let i = 0; i < str.length; i++) {
strArr.unshift(str[i])
}
console.log(strArr.join(""));
}
reverse1(str); // yyytrewq
// 方法二:使用reverse+join
function reverse2(str) {
const res = str.split("").reverse().join("");
console.log(res);
}
reverse2(str); // yyytrewq
// 方法三: 使用charAt,通过查找对应下标的数据,进行反序输出
function reverse3(str) {
let res = '';
for (let i = str.length; i>=0; i--) {
res += str.charAt(i);
}
console.log(res);
}
reverse3(str); // yyytrewq
找峰,一个数组里找第一个峰值,followup(加分):全局最大值的算法呢?
// 找出数组中的第一个峰值
const arr = [4, 1, 4, 6, 2, 1]
function lookFirstFeng(arr) {
let res = 0;
if (arr.length == 1) {
res = arr[0]
} else if (arr.length == 2) {
res = Math.max(arr[0], arr[1]);
} else {
for (let i = 0; i < arr.length - 1; i++) {
if (arr[i] <= arr[i + 1]) {
res = arr[i + 1];
} else {
res = arr[i];
break
}
}
}
console.log(res) // 4
}
lookFirstFeng(arr)
// 寻找数组中的最大峰值
function lookMaxFeng(arr) {
const res = arr.reduce((pre, cur, index) => {
if (pre < cur) {
return arr[index];
}
return pre;
})
console.log(res); // 6
}
lookMaxFeng(arr);
function lookMaxFeng1(arr) {
let res = 0;
arr.forEach(item => {
if (res <= item) {
res = item;
}
})
console.log(res); // 6
}
lookMaxFeng1(arr);
数组中找到两数和为指定值的索引
const arr = [4, 1, 4, 6, 2, 1];
/**
* 暴力解决,直接双重for循环
* @param {*} arr
* @param {*} total
*/
function lookTotalIndex(arr, total) {
for (let i = 0; i < arr.length; i++) {
for (let j = i + 1; j < arr.length; j++) {
if (arr[i] + arr[j] == total) {
console.log([i, j]);
// [ 1, 4 ]
// [ 4, 5 ]
}
}
const arr1 = Array.from(new Set(arr));
lookTotalIndex(arr, 3)
/**
* 先将数组排序,然后将数组首尾相加比较
* @param {*} arr
* @param {*} target
*/
function lookTotalIndex1(arr, target) {
const newArr = arr.sort();
let left = 0;
let right = newArr.length - 1;
while (left < right) {
if (newArr[left] + newArr[right] > target) {
right--;
} else if (newArr[left] + newArr[right] < target) {
left++
} else {
console.log([left, right])
// [0, 2]
left++;
right--
}
}
}
lookTotalIndex1(arr, 3)
字符串输出下标为奇数的字符串
const str = "dasdwqsdgdgretwqss";
function findOddStr(str) {
let res = "";
for (let i = 0; i < str.length; i++) {
// 因为下标是从0开始计算的,所以取余应该是0,而不是1
if (i % 2 == 0) {
res += str[i];
}
}
console.log(res); // dswsggews
}
findOddStr(str);
字符串截取,将某个字符替换
// 替换字符串 replace, 使用正则
const str = 'dasdwqsdgdgretwqss';
/**
* 全局替换
* @param {*} strs 字符串整体
* @param {*} sou 将要替换的字符串
* @param {*} tar 将要替换成的字符串
*/
function replaceAllStr(strs, sou, tar) {
const reg = new RegExp(sou, "g"); // 动态正则表达式
console.log(strs.replace(reg, tar));
}
replaceAllStr(str, 'd', 6); // 6as6wqs6g6gretwqss
// 截取字符串 slice, substring, substr 接受两个参数
// 第一个参数表示起始位置,如果为0,表示返回整个字符串
// 第二个参数表示结束位置
/**
*
* @param {*} str 要截取的字符串
* @param {*} start 截取起始点
* @param {*} end 截取结束点
*/
function sliceStr(str, start, end) {
// console.log(str.slice(start, end))
// console.log(str.substring(start, end))
// console.log(str.substr(start, end))
// console.log(str.slice(start))
return str.slice(start, end)
}
// 拼接字符串
const str1 = "aaaabbbbcccc";
const str2 = "ddddeeeeffff";
// 拼接为aaaabbbbccccddddeeeeffff
console.log(str1 + str2);
// 拼接为aaaaffff
console.log(sliceStr(str1, 0, 4) + sliceStr(str2, 8, 12))
如何给一个一个异步设置超时时间 axios
Vue
Vue双向绑定
数据劫持:vue.js是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调
阐 述 一 下 你 所 理 解 的 M V V M 响 应 式 原 理 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{阐述一下你所理解的MVVM响应式原理⭐⭐⭐⭐⭐} 阐述一下你所理解的MVVM响应式原理⭐⭐⭐⭐⭐
- vue是采用数据劫持配合发布者-订阅者的模式的方式,通过Object.defineProperty()来劫持各个属性的getter和setter,在数据变动时,发布消息给依赖收集器(dep中的subs),去通知(notify)观察者,做出对应的回调函数,去更新视图
- MVVM作为绑定的入口,整合Observer,Compile和Watcher三者,通过Observer来监听model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer,Compile之间的通信桥路,达到数据变化=>视图更新;视图交互变化=>数据model变更的双向绑定效果。
vue性能优化
杂乱笔记
-
data中每一个数据都绑定一个Dep,这个Dep中都存有所有用到该数据的观察者
-
当数据改变时,发布消息给dep(依赖收集器),去通知每一个观察者。做出对应的回调函数
const dep = new Dep() // 劫持并监听所有属性 Object.defineProperty(obj, key, { enumerable: true, configurable: false, get() { // 订阅数据变化时,在Dep中添加观察者 Dep.target && dep.addSub(Dep.target) return value }, set: (newVal) => { if (newVal !== value) { this.observe(newVal) value = newVal } // 告诉Dep通知变化 dep.notify() }, })
面 试 官 : 说 说 v u e 的 生 命 周 期 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:说说vue的生命周期⭐⭐⭐⭐⭐} 面试官:说说vue的生命周期⭐⭐⭐⭐⭐
beforeCreate:创建之前,此时还没有data和Method
Created:创建完成,此时data和Method可以使用了,在Created之后beforeMount之前如果没有el选项的话那么此时生命周期结束,停止编译,如果有则继续
beforeMount:在渲染之前
mounted:页面已经渲染完成,并且vm实例中已经添加完$el了,已经替换掉那些DOM元素了(双括号中的变量),这个时候可以操作DOM了(但是是获取不了元素的高度等属性的,如果想要获取,需要使用nextTick())
beforeUpdate:data改变后,对应的组件重新渲染之前
updated:data改变后,对应的组件重新渲染完成
beforeDestory:在实例销毁之前,此时实例仍然可以使用
destoryed:实例销毁后
面 试 官 : v u e 中 父 子 组 件 的 生 命 周 期 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:vue中父子组件的生命周期⭐⭐⭐⭐⭐} 面试官:vue中父子组件的生命周期⭐⭐⭐⭐⭐
父子组件的生命周期是一个嵌套的过程
- 渲染的过程
- 父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
- 子组件更新过程
- 父beforeUpdate->子beforeUpdate->子updated->父updated
- 父组件更新过程
- 父beforeUpdate->父updated
- 销毁过程
- 父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
V u e 中 的 n e x t T i c k ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{Vue中的nextTick⭐⭐⭐⭐⭐} Vue中的nextTick⭐⭐⭐⭐⭐
nextTick
- 解释
- nextTick:在下次 DOM 更新循环结束之后执行延迟回调。在修改数据之后立即使用这个方法,获取更新后的 DOM。
- 应用
- 想要在Vue生命周期函数中的created()操作DOM可以使用Vue.nextTick()回调函数
- 在数据改变后要执行的操作,而这个操作需要等数据改变后而改变DOM结构的时候才进行操作,需要用到nextTick
面 试 官 : c o m p u t e d 和 w a t c h 的 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:computed和watch的区别⭐⭐⭐⭐⭐} 面试官:computed和watch的区别⭐⭐⭐⭐⭐
- computed
- 计算属性,依赖其他属性,当其他属性改变的时候下一次获取computed值时也会改变,computed的值会有缓存
- watch
- 类似于数据改变后的回调
- 如果想深度监听的话,后面加一个deep:true
- 如果想监听完立马运行的话,后面加一个immediate:true
面 试 官 : V u e 优 化 方 式 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:Vue优化方式⭐⭐⭐⭐⭐} 面试官:Vue优化方式⭐⭐⭐⭐⭐
- v-if 和v-show
- 使用Object.freeze()方式冻结data中的属性,从而阻止数据劫持
- 组件销毁的时候会断开所有与实例联系,但是除了addEventListener,所以当一个组件销毁的时候需要手动去removeEventListener
- 图片懒加载
- 路由懒加载
- 为减少重新渲染和创建dom节点的时间,采用虚拟dom
面 试 官 : V u e − r o u t e r 的 模 式 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:Vue-router的模式⭐⭐⭐⭐⭐} 面试官:Vue−router的模式⭐⭐⭐⭐⭐
- hash模式
- 监听hashchange事件实现前端路由,利用url中的hash来模拟一个hash,以保证url改变时,页面不会重新加载。
- history模式
- 利用pushstate和replacestate来将url替换但不刷新,但是有一个致命点就是,一旦刷新的话,就会可能404,因为没有当前的真正路径,要想解决这一问题需要后端配合,将不存在的路径重定向到入口文件。
面 试 官 : M V C 与 M V V M 有 什 么 区 别 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{面试官:MVC与MVVM有什么区别⭐⭐⭐⭐⭐} 面试官:MVC与MVVM有什么区别⭐⭐⭐⭐⭐
- MVC
- Model(模型)是应用程序中用于处理应用程序数据逻辑的部分。通常模型对象负责在数据库中存取数据。
- View(视图)是应用程序中处理数据显示的部分。通常视图是依据模型数据创建的。
- Controller(控制器)是应用程序中处理用户交互的部分。
- 通常控制器负责从视图读取数据,控制用户输入,并向模型发送数据。
d i f f 算 法 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{diff算法⭐⭐⭐⭐⭐} diff算法⭐⭐⭐⭐⭐
diff算法是指对新旧虚拟节点进行对比,并返回一个patch对象,用来存储两个节点不同的地方,最后利用patch记录的消息局部更新DOM
虚 拟 D O M 的 优 缺 点 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{虚拟DOM的优缺点⭐⭐⭐⭐⭐} 虚拟DOM的优缺点⭐⭐⭐⭐⭐
- 缺点
- 首次渲染大量DOM时,由于多了一层虚拟DOM的计算,会比innerHTML插入慢
- 优点
- 减少了dom操作,减少了回流与重绘
- 保证性能的下限,虽说性能不是最佳,但是它具备局部更新的能力,所以大部分时候还是比正常的DOM性能高很多的
V u e 的 K e y 的 作 用 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{Vue的Key的作用 ⭐⭐⭐⭐} Vue的Key的作用⭐⭐⭐⭐
key主要用在虚拟Dom算法中,每个虚拟节点VNode有一个唯一标识Key,通过对比新旧节点的key来判断节点是否改变,用key就可以大大提高渲染效率,这个key类似于缓存中的etag。
V u e 组 件 之 间 的 通 信 方 式 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{Vue组件之间的通信方式⭐⭐⭐⭐⭐} Vue组件之间的通信方式⭐⭐⭐⭐⭐
- 子组件设置props + 父组件设置v-bind:/:
- 父传子
- 子组件的$emit + 父组件设置v-on/@
- 子传父
- 任意组件通信,新建一个空的全局Vue对象,利用emit发送 , emit发送,emit发送,on接收
- 传说中的$bus
- 任意组件
Vue.prototype.Event=new Vue();
Event.$emit(事件名,数据);
Event.$on(事件名,data => {});
- Vuex
- 里面的属性有:
- state
- 存储数据的
- 获取数据最好推荐使用getters
- 硬要使用的话可以用MapState, 先引用,放在compute中…mapState([‘方法名’,‘方法名’])
- getters
- 获取数据的
- this.$store.getters.xxx
- 也可使用mapGetters 先引用,放在compute中,…mapGetters([‘方法名’,‘方法名’])
- mutations
- 同步操作数据的
- this.$store.commit(“方法名”,数据)
- 也可使用mapMutations ,使用方法和以上一样
- actions
- 异步操作数据的
- this.$store.dispatch(“方法名”,数据)
- 也可使用mapActions ,使用方法和以上一样
- modules
- 板块,里面可以放多个vuex
- state
- 里面的属性有:
- 父组件通过v-bind:/:传值,子组件通过this.$attrs获取
- 父传子
- 当子组件没有设置props的时候可以使用
- this.$attrs获取到的是一个对象(所有父组件传过来的集合)
- 祖先组件使用provide提供数据,子孙组件通过inject注入数据
- p a r e n t / parent/parent/children
- refs—$ref
- 还有一个,这个网上没有,我自己认为的,我觉得挺对的,slot-scope,本身父组件使用slot插槽是无法获取子组件的数据的,但是使用了slot-scope就可以获取到子组件的数据(拥有了子组件的作用域)
V u e − r o u t e r 有 哪 几 种 钩 子 函 数 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{Vue-router有哪几种钩子函数⭐⭐⭐⭐⭐} Vue−router有哪几种钩子函数⭐⭐⭐⭐⭐
- beforeEach
- 参数有
- to(Route路由对象)
- from(Route路由对象)
- next(function函数) 一定要调用才能进行下一步
- 参数有
- afterEach
- beforeRouterLeave
拦 截 器 的 理 解 , 项 目 中 需 要 做 拦 截 的 场 景 以 及 如 何 做 拦 截 \color{#0000FF}{拦截器的理解,项目中需要做拦截的场景以及如何做拦截} 拦截器的理解,项目中需要做拦截的场景以及如何做拦截
- 拦截器的作用:因为后端每次响应都不一定是成功的,然后前端需要根据不同状态去做不同的处理,如果每个请求都去做处理,会多出很多重复的代码,并且显的很臃肿,所以需要拦截器统一处理项目中后续的接口请求和响应
- 使用场景:判断用户是否登录,是否具有某些权限,统一处理项目中后续的接口请求和响应 等
简 单 说 一 下 拦 截 器 是 如 何 实 现 的 。 \color{#0000FF}{简单说一下拦截器是如何实现的。} 简单说一下拦截器是如何实现的。
- 路由拦截器:使用路由守卫,在跳转路由前后做一些判断,相当于一个钩子函数
- 接口拦截器:使用axios的interceptors上的request和response,可以对接口请求和相应做对应的拦截
React
react 基础面试题
R e a c t 有 什 么 特 点 \color{#0000FF}{React有什么特点} React有什么特点
- 使用虚拟dom,并不是真正的dom
- 它可以用服务端渲染
- 它遵循单向数据流或数据绑定
R e a c t 的 一 些 主 要 优 点 \color{#0000FF}{React的一些主要优点} React的一些主要优点
- 它提高了应用的性能
- 可以方便的在客户端和服务器端渲染
- 由于jsx,代码的可读性很好
- React很容易与Meteor、Angular等其他框架集成
- 使用React,编写UI测试用例变得非常容易
R e a c t 有 什 么 限 制 \color{#0000FF}{React有什么限制} React有什么限制
- React的库非常大,需要时间来解析
- React只有一个库,而不是完整的一个框架
- 新手程序员可能很难理解
- 编码变得复杂,因为它使用内联模板和JSX
R e a c t 通 信 方 式 \color{#0000FF}{React通信方式} React通信方式
- 状态管理:redux
- props
- 浏览器缓存
- 路由带参数
- context:跨组件传递信息
单 向 数 据 流 需 要 注 意 什 么 \color{#0000FF}{单向数据流需要注意什么} 单向数据流需要注意什么
如果单向数据流传递的是引用数据类型的时候,对于一个数组或者对象类型的props来说,在子组件改变这个props的时候,将会影响到父组件的状态更新,所以需要对props进行深拷贝处理
R e a c t 合 成 事 件 \color{#0000FF}{React合成事件} React合成事件
- 合成事件机制:react并不是将click事件,直接绑定在dom上的,而是采用事件冒泡的形式冒泡带document上面,然后将react事件封装给正式的函数处理运行
- 为什么要使用合成事件
- 如果dom上绑定了过多的事件处理,整个页面的响应以及内存占用可能会受到影响,这样简化了dom原生事件,减少了内存的开销
- react为了屏蔽这类dom事件滥用,同时屏蔽了底层不同浏览器之间的系统差异,实现了一个中间层–SyntheticEvent
- react内部事件系统可以分为两个阶段:时间注册,事件触发
hooks
为 什 么 要 使 用 h o o k s ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{为什么要使用hooks⭐⭐⭐⭐⭐} 为什么要使用hooks⭐⭐⭐⭐⭐
为了解决一些component问题:
- 组件之间的逻辑状态难以复用
- 大型复杂的组件很难拆分
- Class 语法的使用不友好
没有hooks:
- 类组件可以访问生命周期,函数组件不能
- 类组件可以定义维护state(状态),函数组件不可以
- 类组件中可以获取到实例化后的this,并基于这个this做一些操作,而函数组件不可以
- mixins:变量作用于来源不清、属性重名、Mixins引入过多会导致顺序冲突
- HOC和Render props:组件嵌套过多,不易渲染调试、会劫持props,会有漏洞
有了hooks:
- Hooks 就是让你不必写class组件就可以用state和其他的React特性;
- 也可以编写自己的hooks在不同的组件之间复用
hooks的优点:
- 没有破坏性改动:完全可选的。 你无需重写任何已有代码就可以在一些组件中尝试 Hook。100% 向后兼容的。 Hook不包含任何破坏性改动。
- 更容易复用代码:它通过自定义hooks来复用状态,从而解决了类组件逻辑难以复用的问题
- 函数式编程风格:函数式组件、状态保存在运行环境、每个功能都包裹在函数中,整体风格更清爽、优雅
- 代码量少,复用性高
- 更容易拆分
hooks的缺点:
- hooks 是 React 16.8 的新增特性、以前版本的就别想了
- 状态不同步(闭包带来的坑):函数的运行是独立的,每个函数都有一份独立的闭包作用域。当我们处理复杂逻辑的时候,经常会碰到“引用不是最新”的问题
- 使用useState时候,使用push,pop,splice等直接更改数组对象的坑,demo中使用push直接更改数组无法获取到新值,应该采用析构方式原因:push,pop,splice是直接修改原数组,react会认为state并没有发生变化,无法更新)
- useState 初始化只初始化一次
- useEffect 内部不能修改 state
- useEffect 依赖引用类型会出现死循环
- 不要在循环,条件或嵌套函数中调用Hook,必须始终在React函数的顶层使用Hook。这是因为React需要利用调用顺序来正确更新相应的状态,以及调用相应的钩子函数。一旦在循环或条件分支语句中调用Hook,就容易导致调用顺序的不一致性,从而产生难以预料到的后果
i f e l s e 条 件 判 断 里 使 用 h o o k s 有 什 么 问 题 ⭐ ⭐ ⭐ \color{#0000FF}{if else条件判断里使用hooks有什么问题⭐⭐⭐} ifelse条件判断里使用hooks有什么问题⭐⭐⭐
- if else里面不能用hooks,hooks是有顺序的
- 不能用在if else 或者循环里面 还有非顶层的函数内部
- hooks在初始化时候是以链表形式存储的,后续更新都是按照这个链表顺序执行的
最 后 举 例 说 一 下 H o o k s 的 基 本 实 现 原 理 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{最后举例说一下 Hooks 的基本实现原理⭐⭐⭐⭐⭐} 最后举例说一下Hooks的基本实现原理⭐⭐⭐⭐⭐
重写useState
import React from 'react'
// 导入dom,用于更新组件
import ReactDom from 'react-dom'
let state
function useState(initState) {
// 判断state 是否是初始化
state = state ? state : initState
function setState(newState) {
// 更新数据
state = newState
// 调用函数,更新组件
render()
}
return [state, setState]
}
// 重新渲染组件
function render() {
ReactDom.render(<App />, document.getElementById('root'))
}
function App() {
// 使用自定义 useState
const [count, setCount] = useState(1);
return (
<div>
<p>{count}</p>
<button onClick={() => setCount(count + 1)}>加1</button>
</div>
)
}
export default App
Rudi Yardley 在 2018 年的时候写过一篇文章 《React hooks: not magic, just arrays》,详细地阐释了它的设计原理,感兴趣的话可以找来看一下,上面案例,其实就是文章中用到的,通过在函数中调用 useState 会返回当前状态与更新状态的函数。count 的初始值是 1,然后,通过 useState 赋值初始值,然后获取当前状态 state 与函数 setState。那么在点击按钮时调用 setCount,修改 count 的值。
Hook 和现有代码可以同时工作,你可以渐进式地使用他们。 不用急着迁移到 Hook。我们建议避免任何“大规模重写”,尤其是对于现有的、复杂的 class 组件。开始“用 Hook 的方式思考”前,需要做一些思维上的转变
h o o k s 闭 包 的 坑 有 哪 些 ? 如 何 解 决 \color{#0000FF}{hooks闭包的坑有哪些?如何解决} hooks闭包的坑有哪些?如何解决
问题:每次 render 都有一份新的状态,数据卡在闭包里,捕获了每次 render 后的 state,也就导致了输出原来的 state
解决:可以通过 useRef 来保存 state。前文讲过 ref 在组件中只存在一份,无论何时使用它的引用都不会产生变化,因此可以来解决闭包引发的问题。
常 用 的 H o o k s 有 哪 些 ? \color{#0000FF}{常用的Hooks有哪些?} 常用的Hooks有哪些?
- useState()状态钩子。为函数组建提供内部状态
- useContext()共享钩子。该钩子的作用是,在组件之间共享状态。
可以解决react逐层通过Porps传递数据,它接受React.createContext()的返回结果作为参数,使用useContext将不再需要Provider
和 Consumer - useReducer()状态钩子。Action 钩子。useReducer()
提供了状态管理,其基本原理是通过用户在页面中发起action, 从而通过reducer方法来改变state,
从而实现页面和状态的通信。使用很像redux - useEffect()副作用钩子。它接收两个参数, 第一个是进行的异步操作, 第二个是数组,用来给出Effect的依赖项
- useRef()获取组件的实例;渲染周期之间共享数据的存储(state不能存储跨渲染周期的数据,因为state的保存会触发组件重渲染),useRef传入一个参数initValue,并创建一个对象{
current: initValue }给函数组件使用,在整个生命周期中该对象保持不变 - useMemo和useCallback可缓存函数的引用或值,useMemo缓存数据,useCallback缓存函数,两者是Hooks的常见优化策略,useCallback(fn,deps)相当于useMemo(()=>fn,deps),经常用在下面两种场景:
- 1、要保持引用相等;对于组件内部用到的 object、array、函数等,
- 2、用在了其他 Hook 的依赖数组中,或者作为 props 传递给了下游组件,应该使用 useMemo/useCallback)
u s e M e m o 和 u s e C a l l b a c k d e 区 别 \color{#0000FF}{useMemo和useCallbackde 区别} useMemo和useCallbackde区别
useMemo和useCallback接受的参数都是一样的,第一个参数为回调,第二个参数为要依赖的数据
- 共同作用:仅对依赖的数据发生变化的时候,才会重新计算结果
- 区别:
useMemo:计算结果是返回一个值,主要用于缓存计算结果的值,应用场景:需要计算的状态。useCallback:计算结果返回的是函数,主要用于缓存函数,应用场景:需要缓存的函数。因为函数式组件每次任何一个state发生变化的时候,整个组件都会被重新渲染,但是有一些函数是不需要重新刷新的,此时就应该缓存起来,提高性能,减少资源浪费
u s e E f f e c t 为 什 么 有 时 候 会 出 现 无 限 重 复 请 求 的 问 题 \color{#0000FF}{useEffect为什么有时候会出现无限重复请求的问题} useEffect为什么有时候会出现无限重复请求的问题
- 可能1 在effect里做数据请求未设置依赖参数,没有依赖项effect 会在每次渲染后执行一次,然后在 effect
中更新了状态引起渲染并再次触发 effect - 可能2 所设置的依赖项总是会变
- 解决:useCallback包一层,或者useMemo
u s e E f f e c t 的 依 赖 项 里 类 数 组 根 据 什 么 来 判 断 有 没 有 值 变 化 \color{#0000FF}{useEffect的依赖项里类数组根据什么来判断有没有值变化} useEffect的依赖项里类数组根据什么来判断有没有值变化
浅比较
R e a c t H o o k s 如 何 模 拟 组 件 生 命 周 期 ? \color{#0000FF}{React Hooks如何模拟组件生命周期?} ReactHooks如何模拟组件生命周期?
- Hooks模拟constructor
constructor(){
super()
this.state={count:0}
}
//Hooks模拟constructor
const [count setCount]=useState(0)
- Hooks模拟componentDidMount
componentDidMount(){
console.log('I am mounted')
}
//Hooks模拟componentDidMount
useEffect(()=>console.log('mounted'),[])
//useEffect拥有两个参数,第一个参数作为回调函数会在浏览器布局和绘制完成后调用,因此它不会阻碍浏览器的渲染进程,第二个参数是一个数组,也是依赖项
//1、当依赖列表存在并有值,如果列表中的任何值发生更改,则每次渲染后都会触发回调
//2、当它不存在时,每次渲染后都会触发回调
//3、当它是一个空列表时,回调只会被触发一次,类似于componentDidMount
- 模拟shouldComponentUpdate
shouldComponentUpdate(nextProps,nextState){
console.log('shouldComponentUpdate')
return true //更新组件 反之不更新
}
// React.memo包裹一个组件来对它的props进行浅比较,但这不是一个hooks,因为它的写法和hooks不同,其实React.memo等效于PureComponent,但它只比较props
// 模拟shouldComponentUpdate
const MyComponent=React.memo(
_MyComponent,
(prevProps,nextProps)=>nextProps.count!==preProps.count
)
- Hooks模拟componentDidUpdate
componentDidMount() {console.log('mounted or updated');}
componentDidUpate(){console.log('mounted or updated')}
//Hooks模拟componentDidUpdate
useEffect(()=>console.log('mounted or updated'))
//这里的回调函数会在每次渲染后调用,因此不仅可以访问componentDidUpdate,还可以访问componentDidMount,如果只想模拟componentDidUpdate,我们可以这样来实现
const mounted=useRef()
useEffect(()=>{
if(!mounted.current){mounted.current=true}else{console.log('I am didUpdate')}
})
//useRef在组件中创建“实例变量”,它作为一个标志来指示组件是否处于挂载或更新阶段。当组件更新完成后在会执行else里面的内容,以此来单独模拟componentDidUpdate
- Hooks模拟componentWillUnmount
componentWillUnmount(){
console.log('will unmount')
}
//hooks
useEffect(()=>{
//此处并不同于willUnMount porps发生变化即更新,也会执行结束监听
//准确的说:返回的函数会在下一次effect执行之前,被执行
return ()=>{console.log('will unmount')}
},[])
//当在useEffect的回调函数中返回一个函数时,这个函数会在组件卸载前被调用。我们可以在这里清除定时器或事件监听器。
模 拟 的 生 命 周 期 和 c l a s s 中 的 生 命 周 期 有 什 么 区 别 吗 ? \color{#0000FF}{模拟的生命周期和class中的生命周期有什么区别吗?} 模拟的生命周期和class中的生命周期有什么区别吗?
- 1、默认的useEffect(不带[])中return的清理函数,它和componentWillUnmount有本质区别的,默认情况下return,在每次useEffect执行前都会执行,并不是只有组件卸载的时候执行。
- 2、useEffect在副作用结束之后,会延迟一段时间执行,并非同步执行,和compontDidMount有本质区别。遇到dom操作,最好使用useLayoutEffect。
hooks 模拟的生命周期与class中的生命周期不尽相同,我们在使用时,还是需要思考业务场景下那种方式最适合。
H o o k s 相 比 H O C 和 R e n d e r P r o p 有 哪 些 优 点 ? \color{#0000FF}{Hooks相比HOC和Render Prop有哪些优点?} Hooks相比HOC和RenderProp有哪些优点?
- hoc和render prop都是一种开发模式,将复用逻辑提升到父组件,容易嵌套过多,过度包装
- hooks是react的api模式,将复用逻辑取到组件顶层,而不是强行提升到父组件中。这样就能够避免 HOC 和 Render Props
带来的「嵌套地域」
u s e E f f e c t 和 u s e L a y o u t E f f e c t 区 别 ? \color{#0000FF}{useEffect和useLayoutEffect区别?} useEffect和useLayoutEffect区别?
- 1、useEffect是render结束后,callback函数执行,但是不会阻断浏览器的渲染,算是某种异步的方式吧。但是class的componentDidMount和componentDidUpdate是同步的,在render结束后就运行,useEffect在大部分场景下都比class的方式性能更好.
- 2、useLayoutEffect是用在处理DOM的时候,当你的useEffect里面的操作需要处理DOM,并且会改变页面的样式,就需要用这个,否则可能会出现出现闪屏问题,
useLayoutEffect里面的callback函数会在DOM更新完成后立即执行,但是会在浏览器进行任何绘制之前运行完成,阻塞了浏览器的绘制
u s e S t a t e 和 s e t S t a t e 区 别 ? \color{#0000FF}{useState和setState区别?} useState和setState区别?
//setState
this.setState(
{count:this.state.count+1},
()=>{
console.log(this.state.count) //通过回调函数监听到最新的值
})
//useState
const[count,setCount]=useState(0)
setCount(1)
useEffect(()=>{
console.log(count) //通过useEffect监听最新的值
},
[count])
- setState是通过回调函数来获取更新的state,useState是通过useEffect() 来获取最新的 state
- 二者第一个参数都可以传入函数
- setState()可以在第2个参数传入回调,useState()没有第2个参数
- setState()自动具备浅合并功能,useState()更新引用需要手动浅合并
u s e S t a t e 中 的 第 二 个 参 数 更 新 状 态 和 c l a s s 中 的 t h i s . s e t S t a t e 区 别 ? \color{#0000FF}{useState中的第二个参数更新状态和class中的this.setState区别?} useState中的第二个参数更新状态和class中的this.setState区别?
- useState 通过数组第二个参数 Set 一个新值后,新值会形成一个新的引用,捕获当时渲染闭包里的数据 State
- setState 是通过 this.state 的读取 state,每次代码执行都会拿到最新的 state 引用
用 u s e S t a t e 实 现 s t a t e 和 s e t S t a t e 功 能 ? \color{#0000FF}{用useState实现state和setState功能?} 用useState实现state和setState功能?
//方法一 模拟setState传入updater和callback
const [n1,setN1]=useState<any>(0)
const [n1,setN2]=useState<any>(0)
setN1((num)=>{
setN2(num+1)
//返回n1修改后的值
return num+1
})
//方法二 自定义hooks,配合引入useRef
export const useXState =(initState)=>{
const [state,setState]=useState(initState)
let isUpdate=useRef()
const setXState=(state,cb)=>{
setState(prev=>{
isUpdate.current=cb
return typeof state==='function'?state(prev):state
})
}
}
useEffect(()=>{
if(isUpdate.current){
isUpdate.current()
}
//useEffect不可以每次渲染组件都执行,因此在每次渲染之后都需要判断其是否值得执行
})
return [state,setXState]
//useRef的特性来作为标识区分是挂载还是更新,当执行setXstate时,会传入和setState一模一样的参数,并且将回调赋值给useRef的current属性,这样在更新完成时,我们手动调用current即可实现更新后的回调这一功能
u s e R e d u c e r 和 r e d u x 区 别 ? \color{#0000FF}{useReducer和redux区别?} useReducer和redux区别?
- useReducer() 提供了状态管理,其基本原理是通过用户在页面中发起action, 从而通过 reducer方法来改变state,从而实现页面和状态的通信,使用很像redux
- useReducer是useState的代替方案,用于state复杂变化
- useReducer是单个组件状态管理,组价通讯还需要props
- redux是全局的状态管理,多组件共享数据
如 何 自 定 义 H O O K \color{#0000FF}{如何自定义HOOK} 如何自定义HOOK
import { useState, useEffect } from 'react';
function useFriendStatus(friendID) {
const [isOnline, setIsOnline] = useState(null);
useEffect(() => {
function handleStatusChange(status) {
setIsOnline(status.isOnline);
}
ChatAPI.subscribeToFriendStatus(friendID, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(friendID, handleStatusChange);
};
});
return isOnline;
}
H o o k s 性 能 优 化 \color{#0000FF}{Hooks性能优化} Hooks性能优化
- useMemo 缓存数据
- useCallback 缓存函数
- 相当于class组件的SCU和PureComponent
怎 么 在 高 阶 组 件 里 面 访 问 组 件 实 例 ? \color{#0000FF}{怎么在高阶组件里面访问组件实例?} 怎么在高阶组件里面访问组件实例?
- 属性代理。高阶组件通过包裹的React组件来操作props,更改props,可以对传递的包裹组件的WrappedComponent的props进行控制
- 通过 refs 获取组件实例
r e a c t 16 即 将 废 弃 的 生 命 周 期 有 哪 些 ? 为 什 么 要 废 弃 \color{#0000FF}{react16即将废弃的生命周期有哪些?为什么要废弃} react16即将废弃的生命周期有哪些?为什么要废弃
- componentWillMount
- componentWillReceiveProps
- componentWillUpdate
废弃原因:在React16的Fiber架构中,调和过程会多次执行will周期,不再是一次执行,失去了原有的意义。此外,多次执行,在周期中如果有setState或dom操作,会触发多次重绘,影响性能,也会导致数据错乱
u s e E f f e c t 和 u s e L a y o u t E f f e c t 的 区 别 \color{#0000FF}{useEffect和useLayoutEffect的区别} useEffect和useLayoutEffect的区别
- 优先使用 useEffect,因为它是异步执行的,不会阻塞渲染
- 会影响到渲染的操作尽量放到 useLayoutEffect中去,避免出现闪烁问题
- useLayoutEffect和componentDidMount是等价的,会同步调用,阻塞渲染
- useLayoutEffect在服务端渲染的时候使用会有一个 warning,因为它可能导致首屏实际内容和服务端渲染出来的内容不一致
diff算法
diff算法即差异查找算法;
传统的diff算法:- 对于Html DOM结构即为tree的差异查找算法;而对于计算两颗树的差异时间复杂度为O(n^3)
react的diff算法:- React采用虚拟DOM技术实现对真实DOM的映射,即React Diff算法的差异查找实质是对两个JavaScript对象的差异查找;
- 基于三个策略:
- Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。(tree diff)
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结(component diff)
- 对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。(element diff)
react 15和16 diff的区别:- React15的虚拟dom是一颗由上至下深度优先遍历的树结构,每一个节点都是虚拟DOM 节点,React16的中是链表形式的虚拟DOM,链表的每一个节点是 Fiber。
- React15的diff阶段是不可中断的递归,React16中的diff阶段更新时是可中断的循环,通过暂停、终止、复用渲染任务(Alternate)从而使得每一个fiber的diff与patch变的可控。
- diff过程于patch的过程从之前的递归树状结构,变成一个循环遍历链表的形式。
- 工作循环(requestIdleCallback)、优先级策略。
diff算法和fiber算法的区别
r e a c t 为 什 么 要 提 出 f i b e r \color{#0000FF}{ react 为什么要提出fiber} react为什么要提出fiber
- react最初的协调机制是Stack reconciler,采用传统的diff算法,即通过递归的方式去进行节点比对,算法复杂度为O(n^3),且不能中断任务,这就会导致如果dom树太大,导致主线程被占用,会出现页面卡顿的现象
f i b e r 是 什 么 \color{#0000FF}{fiber是什么} fiber是什么
- 是对核心算法的一次重新实现,相当于是一个新的任务调和器,是一种工作单元,也是一种虚拟的堆栈帧
f i b e r 能 解 决 什 么 \color{#0000FF}{fiber能解决什么} fiber能解决什么
- 修改了之前的递归形式去计算,采用大循环模式,修改了生命周期,可以中断任务,核心思想是采用异步的方式去解决旧版本同步递归导致的性能问题
- 暂停工作任务,稍后再回来
- 为不同类型的工作分配优先级
- 重用以前未完成的工作
- 如果不需要可以终止工作
f i b e r 是 如 何 工 作 的 \color{#0000FF}{fiber是如何工作的} fiber是如何工作的
- 在render和setState的时候开始更新
- 将创建的更新加入队列,等待调度
- 在requestIdleCallback空闲的时候执行任务
- 从根节点开始遍历Fiber Node,兵器构建WorkInProgress Tree
- 生成effectList
- 根据effectList更新DOM
redux
r
e
d
u
x
的
异
步
中
间
件
\color{#0000FF}{redux的异步中间件}
redux的异步中间件
r
e
d
u
x
的
数
据
流
\color{#0000FF}{redux的数据流}
redux的数据流
react性能优化
性 能 优 化 方 案 \color{#0000FF}{性能优化方案} 性能优化方案
- 使用key
- 使用懒加载
- 使用生产版本和Fragment:Fragment减少不必要的节点生成,也可以使用空标签;生产版本:确保发布的代码时生产模式下的代码
- 类组件使用PureComponent:PurComponent的原理是重新设置了shouldComponentUpdate方法,在该方法中将nextProps和this.props对象浅比较,将nextState和this.state进行浅比较
- 不可变的数据使用immutable库
- 函数式组件使用React.memo避免重复渲染
- 异常捕获边界:将异常组件和正常组件区分开,提高用户的体验
- 长列表优化:只加载可视化范围的数据
r e a c t 体 积 优 化 ( 搭 配 w e b p a c k ) \color{#0000FF}{react体积优化(搭配webpack)} react体积优化(搭配webpack)
- 压缩去掉所有的
console以及copyright,需要在webpack中做如下配置:
new webpack.optimize.UglifyJsPlugin({
output: {
comments: false, // remove all comments
},
compress: {
warnings: false
}
})
- 将react切换到生产版本
new webpack.DefinePlugin({
'process.env': {
NODE_ENV: {
JSON.stringify(process.env.NODE_ENV)
}
}
})
- 分离css
- 安装插件:
npm install extract-text-webpack-plugin --save - 配置:
var ExtractTextPlugin = require('extract-text-webpack-plugin');
...
loaders: [
{
test: /\.css$/,
loader: ExtractTextPlugin.extract("style-loader", "css-loader")
},
{
test: /\.less$/,
loader: ExtractTextPlugin.extract("style-loader", "css-loader!less-loader")
},
...
]
...
plugins: [
...
new ExtractTextPlugin(bundle.css)
]
组 件 懒 加 载 \color{#0000FF}{组件懒加载} 组件懒加载
- 为什么要使用懒加载:解决页面假死状态
- 懒加载的方式:延迟加载或按需加载
- webpack + es6的import:采用的是this.props.children作为回调函数的解决办法
- webpack + es6的import的纯粹高阶函数
- webpack + es6的import + async
- webpack 和 commonJS的require.ensure:按需加载
- react.lazy():React 16.6.0版本发布了React.lazy来实现react组件的懒加载
import React, {lazy, Suspense} from 'react';
const OtherComponent = lazy(90 => import('./otherComponent'));
function MyComponent () {
return (
<Suspense callback={
<div>Loading...</div>
}>
<OtherComponent />
</Suspense>
)
}
// ps: 通过lazy来动态import需要懒加载的组件,import
杂乱笔记
解
释
一
下
受
控
组
件
与
非
受
控
组
件
\color{#0000FF}{解释一下受控组件与非受控组件}
解释一下受控组件与非受控组件
P
u
r
e
C
o
m
p
o
n
e
n
t
、
C
o
m
p
o
n
e
n
t
的
区
别
\color{#0000FF}{PureComponent、Component的区别}
PureComponent、Component的区别
区别:React.PureComponent它用当前与之前 props 和 state 的浅比较覆写了shouldComponentUpdate() 的实现。简单来说,就是PureComponent简单实现了shouldComponentUpdate()的功能;当然,如果你的数据结构比较复杂就不行了
PureComponent缺点
- 可能会因深层的数据不一致而产生错误的否定判断,从而shouldComponentUpdate结果返回false,界面得不到更新。
PureComponent优势
- 不需要开发者自己实现shouldComponentUpdate,就可以进行简单的判断来提升性能。
什 么 是 高 阶 组 件 , 为 什 么 要 用 到 高 阶 组 件 , 高 阶 组 件 的 优 缺 点 \color{#0000FF}{什么是高阶组件,为什么要用到高阶组件,高阶组件的优缺点} 什么是高阶组件,为什么要用到高阶组件,高阶组件的优缺点
高阶组件就是一个函数,且该函数接受一个组件作为参数,并返回一个新的组件;
高阶组件能够提高代码的复用性,减少代码冗余
- 优点:
- 通过传递props去影响内层组件的状态,不直接改变内层组件的状态,降低了耦合度
- 缺点:
- 组件多层嵌套, 增加复杂度与理解成本
- ref隔断, React.forwardRef 来解决
- 高阶组件多层嵌套,相同命名的props会覆盖老属性
- 不清楚props来源与哪个高阶组件
Webpack
w e b p a c k 常 用 的 几 个 对 象 及 解 释 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{webpack常用的几个对象及解释⭐⭐⭐⭐} webpack常用的几个对象及解释⭐⭐⭐⭐
- entry 入口文件
- output 输出文件
- 一般配合node的path模块使用
// 入口文件
entry:"./src/index.js",
output:{
// 输出文件名称
filename:"bundle.js",
// 输出的路径(绝对路径)
path:path.resolve(__dirname,"dist") //利用node模块的path 绝对路径
},
// 设置模式
mode:"development"
- mode 设计模式
- module(loader)
- 里面有一个rules数组对某种格式的文件进行转换处理(转换规则)
- use数组解析顺序是从下到上逆序执行的
module:{
// 对某种格式的文件进行转换处理(转换规则)
rules:[
{
// 用到正则表达式
test:/\.css$/, //后缀名为css格式的文件
use:[
// use数组解析顺序是从下到上逆序执行的
// 先用css-loader 再用style-loader
// 将js的样式内容插入到style标签里
"style-loader",
// 将css文件转换为js
"css-loader"
]
}
]
}
// -----------------------------------------------------vue的
module.exports={
module:{
rules:[
{
test: /\.vue$/,
use:["vue-loader"]
}
]
}
}
- plugin:插件配置
const uglifyJsPlugin = reqiure('uglifyjs-webpack-plugin')
module.exports={
plugin:[
new uglifyJsPlugin() //丑化
]
}
- devServer:热更新
devServer:{
// 项目构建路径
contentBase:path.resolve(__dirname,"dist"),
// 启动gzip亚索
compress:true,
// 设置端口号
port:2020,
// 自动打开浏览器:否
open:false,
//页面实时刷新(实时监听)
inline:true
}
- resolve:配置路径规则
- alias 别名
module.exports= {
resolve:{
//如果导入的时候不想写后缀名可以在resolve中定义extensions
extensions:['.js','.css','.vue']
//alias:别名
alias:{
//导入以vue结尾的文件时,会去寻找vue.esm.js文件
'vue$':"vue/dist/vue.esm.js"
}
}
}
- babel(ES6转ES5):下载插件babel-loader,在module(loader)中配置
l o a d e r 和 p l u g i n 的 区 别 是 什 么 ? ⭐ ⭐ ⭐ \color{#0000FF}{loader和plugin的区别是什么?⭐⭐⭐} loader和plugin的区别是什么?⭐⭐⭐
- loader
- loader是用来解析非js文件的,因为Webpack原生只能解析js文件,如果想把那些文件一并打包的话,就需要用到loader,loader使webpack具有了解析非js文件的能力
- plugin
- 用来给webpack扩展功能的,可以加载许多插件
本 地 如 何 劫 持 前 端 j s / c s s 等 资 源 请 求 到 w e b p a c k s e r v e r 上 \color{#0000FF}{本地如何劫持前端js/css等资源请求到webpack server上} 本地如何劫持前端js/css等资源请求到webpackserver上
CSS/HTML
f l e x 布 局 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{flex布局⭐⭐⭐⭐⭐} flex布局⭐⭐⭐⭐⭐
g r i d 布 局 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{grid布局⭐⭐⭐⭐} grid布局⭐⭐⭐⭐
常 见 的 行 内 元 素 和 块 级 元 素 都 有 哪 些 ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{常见的行内元素和块级元素都有哪些?⭐⭐⭐⭐⭐} 常见的行内元素和块级元素都有哪些?⭐⭐⭐⭐⭐
- 行内元素 inline:不能设置宽高,多个元素共享一行,占满的时候会换行
- span、input、img、textarea、label、select
- 块级元素block:可以设置宽高,一个元素占满一整行
- p、h1/h2/h3/h4/h5、div、ul、li、table
- inline-block:可以设置宽高,多个元素共享一行,占满的时候会换行
如 何 对 网 站 的 文 件 和 资 源 进 行 优 化 ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{如何对网站的文件和资源进行优化? ⭐⭐⭐⭐} 如何对网站的文件和资源进行优化?⭐⭐⭐⭐
- 文件合并
- 文件最小化/文件压缩
- 使用cdn托管
- 缓存的使用
w e b 前 端 开 发 , 如 何 提 高 页 面 性 能 优 化 ? ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{web前端开发,如何提高页面性能优化? ⭐⭐⭐⭐} web前端开发,如何提高页面性能优化?⭐⭐⭐⭐
- 内容方面:
- 减少 HTTP 请求 (Make Fewer HTTP Requests)
- 减少 DOM 元素数量 (Reduce the Number of DOM Elements)
- 使得 Ajax 可缓存 (Make Ajax Cacheable)
- 针对CSS:
- 把 CSS 放到代码页上端 (Put Stylesheets at the Top)
- 从页面中剥离 JavaScript 与 CSS (Make JavaScript and CSS External)
- 精简 JavaScript 与 CSS (Minify JavaScript and CSS)
- 避免 CSS 表达式 (Avoid CSS Expressions)
- 针对JavaScript :
- 脚本放到 HTML 代码页底部 (Put Scripts at the Bottom)
- 从页面中剥离 JavaScript 与 CSS (Make JavaScript and CSS External)
- 精简 JavaScript 与 CSS (Minify JavaScript and CSS)
- 移除重复脚本 (Remove Duplicate Scripts)
- 面向图片(Image):
- 优化图片
- 不要在 HTML 中使用缩放图片
- 使用恰当的图片格式
- 使用 CSS Sprites 技巧对图片优化
请 说 明 p x , e m , r e m , v w , v h , r p x 等 单 位 的 特 性 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{请说明px,em,rem,vw,vh,rpx等单位的特性⭐⭐⭐⭐⭐} 请说明px,em,rem,vw,vh,rpx等单位的特性⭐⭐⭐⭐⭐
- px:像素
- em:当前元素的字体大小
- rem:根元素字体大小
- vw:100vw是总宽度
- vh:100vh是总高度
- rpx:750rpx是总宽度
常 见 的 替 换 元 素 和 非 替 换 元 素 ? ⭐ ⭐ \color{#0000FF}{常见的替换元素和非替换元素?⭐⭐} 常见的替换元素和非替换元素?⭐⭐
- 替换元素:是指若标签的属性可以改变标签的显示方式就是替换元素,比如input的type属性不同会有不同的展现,img的src等
- img、input、iframe
- 非替换元素
- div、span、p
f i r s t − o f − t y p e 和 f i r s t − c h i l d 有 什 么 区 别 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{first-of-type和first-child有什么区别⭐⭐⭐⭐} first−of−type和first−child有什么区别⭐⭐⭐⭐
- first-of-type:匹配的是从第一个子元素开始数,匹配到的那个的第一个元素
- first-child:必须是第一个子元素
d o c t y p e 标 签 和 m e t a 标 签 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{doctype标签和meta标签⭐⭐⭐⭐⭐} doctype标签和meta标签⭐⭐⭐⭐⭐
- doctype
- 告诉浏览器以什么样的文档规范解析文档
- 标准模式和兼容模式
- 标准模式 ->正常,排版和js运作模式都是以最高标准运行
- 兼容模式->非正常
s c r i p t 标 签 中 d e f e r 和 a s y n c 都 表 示 了 什 么 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{script标签中defer和async都表示了什么⭐⭐⭐⭐⭐} script标签中defer和async都表示了什么⭐⭐⭐⭐⭐
众所周知script会阻塞页面的加载,如果我们要是引用外部js,假如这个外部js请求很久的话就难免出现空白页问题,好在官方为我们提供了defer和async
- defer
<script src="d.js" defer></script>
<script src="e.js" defer></script>
- 不会阻止页面解析,并行下载对应的js文件
- 下载完之后不会执行
- 等所有其他脚本加载完之后,在DOMContentLoaded事件之前执行对应d.js、e.js
- async
<script src="b.js" async></script>
<script src="c.js" async></script>
- 不会阻止DOM解析,并行下载对应的js文件
- 下载完之后立即执行
- 补充,DOMContentLoaded事件
- 是等HTML文档完全加载完和解析完之后运行的事件
- 在load事件之前。
- 不用等样式表、图像等完成加载
什 么 是 B F C ? ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{什么是BFC?⭐⭐⭐⭐⭐} 什么是BFC?⭐⭐⭐⭐⭐
BFC是一个独立渲染区域,它丝毫不会影响到外部元素
- BFC特性
- 同一个BFC下margin会重叠
- 计算BFC高度时会算上浮动元素
- BFC不会影响到外部元素
- BFC内部元素是垂直排列的
- BFC区域不会与float元素重叠
- 如何创建BFC
- position设为absolute或者fixed
- float不为none
- overflow设置为hidden
- display设置为inline-block或者inline-table或flex
如 何 清 除 浮 动 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{如何清除浮动⭐⭐⭐⭐⭐} 如何清除浮动⭐⭐⭐⭐⭐
- 额外标签clear:both
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
.fahter{
width: 400px;
border: 1px solid deeppink;
}
.big{
width: 200px;
height: 200px;
background: darkorange;
float: left;
}
.small{
width: 120px;
height: 120px;
background: darkmagenta;
float: left;
}
.clear{
clear:both;
}
</style>
</head>
<body>
<div class="fahter">
<div class="big">big</div>
<div class="small">small</div>
<div class="clear">额外标签法</div>
</div>
</body>
- 利用BFC
overflow:hidden
.fahter{
width: 400px;
border: 1px solid deeppink;
overflow: hidden;
}
- 使用after(推荐)
<style>
.clearfix:after{/*伪元素是行内元素 正常浏览器清除浮动方法*/
content: "";
display: block;
height: 0;
clear:both;
visibility: hidden;
}
.clearfix{
*zoom: 1;/*ie6清除浮动的方式 *号只有IE6-IE7执行,其他浏览器不执行*/
}
</style>
<body>
<div class="fahter clearfix">
<div class="big">big</div>
<div class="small">small</div>
<!--<div class="clear">额外标签法</div>-->
</div>
什 么 是 D O M 事 件 流 ? 什 么 是 事 件 委 托 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{什么是DOM事件流?什么是事件委托⭐⭐⭐⭐⭐} 什么是DOM事件流?什么是事件委托⭐⭐⭐⭐⭐
- DOM事件流
- 分为三个阶段
- 捕获阶段
- 目标阶段
- 冒泡阶段
- 在addeventListener()的第三个参数(useCapture)设为true,就会在捕获阶段运行,默认是false冒泡
- 分为三个阶段
- 事件委托
- 利用冒泡原理(子向父一层层穿透),把事件绑定到父元素中,以实现事件委托
l i n k 标 签 和 i m p o r t 标 签 的 区 别 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{link标签和import标签的区别⭐⭐⭐⭐} link标签和import标签的区别⭐⭐⭐⭐
- link属于html,而@import属于css
- 页面被加载时,link会同时被加载,而@import引用的css会等到页面加载结束后加载。
- link是html标签,因此没有兼容性,而@import只有IE5以上才能识别。
- link方式样式的权重高于@import的。
盒 模 型 \color{#0000FF}{盒模型} 盒模型
- 标准的盒子模型:宽度=内容的宽度(content)+border+padding+margin
- 低版本IE盒子模型:宽度=内容宽度(content+border+padding)+margin
f l e x 布 局 , 垂 直 布 局 \color{#0000FF}{flex布局,垂直布局} flex布局,垂直布局
dislpay: flex;
justify-content: center;
align-items: center;
文 字 超 出 省 略 号 的 实 现 \color{#0000FF}{文字超出省略号的实现} 文字超出省略号的实现
.content {
width: 300px;
/* 强制不换行 */
white-space: nowrap;
/* 文字用省略号代替超出的部分 */
text-overflow: ellipsis;
/* 匀速溢出内容,隐藏 */
overflow: hidden;
}
实 现 三 行 后 显 示 省 略 号 \color{#0000FF}{实现三行后显示省略号} 实现三行后显示省略号
- css:
-webkit-line-clamp: 3 - js: 思路是设定容器高度,当判断容器高度出现滚动条的时候,截取容器内的内容,并将后面的内容替换为省略号
元 素 垂 直 居 中 的 实 现 方 式 \color{#0000FF}{元素垂直居中的实现方式} 元素垂直居中的实现方式
- 居中元素指定高宽(height: 200px, width: 200px)
- absolute+margin
position: absolute; top: 50%; left: 50% margin-top: -100px; margin-left: -100px;- absolute + calc
position: absolute; top: calc(50% - 100px); left: calc(50% - 100px);- absolute + margin: auto
position: absolute; top: 0; left: 0; right: 0; bottom: 0; margin: auto; - 居中元素不定高
- absolute + transform
position: absolute; top: 50%; left: 50%; transform: translate(-50%, -50%);- inlineHeight
display: inline-block; vertical-middle: middle; line-height: initial; text-align: center;- flex
display: flex; justify-content: center; align-items: center- grid
display: grid; align-slef: center; justify-self: center;- table
- css-table
算法
冒 泡 算 法 排 序 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{冒泡算法排序⭐⭐⭐⭐⭐} 冒泡算法排序⭐⭐⭐⭐⭐
// 冒泡排序
/* 1.比较相邻的两个元素,如果前一个比后一个大,则交换位置。
2.第一轮的时候最后一个元素应该是最大的一个。
3.按照步骤一的方法进行相邻两个元素的比较,这个时候由于最后一个元素已经是最大的了,所以最后一个元素不用比较。 */
function bubbleSort(arr) {
for (var i = 0; i < arr.length; i++) {
for (var j = 0; j < arr.length - 1 - i; j++) { // 改进的冒泡排序1
// for (var j = 0; j < arr.length; j++) { // 原始的冒泡排序
if (arr[j] > arr[j + 1]) {
var temp = arr[j]
arr[j] = arr[j + 1]
arr[j + 1] = temp
}
}
}
}
var Arr = [3, 5, 74, 64, 64, 3, 1, 8, 3, 49, 16, 161, 9, 4]
console.log(Arr, "before");
bubbleSort(Arr)
console.log(Arr, "after");
// 再次优化后的冒泡排序
//标记变量声明时状态为true,进行循环后,标记变量初始化为false状态。当后边的项两两进行比较时,发生交换则将标记变量状态更正为true,如果自始至终标记变量的状态都没有更正为true,说明为有序,则在外层循环的终止判断语句中退出。
//优化的关键在于:在变量i的for循环中,增加了对flag是否为true的判断。通过这种改进,可以避免在有序的情况下进行无意义的循环判断。
function BubbleSort(arr){
var i,j,temp;
var flag=true; //flag进行标记
for(i=0;i<arr.length-1&&flag;i++){ //若flag为false则退出循环
flag=false; //初始化为false
for(j=arr.length-1;j>i;j--){
if(arr[j]<arr[j-1]){ //j为从前往后循环
temp=arr[j-1];
arr[j-1]=arr[j];
arr[j]=temp;
flag=true; //如果有数据交换则为true
}
}
}
return arr;
}
BubbleSort(Arr);
快 速 排 序 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{快速排序⭐⭐⭐⭐⭐} 快速排序⭐⭐⭐⭐⭐
/*
快速排序是对冒泡排序的一种改进,第一趟排序时将数据分成两部分,一部分比另一部分的所有数据都要小。
然后递归调用,在两边都实行快速排序。
*/
// 原始的快速排序
function quickSort(arr) {
if (arr.length <= 1) {
return arr
}
var middle = Math.floor(arr.length / 2)
var middleData = arr.splice(middle, 1)[0]
var left = []
var right = []
for (var i = 0; i < arr.length; i++) {
if (arr[i] < middleData) {
left.push(arr[i])
} else {
right.push(arr[i])
}
}
return quickSort(left).concat([middleData], quickSort(right))
}
var Arr = [3, 5, 74, 64, 64, 3, 1, 8, 3, 49, 16, 161, 9, 4]
console.log(Arr, "before");
var newArr = quickSort(Arr)
console.log(newArr, "after");
// 改进的快速排序
// 1、用下标取基数,只有一个赋值操作,跟快;
//2、原地交换,不需要新建多余的数组容器存储被划分的数据,节省存储;
var devideArr = function (array, start, end) {
if(start >= end) return array;
var baseIndex = Math.floor((start + end) / 2), // 基数索引
i = start,
j = end;
while (i <= j) {
while (array[i] < array[baseIndex]) {
i++;
}
while (array[j] > array[baseIndex]) {
j--;
}
if(i <= j) {
var temp = array[i];
array[i] = array[j];
array[j] = temp;
i++;
j--;
}
}
return i;
}
var quickSort = function (array, start, end) {
if(array.length < 1) {
return array;
}
var index = devideArr(array, start, end);
if(start < index -1) {
quickSort(array, start, index - 1);
}
if(end > index) {
quickSort(array, index, end);
}
return array;
}
插 入 排 序 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{插入排序⭐⭐⭐⭐} 插入排序⭐⭐⭐⭐
function insertSort(arr) {
// 默认第一个排好序了
for (var i = 1; i < arr.length; i++) {
// 如果后面的小于前面的直接把后面的插到前边正确的位置
if (arr[i] < arr[i - 1]) {
var el = arr[i]
arr[i] = arr[i - 1]
var j = i - 1
while (j >= 0 && arr[j] > el) {
arr[j+1] = arr[j]
j--
}
arr[j+1] = el
}
}
}
var Arr = [3, 5, 74, 64, 64, 3, 1, 8, 3, 49, 16, 161, 9, 4]
console.log(Arr, "before");
insertSort(Arr)
console.log(Arr, "after");
是 否 回 文 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{是否回文⭐⭐⭐⭐⭐} 是否回文⭐⭐⭐⭐⭐
function isHuiWen(str) {
return str == str.split("").reverse().join("")
}
console.log(isHuiWen("mnm"));
正 则 表 达 式 , 千 分 位 分 隔 符 ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{正则表达式,千分位分隔符⭐⭐⭐⭐} 正则表达式,千分位分隔符⭐⭐⭐⭐
function thousand(num) {
return (num+"").replace(/\d(?=(\d{3})+$)/g, "$&,")
}
console.log(thousand(123456789));
斐 波 那 契 数 列 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{斐波那契数列⭐⭐⭐⭐⭐} 斐波那契数列⭐⭐⭐⭐⭐
// num1前一项
// num2当前项
function fb(n, num1 = 1, num2 = 1) {
if(n == 0) return 0
if (n <= 2) {
return num2
} else {
return fb(n - 1, num2, num1 + num2)
}
}
// F(0)=1,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n ≥ 2,n ∈ N*)
function fb1(n) {
if (n == 0) return 0
if (n <= 2) {
return 1;
} else {
return fb1(n - 1) + fb1(n - 2);
}
}
数 组 去 重 的 方 式 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{数组去重的方式⭐⭐⭐⭐⭐} 数组去重的方式⭐⭐⭐⭐⭐
var arr = [1, 2, 1, 1, 1, 2, 3, 3, 3, 2]
// 最low1
let newArr2 = []
for (let i = 0; i < arr.length; i++) {
if (!newArr2.includes(arr[i])) {
newArr2.push(arr[i])
}
}
console.log(newArr2);
// 最low2
let arr2 = [1, 2, 1, 1, 1, 2, 3, 3, 3, 2]
for (let i = 0; i < arr2.length; i++) {
var item = arr2[i]
for (let j = i + 1; j < arr2.length; j++) {
var compare = arr2[j];
if (compare === item) {
arr2.splice(j, 1)
j--
}
}
}
console.log(arr2);
// 基于对象去重
let arr3 = [1, 2, 1, 1, 1, 2, 3, 3, 3, 2]
let obj = {}
for (let i = 0; i < arr3.length; i++) {
let item = arr3[i]
if (obj[item]) {
arr3[i] = arr3[arr3.length - 1]
arr3.length--
i--
continue;
}
obj[item] = item
}
console.log(arr3);
console.log(obj);
// 利用Set
let newArr1 = new Set(arr)
console.log([...newArr1]);
let arr4 = [1, 2, 1, 1, 1, 2, 3, 3, 3, 2]
//利用reduce
newArr4 = arr4.reduce((prev, curr) => prev.includes(curr)? prev : [...prev,curr],[])
console.log(newArr4);
console.log(document);
git
g i t 的 常 用 命 令 ⭐ ⭐ ⭐ ⭐ ⭐ \color{#0000FF}{git的常用命令⭐⭐⭐⭐⭐} git的常用命令⭐⭐⭐⭐⭐
- commit之后撤回
git reset soft HEAD^
- 回退及日志查看
git reset --hard commitId 强制回退到某个提交节点git log 查看所有提交日志
- 分支
git branch xx 创建分支git checkout xx切换分支git merge branch 合并分支
- 添加
git add .git pushgit commit -m
- 暂存
git stash save "" 暂存git stash pop 提取暂存
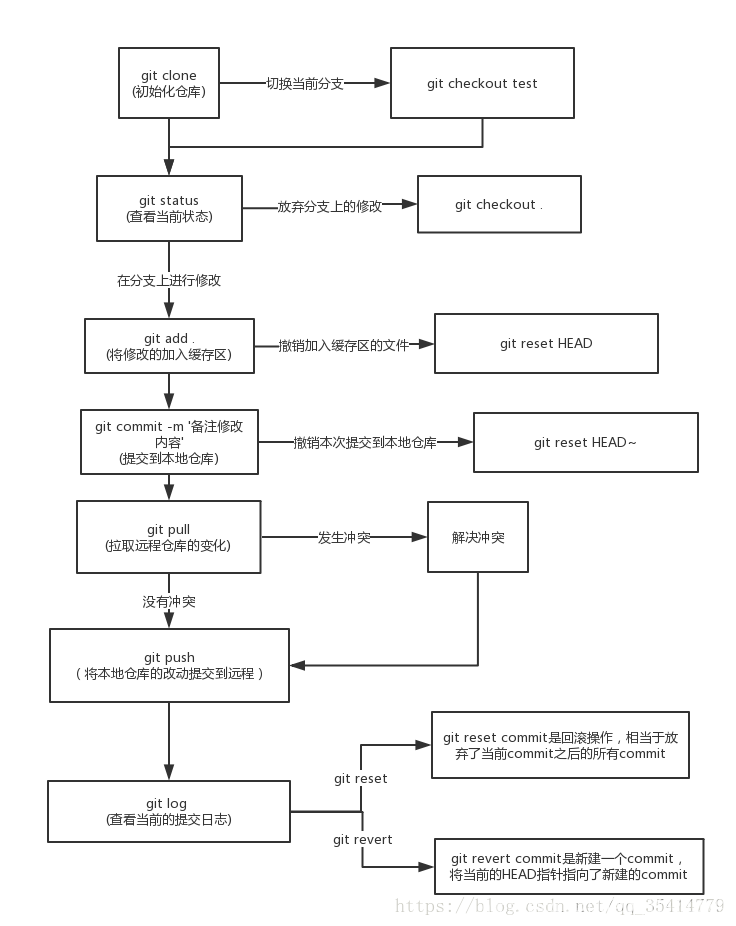

















 5549
5549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









