






 本文详细介绍了SQL的基础操作,包括SELECT查询、WHERE和LIKE子句、DISTINCT与GROUP BY、ORDER BY与LIMIT、JOINs、NULL处理、统计与表达式、数据插入、更新和删除,以及表的创建和修改。
本文详细介绍了SQL的基础操作,包括SELECT查询、WHERE和LIKE子句、DISTINCT与GROUP BY、ORDER BY与LIMIT、JOINs、NULL处理、统计与表达式、数据插入、更新和删除,以及表的创建和修改。
1 SELECT 查询 101
SELECT 语句, 通常又称为 查询 (queries), 正如其名, SELECT 可以用来从数据库中取出数据
#Select 查询某些属性列(specific columns)的语法
SELECT column(列名), another_column, … FROM mytable(表名);
#Select 查询所有列
SELECT * FROM mytable(表名);
2 条件查询 (constraints)
SELECT查询的 WHERE 子句
—— 一个查询的 WHERE子句用来描述哪些行应该进入结果
条件查询语法
SELECT column, another_column, …FROM mytable WHERE condition
AND/OR another_condition
AND/OR …;
注:这里的 condition 都是描述属性列的,具体会在下面的表格体现。
【记得加双引号 没有多空格
```sql
where director = "John Lasseter"

列表就是第2位,第4位,第6位
【偶数】
```sql
WHERE Year%2=0
LIKE(模糊查询) 和 %(通配符)
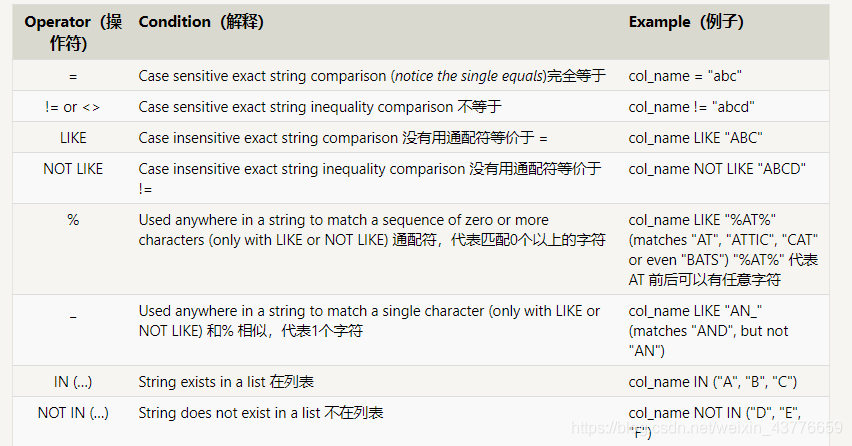
在字符串表达式中的字符串需要用引号 " 包含,如果不用引号,SQL会认为是一个属性列的名字,如:col_name = color 表示 col_name和color两个属性一样的行 col_name = “color” 表示 col_name 属性为字符串 "color"的行.
【复杂条件】找到所有Toy Story系列电影
SELECT * FROM movies where title LIKE "%toy story%"
【复杂条件】找到所有John Lasseter导演的电影 ✓
SELECT * FROM movies where director LIKE "%john lasseter%"
3 查询结果Filtering过滤 和 sorting排序
Movies表来说,可能很多电影都是同一年Year发布的,如果你想要按年份排重,一年只能出现一部电影到结果中, 你可以用 DISTINCT 关键字来指定某个或某些属性列唯一返回。写作:DISTINCT Year
选取出唯一的结果的语法 DISTINCT 、GROUP BY
SELECT DISTINCT column, another_column, …FROM mytable WHERE condition(s);
distinct 要放在最前面
因为 DISTINCT 语法会直接删除重复的行
GROUP BY 也会返回唯一的行,不过可以对具有相同的 属性值的行做一些统计计算,比如:求和.
【结果排序】按导演名排重列出所有电影(只显示导演),并按导演名正序排列
SELECT distinct director
FROM movies
order by director asc
ORDER BY col_name 排序
让结果按一个或多个属性列做排序
#结果排序(ordered results)
SELECT column, another_column, …FROM mytable
WHERE condition(s)
ORDER BY column ASC/DESC;
通过Limit选取部分“行”结果
LIMIT 和 OFFSET 子句通常和ORDER BY 语句一起使用,
当我们对整个结果集排序之后,我们可以 用 OFFSET来指定从哪一行开始返回。LIMIT来指定只返回多少行结果 ,
#limited查询
SELECT column, another_column, …
FROM mytable
WHERE condition(s)
ORDER BY column ASC/DESC
LIMIT num_limit OFFSET num_offset;
LIMIT和OFFSET一般在SQL的其他部分都执行完之后,再执行。 具体有一个章节来说明SQL中不同子句的执行顺序问题 Lesson 12: Order of execution
【结果排序】列出按上映年份最新上线的4部电影 ✓
SELECT *
FROM movies
order by year desc
limit 4
【前5部电影之后的5部电影】:offset 5
【结果排序】如果按片长排列,John Lasseter导演导过片长第3长的电影是哪部,列出名字即可 ✓
--请输入sql
SELECT title FROM movies where director like "John%"
order by Length_minutes desc
limit 1 offset 2
4 JOINs进行多表联合查询
主键(primary key), 一般关系数据表中,都会有一个属性列设置为 主键(primary key)。
主键是唯一标识一条数据的,不会重复,ID、字符串,hash值等只要是每条数据是唯一的也可以设为主键.
把两个表中具有相同 主键ID的数据连接起来(因为一个ID可以简要的识别一条数据,所以连接之后还是表达的同一条数据)(
用INNER JOIN 连接表的语法
SELECT column, another_table_column, …
FROM mytable (主表)
INNER JOIN another_table (要连接的表)
ON mytable.id = another_table.id (想象一下刚才讲的主键连接,两个相同的连成1条)
WHERE condition(s)
ORDER BY column, … ASC/DESC
LIMIT num_limit OFFSET num_offset;
通过ID互相找不到的数据将会舍弃
外连接(OUTER JOINs)用LEFT/RIGHT/FULL JOINs 做多表查询
SELECT column, another_column, …
FROM mytable
INNER/LEFT/RIGHT/FULL JOIN another_table
ON mytable.id = another_table.matching_id
WHERE condition(s)
ORDER BY column, … ASC/DESC
LIMIT num_limit OFFSET num_offset;
在表A 连接 B, LEFT JOIN保留A的所有行,不管有没有能匹配上B
反过来 RIGHT JOIN则保留所有B里的行。
最后FULL JOIN 不管有没有匹配上,同时保留A和B里的所有行
【复习】找到所有办公室里的所有角色(包含没有雇员的),并做唯一输出(DISTINCT)
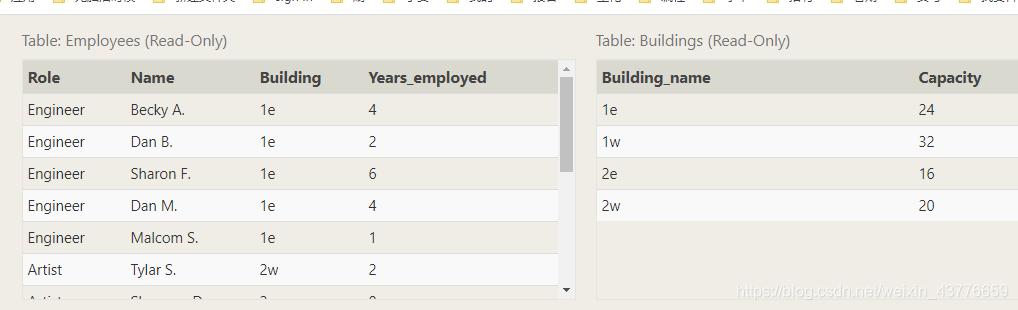
右边的表格才是主表,
LEFT JOIN Employees(次表)
ON Buildings.Building_name = Employees.Building
5 特殊关键字 NULLs
outer-joining 多表连接,A和B有数据差异时,必须用 NULL 来填充。这种情况,可以用IS NULL和 IS NOT NULL 来选在某个字段是否等于 NULL.
在查询条件中处理 NULL
SELECT column, another_column, …
FROM mytable
WHERE column IS/IS NOT NULL
AND/OR another_condition
AND/OR …;
6 在查询中使用表达式:求和,计数等等
AS关键字来取一个别名.
SELECT col_expression AS expr_description, …
FROM mytable;
SELECT column AS better_column_name, …
FROM a_long_widgets_table_name AS mywidgets
INNER JOIN widget_sales
ON mywidgets.id = widget_sales.widget_id;
取补集:0,1
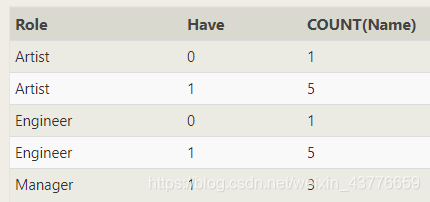
【难题】按角色分组算出每个角色按有办公室和没办公室的统计人数(列出角色,数量,有无办公室,注意一个角色如果部分有办公室,部分没有需分开统计)
只能显示子集和全集,无法用减法显示补集:
select role, count(building)as y,count(name)as A from employees
group by role

正解:
SELECT Role,CASE when Building is NOT NULL
THEN '1' ELSE '0' END AS Have,
COUNT(Name)
FROM Employees
GROUP BY Role,Have;
7 在查询中进行统计
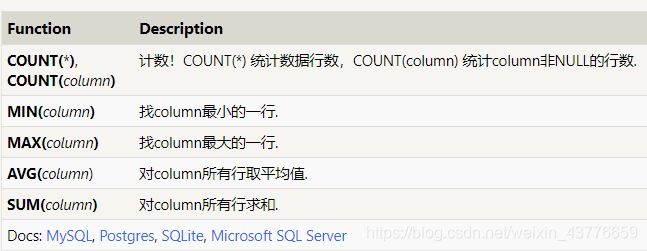
(b.Domestic_sales+b.International_sales)只是加总了A导演的一部戏而已,要知道A导演全部戏的总额,要SUM(b.Domestic_sales+b.International_sales)
1、分组统计 GROUP BY
数据库是先对数据做WHERE,然后对结果做分组
可以按某个col_name对数据进行分组,如:GROUP BY Year指对数据按年份分组, 相同年份的分到一个组里。
如果把统计函数和GROUP BY结合,那统计结果就是对分组内的数据统计了.
用分组的方式统计
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …
FROM mytable
WHERE constraint_expression
GROUP BY column;
【找出就职年份最高的雇员(列出雇员名字+年份】
SELECT Name, MAX(Years_employed) FROM Employees;
【按角色(Role)统计一下每个角色的平均就职年份】
SELECT Role,AVG(Years_employed)
FROM Employees GROUP BY Role;
【分组】按角色统计一下每个角色的雇员数量
–请输入sql
SELECT role, count() FROM employees
group by role
【每栋办公室按人数排名,不要统计无办公室的雇员】——计数
SELECT Building,COUNT(*)
FROM Employees
WHERE Building GROUP BY Building;
【就职1,3,5,7年的人分别占总人数的百分比率是多少(给出年份和比率"50%" 记为 50)】
SELECT Years_employed,count()*100 /
(SELECT count(Name) FROM Employees) as Ratio
FROM employees
WHERE Years_employed in(1,3,5,7)
GROUP BY Years_employed
没有分组!【分组】算出Engineer角色的就职年份总计
–请输入sql
SELECT SUM(Years_employed) FROM employees
WHERE Role=‘Engineer’
2、分组完再筛选 HAVING
SELECT group_by_column, AGG_FUNC(column_expression) AS aggregate_result_alias, …
FROM mytable
WHERE condition
GROUP BY column
HAVING group_condition;
8 查询执行顺序
-
FROM 和 JOINs
FROM 或 JOIN会第一个执行,确定一个整体的数据范围. 如果要JOIN不同表,可能会生成一个临时Table来用于 下面的过程。总之第一步可以简单理解为确定一个数据源表(含临时表) -
WHERE
我们确定了数据来源 WHERE 语句就将在这个数据源中按要求进行数据筛选,并丢弃不符合要求的数据行,所有的筛选col属性 只能来自FROM圈定的表. AS别名还不能在这个阶段使用,因为可能别名是一个还没执行的表达式 -
GROUP BY
如果你用了 GROUP BY 分组,那GROUP BY 将对之前的数据进行分组,统计等,并将是结果集缩小为分组数.这意味着 其他的数据在分组后丢弃. -
HAVING
如果你用了 GROUP BY 分组, HAVING 会在分组完成后对结果集再次筛选。AS别名也不能在这个阶段使用. -
SELECT
确定结果之后,SELECT用来对结果col简单筛选或计算,决定输出什么数据.
???先select再group才有反应 -
DISTINCT
如果数据行有重复DISTINCT 将负责排重. -
ORDER BY
在结果集确定的情况下,ORDER BY 对结果做排序。因为SELECT中的表达式已经执行完了。此时可以用AS别名. -
LIMIT / OFFSET
最后 LIMIT 和 OFFSET 从排序的结果中截取部分数据.
9 加数据:Insert into 表 values 新
Insert statement with values for all columns
INSERT INTO mytable
VALUES (value_or_expr, another_value_or_expr, …),
(value_or_expr_2, another_value_or_expr_2, …),
…;
字符串的内容记得加""!!!!!!!
Insert statement with specific columns
INSERT INTO mytable
(column, another_column, …) --注意这行!
VALUES (value_or_expr, another_value_or_expr, …),
(value_or_expr_2, another_value_or_expr_2, …),
…;
Example Insert statement with expressions
INSERT INTO boxoffice
(movie_id, rating, sales_in_millions)
VALUES (1, 9.9, 283742034 / 1000000);
10 更新数据:update 表名 set 列的新名
Update statement with values
UPDATE mytable
SET column列的新名 = value_or_expr,
other_column = another_value_or_expr,
…
WHERE 条件,比如id = 2
11删除行:delete from表 where
Delete statement with condition
DELETE FROM mytable
WHERE condition;
12新建表格:CREATE TABLE IF NOT EXISTS
Create table statement w/ optional table constraint and default value
CREATE TABLE IF NOT EXISTS mytable (
column名 DataType TableConstraint DEFAULT default_value,
another_column DataType TableConstraint DEFAULT default_value,
…
);
例如:
Movies table schema
CREATE TABLE movies (
id INTEGER PRIMARY KEY,
title TEXT,
director TEXT,
year INTEGER,
length_minutes INTEGER
);
数据类型DataType
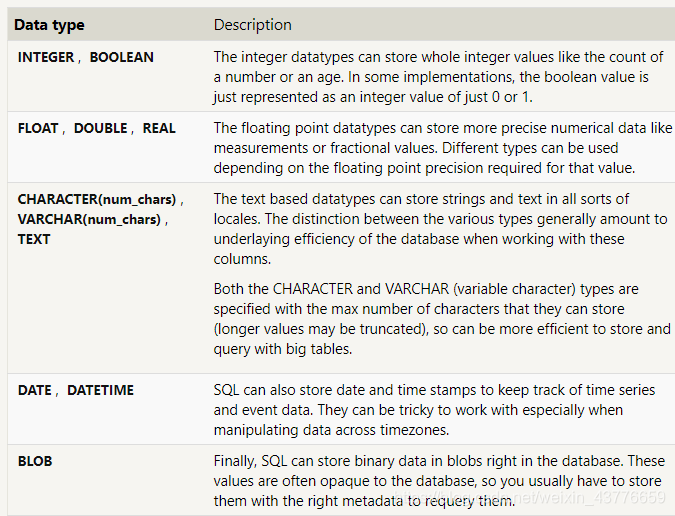
表格系统规定TableConstraint

13变更表格:ALTER TABLE 表名
加列 ADD
ALTER TABLE mytable
ADD column DataType OptionalTableConstraint
DEFAULT default_value;
减列 DROP
ALTER TABLE mytable
DROP column_to_be_deleted
表格重命名RENAME TO
ALTER TABLE mytable
RENAME TO new_table_name;
14删除表格:DROP TABLE
DROP TABLE IF EXISTS mytable;

















 2120
2120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









