







 本文介绍了使用Chrome开发者工具分析网络请求,理解Headers信息,包括General、Response Headers、Request Headers和Query String Parameters。接着讨论了Python的Urllib库在爬网页时的请求头设置和Post请求。还探讨了Scrapy框架中设置User-Agent以伪装浏览器,以及处理证书验证的方法。同时,分享了爬虫获取和解析网页内容的步骤,以及解决数据间隔问题的方法。
本文介绍了使用Chrome开发者工具分析网络请求,理解Headers信息,包括General、Response Headers、Request Headers和Query String Parameters。接着讨论了Python的Urllib库在爬网页时的请求头设置和Post请求。还探讨了Scrapy框架中设置User-Agent以伪装浏览器,以及处理证书验证的方法。同时,分享了爬虫获取和解析网页内容的步骤,以及解决数据间隔问题的方法。
chrome相关知识
elements
区域1显示整个网页的HTML信息,单击选中某一行内容的时候,区域2的Styles标签会显示当前单击选中内容的CSS样式,并可对元素的CSS进行查看与编辑修改。Computed显示当前选中的边距属性、边框属性,用图像显示一个整体效果。Event Listeners是整个网页事件触发的JavaScript通过单击Event Listeners下的某个JavaScript会自动跳转到Sources标签,显示当前JavaScript的源码,这个功能可快速找到JavaScript代码所在的位置,对分析JavaScript起到快速定位作用。
Network标签
主要包括以下5个区域。● Controls:控制Network的外观和功能。● Filters:控制Requests Table具体显示哪些内容。[插图] All:返回当前页面全部加载的信息,就是一个网页全部所需要的代码、图片等请求。[插图] XHR:筛选Ajax的请求链接信息,前面讲过Ajax核心对象XMLHTTPRequest, XHR取于XMLHTTPRequest的缩写。[插图] JS:主要筛选JavaScript文件。[插图] CSS:主要是CSS样式内容。[插图] Img:是网页加载的图片,爬取图片的URL都可以在这里找到。[插图] Media:是网页加载的媒体文件,如MP3、RMVB等音频视频文件资源。[插图] Doc:是HTML文件,主要用于响应当前URL的网页内容。● Overview:显示获取到请求的时间轴信息,主要是对每个请求信息在服务器的响应时间进行记录。这个主要是为网站开发优化方面提供数据参考,这里不做详细介绍。● Requests Table:按前后顺序显示所有捕捉的请求信息,单击请求信息可以查看该详细信息。● Summary:显示总的请求数、数据传输量、加载时间信息。
Requests Table
每条请求信息划分为以下5个标签。● Headers:该请求的HTTP头信息。● Preview:根据所选择的请求类型(JSON、图片、文本)显示相应的预览。● Response:显示HTTP的Response信息。● Cookies:显示HTTP的Request和Response过程中的Cookies信息。● Timing:显示请求在整个生命周期中各部分花费的时间。
Headers
标签划分为以下4部分。
● General:记录请求链接、请求方式和请求状态码。
● Response Headers:
服务器端的响应头,其参数说明如下。[插图] Cache-Control:指定缓存机制,优先级大于Last-Modified。[插图] Connection:包含很多标签列表,其中最常见的是Keep-Alive和Close,分别用于向服务器请求保持TCP连接和断开TCP连接。[插图] Content-Encoding:服务器通过这个头告诉浏览器数据的压缩格式。[插图] Content-Length:服务器通过这个头告诉浏览器回送数据的长度。[插图] Content-Type:服务器通过这个头告诉浏览器回送数据的类型。[插图] Date:当前时间值。[插图] Keep-Alive:在Connection为Keep-Alive时,该字段才有用,用来说明服务器估计保留连接的时间和允许后续几个请求复用这个保持着的连接。[插图] Server:服务器通过这个头告诉浏览器服务器的类型。[插图] Vary:明确告知缓存服务器按照Accept-Encoding字段的内容分别缓存不同的版本。
● Request Headers:
用户的请求头。其参数说明如下。[插图] Accept:告诉服务器客户端支持的数据类型。[插图] Accept-Encoding:告诉服务器客户端支持的数据压缩格式。[插图] Accept-Charset:可接受的内容编码UTF-8。[插图] Cache-Control:缓存控制,服务器控制浏览器要不要缓存数据。[插图] Connection:处理完这次请求后,是断开连接还是保持连接。[插图] Cookie:客户可通过Cookie向服务器发送数据,让服务器识别不同的客户端。
[插图] Host:访问的主机名。[插图] Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面,当浏览器向Web服务器发送请求的时候,一般会带上Referer,告诉服务器请求是从哪个页面URL过来的,服务器借此可以获得一些信息用于处理。[插图] User-Agent:中文名为用户代理,简称UA,是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
● Query String Parameters:
请求参数。主要是将参数按照一定的形式(GET和POST)传递给服务器,服务器通过接收其参数进行相应的响应,这是客户端和服务端进行数据交互的主要方式之一。
Headers标签的内容看起来很多,但在实际使用过程中,爬虫开发人员只需关心请求链接、请求方式、请求头和请求参数的内容即可。
而Preview和Response是服务器返回的结果,两者之间对不同类型的响应结果有不同的显示方式:(1)如果返回的结果是图片,那么Preview表示可显示图片内容,Response表示无法显示。(2)如果返回的是HTML或JSON,那么两者皆能显示,但在格式上可能会存在细微的差异。
*找到页面preview信息
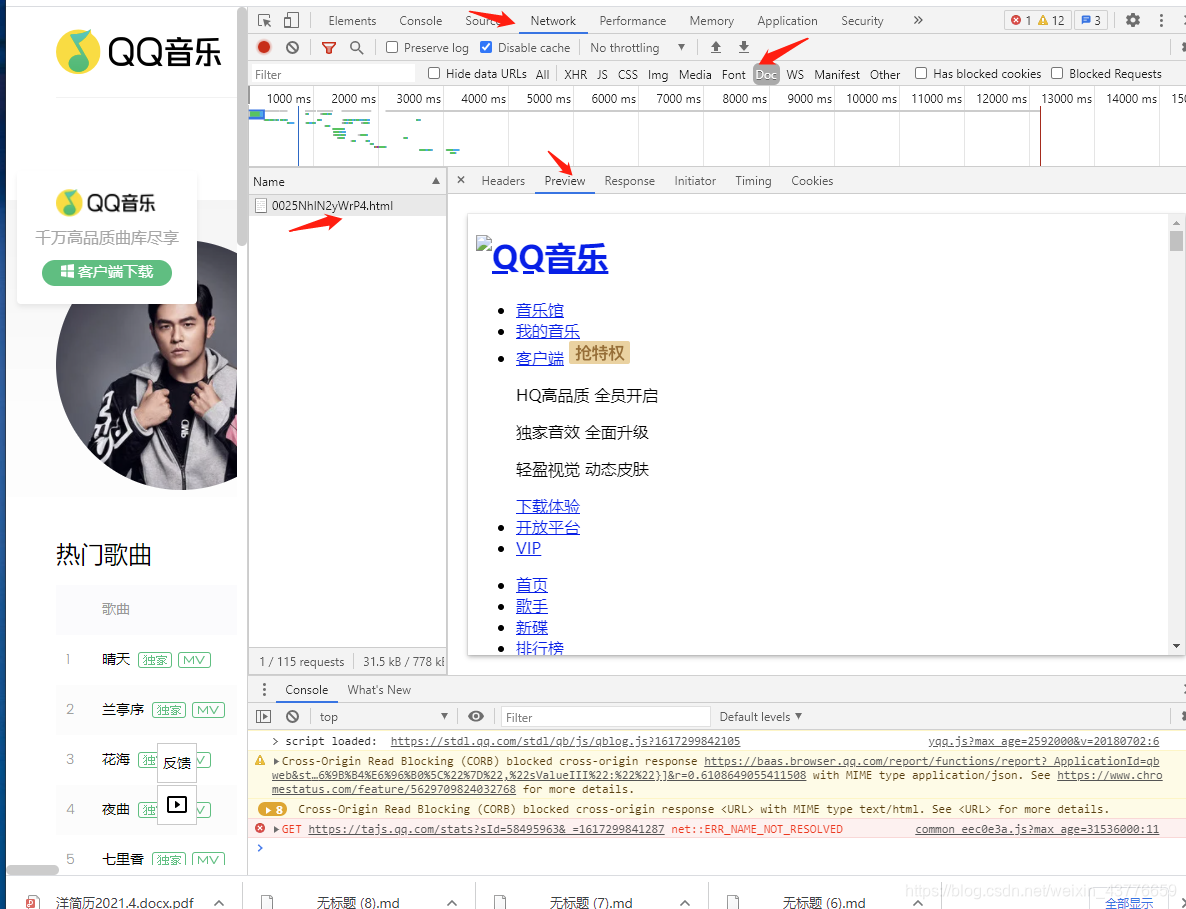 网站数据生成只有前端(Ajax或JSONP)和后端(服务器)两种方式。从图3-8返回的结果来看,数据不可能是从后端生成的,那么就可能是由前端加载生成的。
网站数据生成只有前端(Ajax或JSONP)和后端(服务器)两种方式。从图3-8返回的结果来看,数据不可能是从后端生成的,那么就可能是由前端加载生成的。
前端加载的数据有可能记录在Chrome开发者工具的“XHR”或“JS”中,分别查看两个标签里面的请求信息,最终发现歌曲信息存放在
请求方式是GET, Query StringParameters是记录该请求的参数。因为请求方式是GET,所以请求参数也可以在请求链接上找到。
Urllib在python爬网页构架内容
在Python 3中,Urllib是一个收集几个模块来使用URL的软件包,大致具备以下功能。● urllib.request:用于打开和读取URL。● urllib.error:包含提出的例外urllib.request。● urllib.parse:用于解析URL。● urllib.robotparser:用于解析robots.txt文件。

data:默认值为None, Urllib判断参数data是否为None从而区分请求方式。若参数data为None,则代表请求方式为GET;反之请求方式为POST,发送POST请求。参数data以字典形式存储数据,并将参数data由字典类型转换成字节类型才能完成POST请求。
● timeout:超时设置,指定阻塞操作(请求时间)的超时(如果未指定,就使用全局默认超时设置)。
● cafile、capath和cadefault:使用参数指定一组HTTPS请求的可信CA证书。cafile应指向包含一组CA证书的单个文件;capath应指向证书文件的目录;cadefault通常使用默认值即可。
● context:描述各种SSL选项的实例。
若在爬虫中遇到证书验证,则可将证书验证直接关闭,也可以设置参数指向证书的信息和位置。相比而言,设置证书比较耗时,而且通用性不强。
urlopen对象提供获取网站响应内容的方法函数,分别介绍如下。● read()、readline()、readlines()、fileno()和close():对HTTPResponse类型数据操作。● info():返回HTTPMessage对象,表示远程服务器返回的头信息。● getcode():返回HTTP状态码。● geturl():返回请求的URL。
*成功的请求头
from urllib.request import urlopen, Request
url = 'https://movie.douban.com/top250?start=%s&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
ret = Request(url, headers=headers)
res = urlopen(ret)
aa = res.read().decode('utf-8')
# write in txt
f = open 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









