







学习目标:循环链表和普通链表的区别
学习内容:
1、 循环单链表头指针在最后的优势
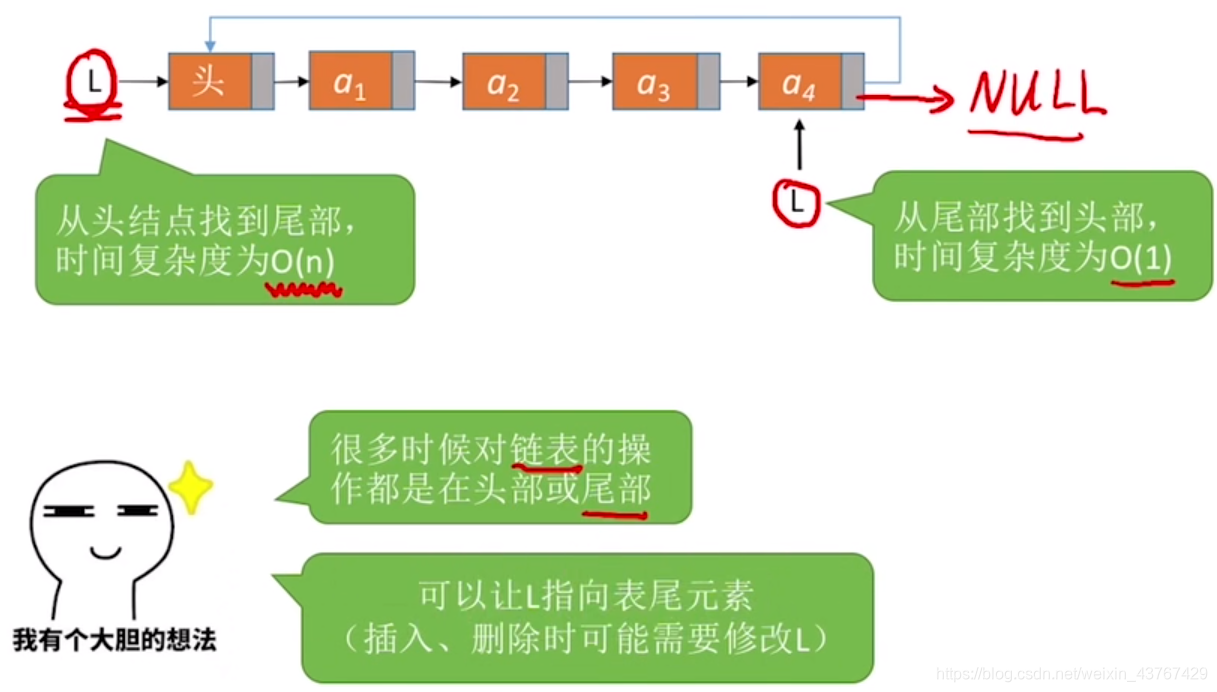
注:只有循环单链表有这个优势,循环双链表不需要
2、 初始化链表的区别
普通链表:
bool init(LinkList &l){
l = (Node*)malloc(sizeof(Node));
l->next = NULL;
l->prior = NULL; //如果是双链表的话
}
循环单链表:
bool init(LinkList &l){
l = (Node*)malloc(sizeof(Node));
l->next = l;
}
循环双链表:
bool init(LinkList &l){
l = (Node*)malloc(sizeof(Node));
l->next = l;
l->prior = l;
}
3、 循环双链表的插入:双链表的区别
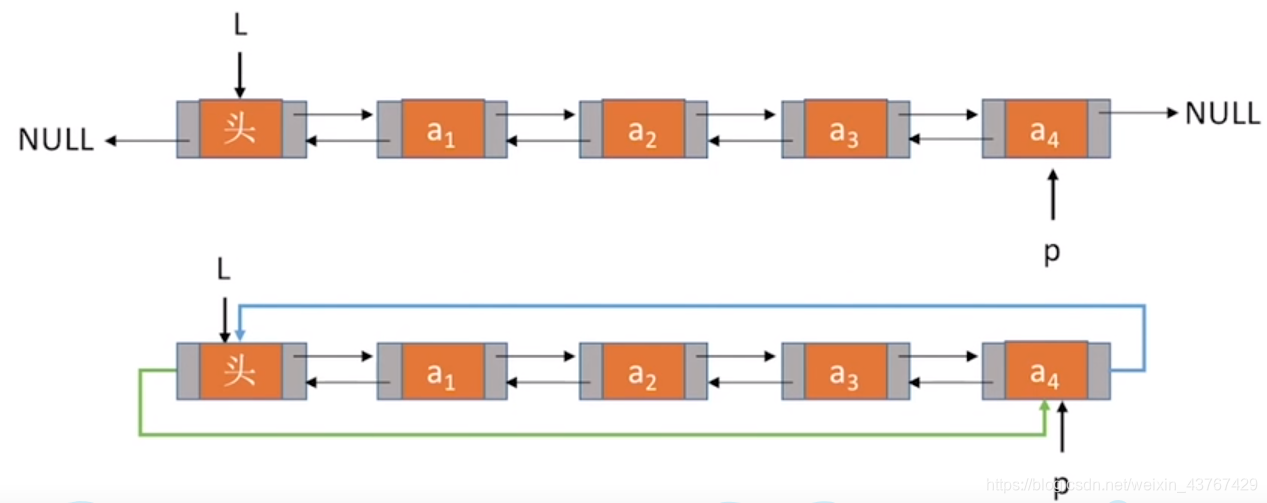
bool InsertNextDNode(DNode*p, DNode*s){
s->next = p->next;
p->next->prior = s; //不用判断是否为最后的结点,因为最后的结点依然有next,是头结点;双链表则需要判断条件
s->prior = p;
p->next = s;
}
可以看出,循环双链表的后插不用考虑是否为最后一个结点,因为它是环状结构
4、 循环双链表的删除
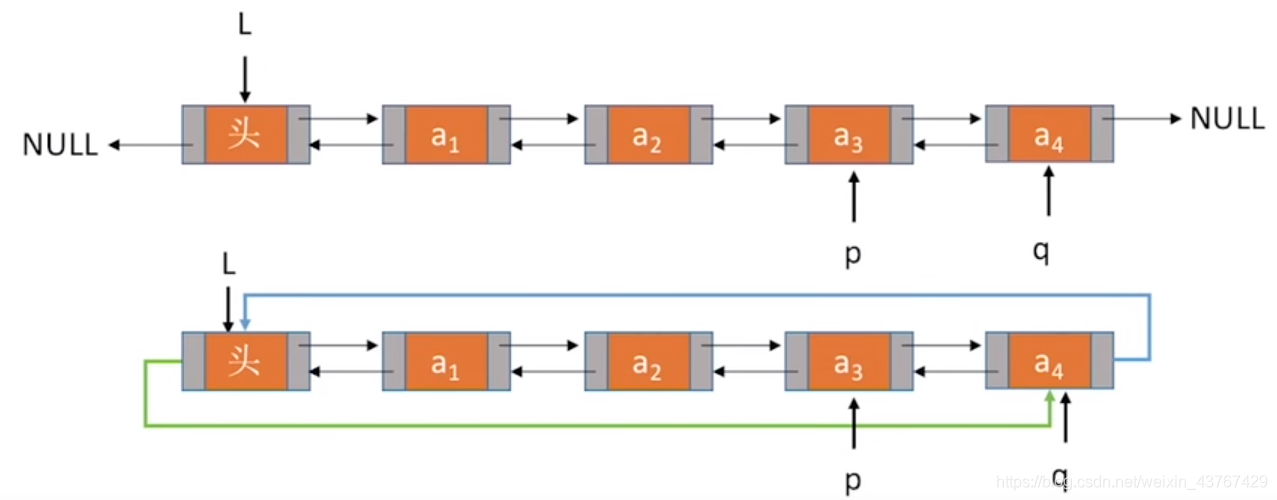
与删除操作类似,也不用考虑尾结点
bool DeletNextDNode(DNode* l, DNode*p){
if(p->next==l){ //保证删除的结点不是头结点,及该结点不应该是最后一个结点
return false;
}
DNode *q = (DNode*)malloc(sizeof(DNode));
if(q==NULL){
return false;
}
p->next = q->next; //若删除结点为最后一个,则q->next = NULL
q->next->prior = p; //由于是循环双链表,所以最后一个结点也存在next,即为头结点
free(q);
}
学习时间:
1、 2021.5.11 15:10-15:50
学习产出:
1、 数据结构视频2.3.4
2、循环双链表与双链表的区别,循环单链表的优势

















 2671
2671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









