






##基于MNIST数据库上的手写识别问题
MNIST数据集
作为一个简单的计算机视觉数据库,包含一系列手写数字图片和对应的标签。图片是28*28的像素矩阵,标签对应0~9,每张图片都经过了大小归一化和居中处理。
MNIST数据集从NIST的Special Database 3 和 Special Database 1 构建而来。其中SD-3由美国人口调查局的员工进行标注,SD-1由美国高中生进行标注,从SD-1与SD-3中各取一半作为MNIST的训练集和测试集。
Definitions :
1.X为输入,MNIST图片是28*28的二维图像,为了进行计算,将其转换为784维的向量,即X=(x0,x1,...,x783)
2.Y为输出,分类器的输出为10类数字(0-9),即Y=(y0,y1,...y9),每一维yi代表图片分类为第i类数字的概率。
3.Label为图片的真实标签,Label=(l0,l1,...l9),但只有一维为1,其他都为0。
4.Softmax回归(Softmax Regression)
-最简单的Softmax回归模型是先将输入层经过一个全连接层得到特征,然后直接通过softmax函数计算多个类别的概率并输出。
-对于有N个类别的多分类问题,指定N个输出节点,N维结果向量经过softmax将归一化为N个[0,1]范围内的实数值,分别表示该样本属于这N个类别的概率。
-在分类问题中,我们一般采用交叉熵损失函数(cross entropy loss)
5.多层感知机(Multilayer Perceptron, MLP)
-Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层(一般在机器学习中,在计算网路层数时不计算输入层,或将输入层记为第0层),因此其拟合能力有限。为了达到更好的识别效果,考虑在输入层和输出层中间加上若干个隐藏层。
-常见的激活函数有sigmoid、tanh、ReLU、Leaky ReLU。(但仅推荐在做二分类的输出层时使用sigmoid函数)
6.卷积神经网络(Convolutional Neural Network, CNN)
-卷积层
-在图像识别里提到的卷积为二维卷积,即离散二维滤波器(卷积核)与二维图像做卷积操作。
(简单来说就是二维滤波器滑动到二维图像上的所有位置,并在每个位置上与该像素点及其领域像素点做内积)
-卷积层中参数较少,得益于
1)局部连接 - 每个神经元仅与输入神经元的一块区域连接,这块局部区域称为感受野(Receptive field)。
2)权重共享 - 计算同一深度切片的神经元时采用的滤波器是共享的。
-池化层
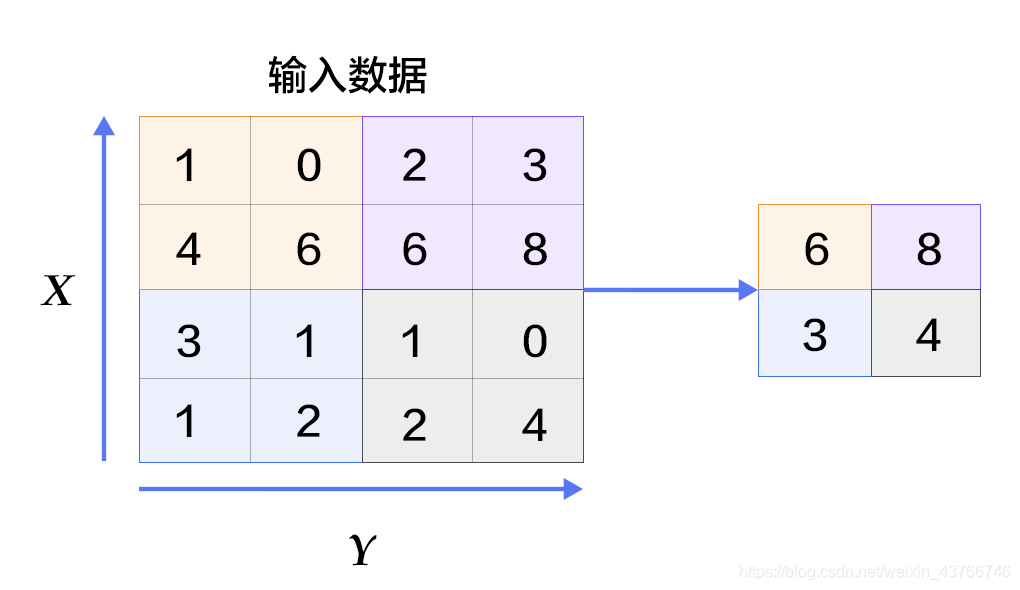
-主要是通过减少网络的参数来减少计算量,并且能够在一定程度上控制过拟合。
-主要有最大池化和平均池化,最大池化如下图。
#代码来自paddlepaddle
from __future__ import print_function #将python3中的print特性导入当前版本
import os
from PIL import Image #导入图像处理模块
import matplotlib.pyplot as plt
import numpy
import paddle
import paddle.fluid as fluid
#用这个程序来演示三个不同的分类器
#paddle为读取数据提供了一个特殊的层layer.data层
#softmax回归,只通过一层简单的以softmax为激活函数的全连接层,就可以得到分类的结果。
def softmax_regression():
#输入的原始图像数据,大小为28*28*1
img = fluid.data(name='img', shape=[None, 1, 28, 28], dtype='float32')
#以softmax为激活函数的全连接层,输出层的大小必须为数字的个数10
predict = fluid.layers.fc(
input=img, size=10, act='softmax')
return predict
#多层感知器,含有两个隐藏层(全连接层),其中两个隐藏层的激活函数均采用ReLU,输出层的激活函数为Softmax
def multilayer_perceptron():
img = fluid.data(name='img', shape=[None, 1, 28, 28], dtype='float32')
#第一个全连接层
hidden = fluid.layers.fc(input=img, size=200, act='relu')
#第二个全连接层
hidden = fluid.layers.fc(input=hidden, size=200, act='relu')
#以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
prediction = fluid.layers.fc(input=hidden, size=10, act='softmax')
return prediction
#卷积池化层,其中将串联的卷积-池化写成conv_pool函数
def conv_pool(input, num_filters, filter_size, pool_size, pool_stride, act='relu'):
conv_out = fluid.layers.conv2d(
input=input,
num_filters=num_filters,
filter_size=filter_size,
act=act)
out = fluid.layers.pool2d(
input=conv_out,
pool_size=pool_size,
pool_stride=pool_stride)
return out
#卷积神经网络,输入二维图像,首先经过两次卷积层到池化层,再经过全连接层,最后使用以softmax为激活函数的全连接层作为输出层。
def convolutional_neural_network():
img = fluid.data(name='img', shape=[None, 1, 28, 28], dtype='float32')
#第一个卷积-池化层
#使用20个5*5的滤波器,池化大小为2,池化步长为2,激活函数为ReLU
conv_pool_1 = conv_pool(
input=img,
filter_size=5,
num_filters=20,
pool_size=2,
pool_stride=2,
act='relu')
conv_pool_1 = fluid.layers.batch_norm(conv_pool_1)
conv_pool_2 = conv_pool(
input=conv_pool_1,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act='relu')
prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax')
return prediction
#Train Program配置
#训练程序返回一个数组,第一个返回参数必须是avg_cost,训练器用其来计算梯度。
def train_program():
#标签层,对应输入图片的类别标签
label = fluid.data(name='label', shape=[None, 1], dtype='int64')
#predict = softmax_regression()
#predict = multilayer_perceptron()
predict = convolutional_neural_network()
#使用类交叉熵函数计算predict和label之间的损失函数
cost = fluid.layers.cross_entropy(input=predict, label=label)
#计算平均损失
avg_cost = fluid.layers.mean(cost)
#计算分类准确率
acc = fluid.layers.accuracy(input=predict, label=label)
return predict, [avg_cost, acc]
#Optimizer Function配置
def optimizer_program():
return fluid.optimizer.Adam(learning_rate=0.001)
#search for Adam
#数据集Feeders配置
#paddle.dataset.mnist.train() and paddle.dataset.mnist.test()分别做训练和测试数据集。
#一个minibatch中有64个数据
BATCH_SIZE = 64
#每次读取训练集中的500个数据并随机打乱,传入batched reader中,batched reader每次yield64个数据
train_reader = fluid.io.batch(
paddle.reader.shuffle(
paddle.dataset.mnist.train(), buf_size=500),
batch_size=BATCH_SIZE)
#读取测试集的数据,每次yield64个数据
test_reader = fluid.io.batch(
paddle.dataset.mnist.test(), batch_size=BATCH_SIZE)
#构建训练过程
#Event Handler配置 - 可以在训练期间通过调用一个handler函数来监控训练进度。
def event_handler(pass_id, batch_id, cost):
#打印训练的中间结果,训练轮次,batch数,损失函数
print("Pass %d, Batch %d, Cost %f" %(pass_id, batch_id, cost))
from paddle.utils.plot import Ploter
train_prompt = "Train cost"
test_prompt = "Test cost"
cost_ploter = Ploter(train_prompt, test_prompt)
#将训练过程绘图表示
def event_handler_plot(ploter_title, step, cost):
cost_ploter.append(ploter_title, step, cost)
cost_ploter.plot()
#开始训练
#模型运行在单个CPU熵
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
#调用train_program获取预测值,损失值
prediction, [avg_loss, acc] = train_program()
#输入的原始图像数据,名称为img,大小为28*28*1
#标签层,名称为label,对应输入图片的类别标签
#告知网络传入的数据分为两部分,第一部分为是img值,第二部分是label值
feeder = fluid.DataFeeder(feed_list=['img','label'], place=place)
#选择Adam优化器
optimizer = optimizer_program()
optimizer.minimize(avg_loss)
#设置训练过程的超参
PASS_NUM = 5 #训练5轮
epochs = [epoch_id for epoch_id in range(PASS_NUM)]
#将模型参数存储在名为save_dirname的文件中
save_dirname = "recognize_digits.inference.model"
def train_test(train_test_program, train_test_feed, train_test_reader):
acc_set = [] #分类准确率
avg_loss_set = [] #平均损失
#将测试reader yield出的每一个数据传入网络中进行训练
for test_data in train_test_reader():
acc_np, avg_loss_np = exe.run(
program=train_test_program,
feed=train_test_feed.feed(test_data),
fetch_list=[acc, avg_loss])
acc_set.append(float(acc_np))
avg_loss_set.append(float(avg_loss_np))
#获得测试数据上的准确率和损失值
acc_val_mean = numpy.array(acc_set).mean()
avg_loss_val_mean = numpy.array(avg_loss_set).mean()
#返回平均损失值,平均准确率
return avg_loss_val_mean , acc_val_mean
#创建执行器
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
main_program = fluid.default_main_program()
test_program = fluid.default_main_program().clone(for_test = True)
#开始训练
lists = []
step = 0
for epoch_id in epochs:
for step_id, data in enumerate(train_reader()):
metrics = exe.run(main_program,
feed=feeder.feed(data),
fetch_list=[avg_loss, acc])
if step % 100 == 0 :
print("Pass %d, Batch %d, Cost %f" %(step, epoch_id, metrics[0]))
event_handler_plot(train_prompt, step, metrics[0])
step += 1
#测试每个epoch的分类效果
avg_loss_val, acc_val = train_test(train_test_program=test_program,
train_test_reader=test_reader,
train_test_feed=feeder)
print("Test with Epoch %d, avg_cost:%s, acc: %s" %(epoch_id, avg_loss_val, acc_val))
event_handler_plot(test_prompt, step, metrics[0])
lists.append((epoch_id, avg_loss_val, acc_val))
#保存训练好的模型参数用于预测
if save_dirname is not None:
fluid.io.save_inference_model(save_dirname,
["img"],[prediction],exe,
model_filename=None,
params_filename=None)
#选择效果最好的pass
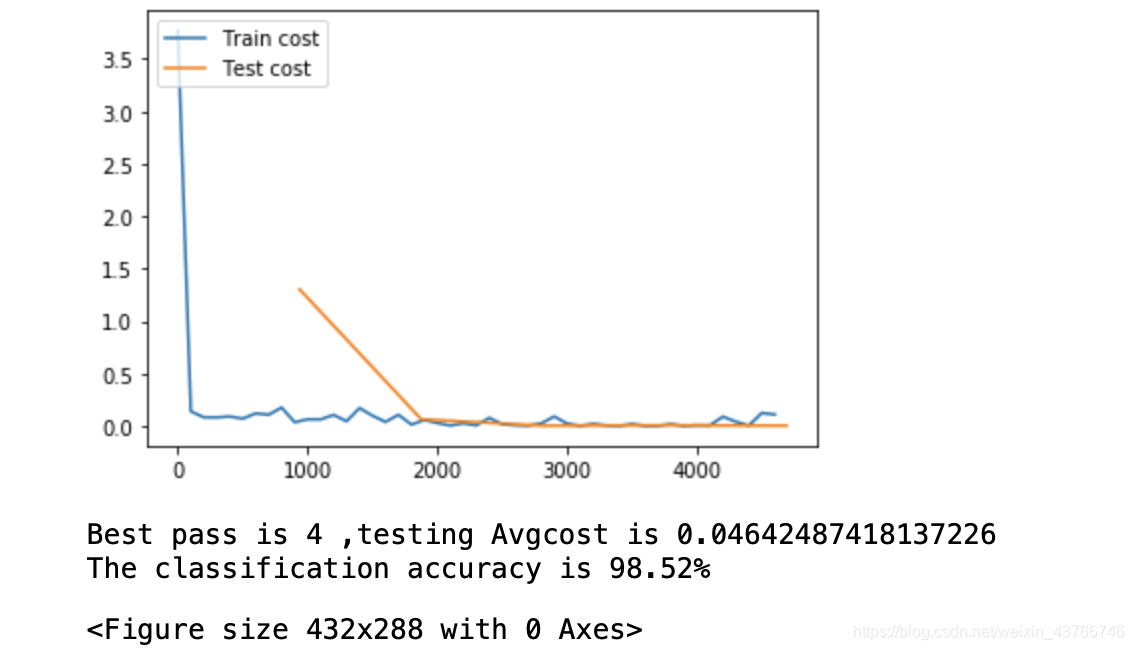
best = sorted(lists, key=lambda list: float(list[1]))[0]
print("Best pass is %s ,testing Avgcost is %s" % (best[0],best[1]))
print("The classification accuracy is %.2f%%" % (float(best[2])*100))result


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









