






1.基础理论
假定正常的数据对象由一个统计模型产生,而不遵守该模型的数据是异常点。
2.参数方法
参数方法假定正常的数据对象被一个以Θ为参数的参数分布产生。该参数分布的概率密度函数f(x,Θ)给出对象x被该分布产生的概率。该值越小,x越可能是异常点。
2.1基于正态分布的一元异常点检测
得到数据后,假设数据服从正态分布,x(i)∼N(μ,σ2) 计算出正态分布的各个参数值:
- μ = ∑ i = 1 m x ( i ) m {\mu= \frac{\sum_{i=1}^mx^{(i)}}{m}} μ=m∑i=1mx(i)
-
σ
2
=
∑
i
=
1
m
(
x
(
i
)
−
μ
)
2
m
{\sigma^2 = \frac{\sum_{i=1}^m(x^{(i)}-\mu)^2}{m}}
σ2=m∑i=1m(x(i)−μ)2
求出参数即可得到正态分布的概率密度函数: -
p
(
x
)
=
1
2
π
σ
e
x
p
(
−
(
x
(
i
)
−
μ
)
2
2
σ
2
)
p(x)={ \frac1{\sqrt{2\pi}\sigma}exp(-\frac{(x^{(i)}-\mu)^2}{2\sigma^2})}
p(x)=2πσ1exp(−2σ2(x(i)−μ)2)
如果计算出来的概率低于阈值,就可以认为该数据点为异常点。
2.1.1阈值设置方法 - 3sigma原则:阈值为 ( μ − 3 σ , μ + 3 σ ) (\mu-3\sigma,\mu+3\sigma) (μ−3σ,μ+3σ),超过范围则为异常点
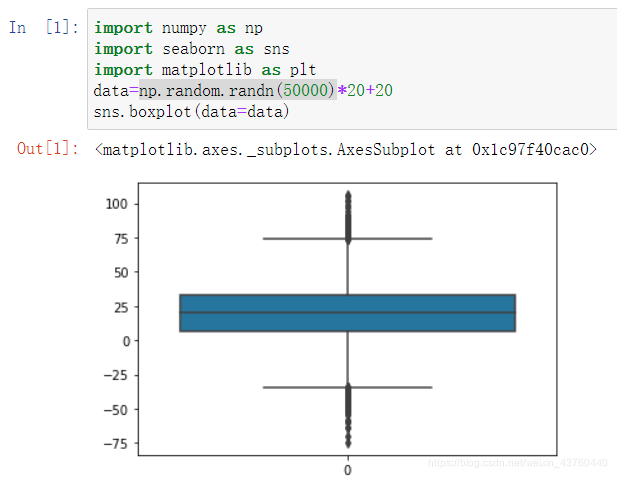
- 箱线图可视化:利用数据集的上下四分位数(Q3和Q1)、中点等形成。异常点常被定义为小于Q1-1.5(Q3-Q1)或大于Q3+1.5(Q3-Q1)的那些数据。
简单的箱线图:
2.2多元异常点检测
核心思想是把多元异常点检测转化为一元异常检测,降维问题,例如正态分布,可以先求出每一维度的均值和标准差,对于第
j
j
j维:
μ
j
=
1
m
∑
i
=
1
m
x
j
(
i
)
\mu_j=\frac 1m\sum_{i=1}^m x_j^{(i)}
μj=m1∑i=1mxj(i)
σ j 2 = 1 m ∑ i = 1 m ( x j ( i ) − μ j ) 2 \sigma_j^2=\frac 1m\sum_{i=1}^m (x_j^{(i)}-\mu_j)^2 σj2=m1∑i=1m(xj(i)−μj)2
- 各个参数相互独立的情况下,计算概率时的概率密度函数为所有维度的乘积:
p ( x ) = ∏ j = 1 n p ( x j ; μ j , σ j 2 ) = ∏ j = 1 n 1 2 π σ j e x p ( − ( x j − μ j ) 2 2 σ j 2 ) p(x)=\prod_{j=1}^n p(x_j;\mu_j,\sigma_j^2)=\prod_{j=1}^n\frac 1{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}) p(x)=∏j=1np(xj;μj,σj2)=∏j=1n2πσj1exp(−2σj2(xj−μj)2)
- 多个特征相关,且符合多元高斯分布:
- μ = 1 m ∑ i = 1 m x ( i ) \mu=\frac{1}{m}\sum^m_{i=1}x^{(i)} μ=m1∑i=1mx(i)
∑ = 1 m ∑ i = 1 m ( x ( i ) − μ ) ( x ( i ) − μ ) T \sum=\frac{1}{m}\sum^m_{i=1}(x^{(i)}-\mu)(x^{(i)}-\mu)^T ∑=m1∑i=1m(x(i)−μ)(x(i)−μ)T
p ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x)=\frac{1}{(2 \pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}} \exp \left(-\frac{1}{2}(x-\mu)^{T} \Sigma^{-1}(x-\mu)\right) p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
3.非参数法
通常,非参数方法对数据做较少假定,因而在更多情况下都可以使用。
4.HBOS法
简单来说就是降维,先求每个维度的概率,再合并,降到一维,最终目的是求样本的概率密度*
1.为每个数据维度做出数据直方图。对分类数据统计每个值的频数并计算相对频率。对数值数据根据分布的不同采用以下两种方法:
静态宽度直方图:标准的直方图构建方法,在值范围内使用k个等宽箱。样本落入每个桶的频率(相对数量)作为密度(箱子高度)的估计。时间复杂度: O ( n ) O(n) O(n)
2.动态宽度直方图:首先对所有值进行排序,然后固定数量的 N k \frac{N}{k} kN个连续值装进一个箱里,其中N是总实例数,k是箱个数;直方图中的箱面积表示实例数。因为箱的宽度是由箱中第一个值和最后一个值决定的,所有箱的面积都一样,因此每一个箱的高度都是可计算的。这意味着跨度大的箱的高度低,即密度小,只有一种情况例外,超过k个数相等,此时允许在同一个箱里超过 N k \frac{N}{k} kN值。
时间复杂度: O ( n × l o g ( n ) ) O(n\times log(n)) O(n×log(n))
2.对每个维度都计算了一个独立的直方图,其中每个箱子的高度表示密度的估计。然后为了使得最大高度为1(确保了每个特征与异常值得分的权重相等),对直方图进行归一化处理。最后,每一个实例的HBOS值由以下公式计算:
H B O S ( p ) = − log ( P ( p ) ) = ∑ i = 1 d 1 log ( P i ( p ) ) H B O S(p)=-\log (P(p))=\sum_{i=1}^{d} \frac{1}{\log \left(P_{i}(p)\right)} HBOS(p)=−log(P(p))=i=1∑dlog(Pi(p))1
推导过程:
假设样本p第 i 个特征的概率密度为 p i ( p ) p_i(p) pi(p) ,则p的概率密度可以计算为: P ( p ) = P 1 ( p ) P 2 ( p ) ⋯ P d ( p ) P(p)=P_{1}(p) P_{2}(p) \cdots P_{d}(p) P(p)=P1(p)P2(p)⋯Pd(p) 两边取对数: log ( P ( p ) ) = log ( P 1 ( p ) P 2 ( p ) ⋯ P d ( p ) ) = ∑ i = 1 d log ( P i ( p ) ) \begin{aligned} \log (P(p)) &=\log \left(P_{1}(p) P_{2}(p) \cdots P_{d}(p)\right) =\sum_{i=1}^{d} \log \left(P_{i}(p)\right) \end{aligned} log(P(p))=log(P1(p)P2(p)⋯Pd(p))=i=1∑dlog(Pi(p)) 概率密度越大,异常评分越小,为了方便评分,两边乘以“-1”: − log ( P ( p ) ) = − 1 ∑ i = 1 d log ( P t ( p ) ) = ∑ i = 1 d 1 log ( P i ( p ) ) -\log (P(p))=-1 \sum_{i=1}^{d} \log \left(P_{t}(p)\right)=\sum_{i=1}^{d} \frac{1}{\log \left(P_{i}(p)\right)} −log(P(p))=−1i=1∑dlog(Pt(p))=i=1∑dlog(Pi(p))1 最后可得: H B O S ( p ) = − log ( P ( p ) ) = ∑ i = 1 d 1 log ( P i ( p ) ) H B O S(p)=-\log (P(p))=\sum_{i=1}^{d} \frac{1}{\log \left(P_{i}(p)\right)} HBOS(p)=−log(P(p))=i=1∑dlog(Pi(p))1
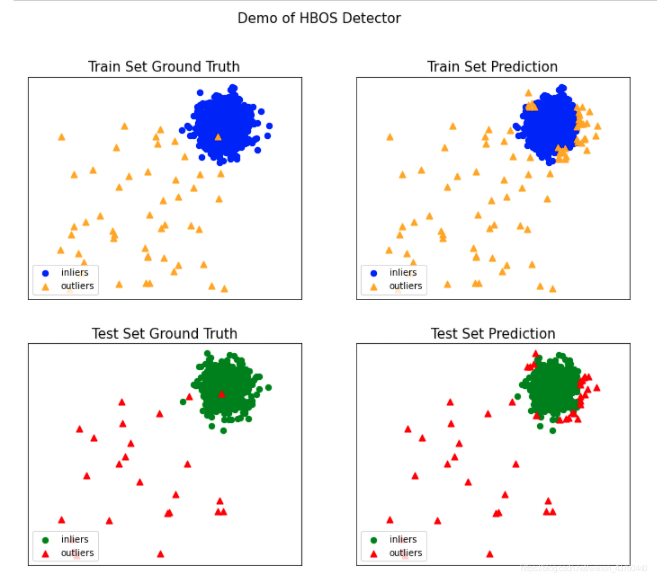
案例尝试:

















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









