







一、实现爬虫包含动态页面的“南京市公共资源交易中心”“南京公共采购信息网”等网站的爬虫,并且保存本地的“招标信息汇总.csv”。
效果展示:
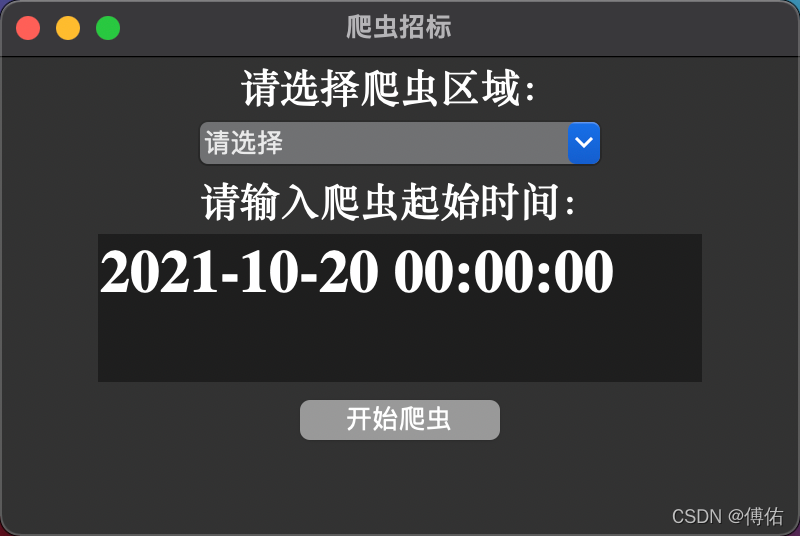
(1)界面:
打包成了exe文件,点击即可使用!!

(2)爬取网站:
南京公共采购信息网(公共招标公告)
南京市公共资源交易中心(政府采购)
南京市公共资源交易中心(工程货物)
得到: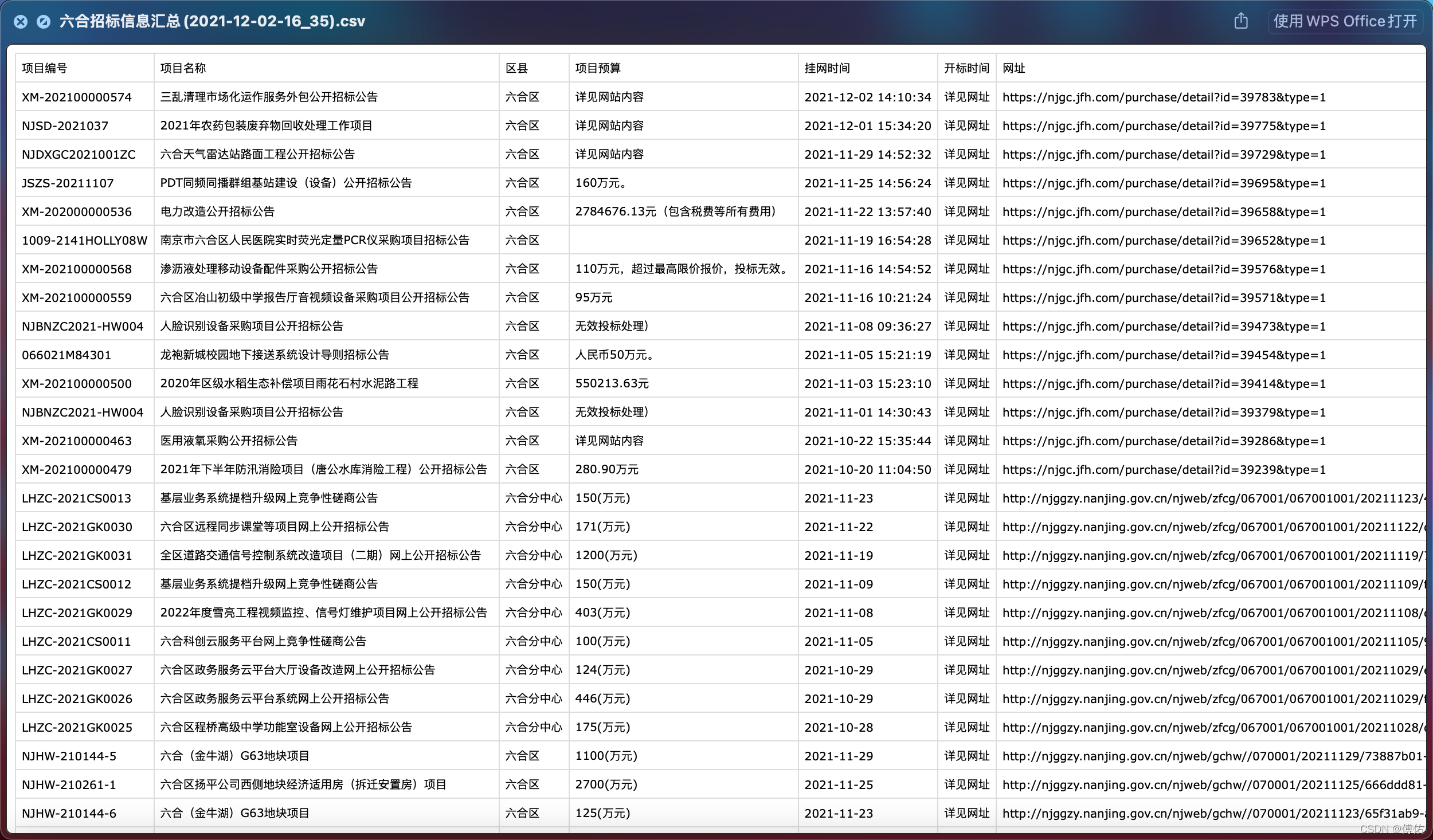
二、python代码
# -*- coding: utf-8 -*-
# 作者:傅佑
import tkinter as tk
import csv
import random
import requests
import json
import numpy as np
import os
import itchat
import traceback
from time import sleep
from lxml import etree #lxml为第三方网页解析库,强大且速度快
import pandas as pd
import time
import openpyxl
import tkinter
import tkinter as tk
from tkinter import ttk
import tkinter
def go(*args): # 处理事件,*args表示可变参数
print(comboxlist.get())
np.savez("area.npz", k_b=comboxlist.get())
# 第1步,建立窗口window
window = tk.Tk() # 建立窗口window
# 第2步,给窗口起名称
window.title('爬虫招标') # 窗口名称
# 第3步,设定窗口的大小(长*宽)
window.geometry("400x240") # 窗口大小(长*宽)
# 第4步,在图形化界面上设定一个文本框
tk.Label(window,text="请选择爬虫区域:",font=("Times",20,"bold")).pack()
# 显示成明文形式
textExample = tk.Text(window, height=2 ,width=20,font=("Times",30,"bold"))# 创建文本输入框
comvalue = tkinter.StringVar()
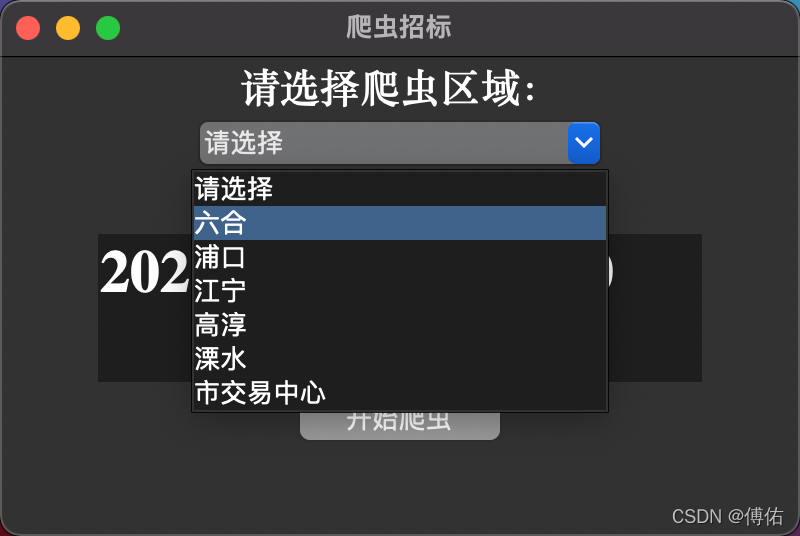
comboxlist = ttk.Combobox(window, textvariable=comvalue)
comboxlist["values"] = ("请选择","六合", "浦口", "江宁", "高淳", "溧水", "市交易中心")
comboxlist.current(0) # 选择第一个
comboxlist.bind("<<ComboboxSelected>>", go)
comboxlist.pack()
# 第5步,安置文本框
tk.Label(window,text="请输入爬虫起始时间:",font=("Times",20,"bold")).pack()
textExample.pack() # 把Text放在window上面,显示Text这个控件
textExample.insert("insert", "2021-10-20 00:00:00")
# 第6步,获取文本框输入
def getTextInput():
starttime= str(textExample.get("1.0", "end") ) # 获取文本输入框的内容
np.savez("time.npz",k_a=starttime)
print(starttime)
window.destroy()
# 输出结果
# Tkinter 文本框控件中第一个字符的位置是 1.0,可以用数字 1.0 或字符串"1.0"来表示。
# "end"表示它将读取直到文本框的结尾的输入。我们也可以在这里使用 tk.END 代替字符串"end"。
# 第7步,在图形化界面上设定一个button按钮(#command绑定获取文本框内容的方法)
btnRead = tk.Button(window, height=1, width=8, text="开始爬虫", command=getTextInput) # command绑定获取文本框内容的方法
# 第8步,安置按钮
btnRead.pack() # 显示按钮
# 第9步,
window.mainloop() # 显示窗口
data_a = np.load('time.npz')
data_b = np.load('area.npz')
starttime = str(data_a["k_a"])
area = str(data_b["k_b"])
mowtime = time.strftime("%Y-%m-%d-%H_%M", time.localtime())
#starttime = str('2021-10-20 00:00:00')
root = tk.Tk()
###########################njgc/南京公共采购信息网(公共招标公告)########################
def csv_to_xlsx_pd():
csv = pd.read_csv(area+'招标信息汇总('+mowtime+').csv', encoding='utf-8')
csv.to_excel(area+'招标信息汇总('+mowtime+').xlsx', sheet_name='data')
num=int(50)
n=str(num)
header1 = {"content-type":"application/json"}
base_url = 'https://njgc.jfh.com/app/openTenderNotice/queryPage/' #这里要换成对应Ajax请求中的链接
#page = 1
if area =="六合":
no="320116"
elif area =="浦口":
no="320111"
elif area =="溧水":
no="320117"
elif area =="高淳":
no="320118"
elif area =="江宁":
no="320115"
payload = {"projectAttributionCode":no,"page":"1","rows":n}
url = base_url
response = requests.request("POST",url,json=payload, headers = header1)
re = response.content.decode('utf-8')
c = json.loads(re)
d = c['data']
e=d['records']
def download_page(url, user_Agent=None, referer=None):
# 应对反爬虫,构建User_Agent池
ua_list = [
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0"
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0",
]
user_Agent = random.choice(ua_list)
headers = {
"Referer": referer,
"User-Agent": user_Agent
}
response = requests.get(url=url, headers=headers)
try:
html = response.content.decode("utf-8")
except Exception as e:
print("Download error:", e)
html = None
return html
def xml_aly(rule, url):
html = download_page(url)
tree = etree.HTML(html) #将传进去的字符串转变成_Element对象。作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法。
aly_res = tree.xpath(rule)
return aly_res
with open(area+'招标信息汇总('+mowtime+').csv', 'a', newline='') as f: #a是追加
writer = csv.writer(f)
writer.writerow(['项目编号','项目名称','区县','项目预算','挂网时间','开标时间','网址','爬取网站','类别']) # 写入表头
for i in range(num): #id、title、releaseTime(发布时间)、purchaseItemsCodeName(类型)
id = e[i]['id']
title = e[i]['title']
releaseTime=e[i]['releaseTime']
if releaseTime > starttime:
purchaseItemsCodeName=e[i]['purchaseItemsCodeName']
url = 'https://njgc.jfh.com/purchase/detail?id='+str(id)+'&type=1'
rule_host = '//*[@id="__layout"]/div/div/div/div/div/article//text()' #//*[@id="__layout"]/div/div[1]/div/div/div[2]/article
project_link = xml_aly(rule=rule_host, url=url)
m = project_link.count(str('\n'))
#for j in range(m):
#project_link.remove(str('\n'))
#########################################print(project_link)
project = [str(i) for i in project_link]
list = ''.join(project)
x = list.find(str("采购需求"), 0, len(list)) #"申请人的资格要求"这段话的位置
list=list[0:x]
#print(list)
#print(x)
#str.spn(list, "项目编号")
#找到"项目编号"
y = list.find(str("编号"))
z = list.find(str("项目名称"))
yz = list.find(str("\n") or str("\n\t"), y, z)
num = list[y + 3:yz]
if len(num)>35:
num = "详见网站内容"
else:
num = num
# 找到"项目预算"
y0 = list.find(str("项目预算"), 0, x)
y1 = list.find(str("预算金额"and"最高限价"), 0, x)
z1 = list.find(str("\n"), y1, x)
yz1 = list.find(str("\n"), y1, z1)
Budget=list[y1 + 5:z1]
if len(Budget)>25:
z0 = list.find(str("\n"), y0, x)
yz0 = list.find(str("\n"), y0, z0)
bud = list[y0 + 5:z0]
if len(bud)>25:
bud="详见网站内容"
else:
bud
else:
bud=Budget
project_Name = title # 项目名称
project_Purchaser = area+'区' #地区
project_Budget = bud # 预算
project_Hang_up_time = releaseTime # 挂网时间
project_Bid_opening_time = "详见网址" # 开标时间
project_Website = url # 网站
project_Num = num #项目编号
web = "南京公共采购信息网(公共招标公告)" #爬取网站
classif=purchaseItemsCodeName
writer.writerow([project_Num,project_Name,project_Purchaser, project_Budget, project_Hang_up_time, project_Bid_opening_time,project_Website,web,classif])
#########################njggzy南京市公共资源交易中心(政府采购)###################################
n = int(20) # 页数
k = int(0)
with open(area+'招标信息汇总('+mowtime+').csv', 'a', newline='') as f:
writer = csv.writer(f)
#writer.writerow(['项目编号', '项目名称', '区县', '项目预算', '挂网时间', '开标时间', '网址', '爬取网站', "类别"]) # 写入表头
# 翻页获取所有招标项目链接
for i in range(1, n + 1): # 每一页
for j in range(1, 10):
if i == 1:
u_host = "http://njggzy.nanjing.gov.cn/njweb/zfcg/067001/067001001/moreinfozfcg.html?_=81205" # 第一页
else:
u_host = "http://njggzy.nanjing.gov.cn/njweb/zfcg/067001/067001001/" + str(
i + 1) + ".html?_=46978" # 第二页及之后
#print(u_host)
rule_host = '//*[@id="iframe067001001"]/ul/li[' + str(j) + ']/div/p/text()' #
# print(rule_host)
project_link = xml_aly(rule=rule_host, url=u_host)
if project_link[2] == (area+'分中心') and project_link[4]>starttime[0: 10]:
print(project_link[4] )
# print(project_link)
# 爬取html,并写入csv
k = k + 1
host = "http://njggzy.nanjing.gov.cn/njweb/zfcg/goverPurchase.html#"
rule_host1 = '//*[@id="iframe067001001"]/ul/li[' + str(j) + ']/@onclick' #
project_link1 = str(xml_aly(rule=rule_host1, url=u_host))
# print(str(project_link1)+"onclick")
# print(project_link1)
url_head = "http://njggzy.nanjing.gov.cn"
url = url_head + str(project_link1)[15:-5]
#print("第" + str(k) + "项,已经爬取目标网址:" + str(project_link[1]) + str(url))
project_Name = project_link[1] # 项目名称
project_Purchaser = project_link[2] # 采购人
print(project_Purchaser)
project_Budget = project_link[3] + "(万元)" # 预算
project_Hang_up_time = project_link[4] # 挂网时间
project_Bid_opening_time = "详见网址" # 开标时间
project_Website = url # 网站
project_Num = project_link[0] # 网址
web = "南京市公共资源交易中心(政府采购)"
classif = "政府采购"
writer.writerow([project_Num, project_Name, project_Purchaser, project_Budget, project_Hang_up_time,
project_Bid_opening_time, project_Website, web, classif])
#######################njggzy_goods南京市公共资源交易中心(工程货物)#########################
header1 = {"content-type":"application/x-www-form-urlencoded; charset=UTF-8"}
base_url = 'http://njggzy.nanjing.gov.cn/webdb_njggzy/fjszListAction.action?cmd=getInfolist' #这里要换成对应Ajax请求中的链接
payload = {'categorynum':'070001','keyword':area,'pageIndex': 1,'pageSize' : 50}
url = base_url
response = requests.post(url,data=payload)
resp = response.content.decode('utf-8')
res=eval(resp)
#re1=re.encode('utf-8').decode('unicode_escape')
res1=res['custom']
res1=eval(res1)
res2=res1['Table']
res0=res2[0]
with open(area+'招标信息汇总('+mowtime+').csv', 'a', newline='') as f:
writer = csv.writer(f)
#writer.writerow(['项目编号', '项目名称', '区县', '项目预算', '挂网时间', '开标时间', '网址', '爬取网站', "类别"]) # 写入表头
for i in range(50):
GongGaoFBDate = res2[i]['GongGaoFBDate']
if GongGaoFBDate>starttime[0:10]:
print(GongGaoFBDate)
ProjectName=res2[i]['ProjectName']
BiaoDuanName=res2[i]['BiaoDuanName']
FaBaoPrice=res2[i]['FaBaoPrice']+"(万元)"
GongGaoStartDate=res2[i]['GongGaoStartDate']
BiaoDuanNO=res2[i]['BiaoDuanNO']
href=repr(res2[i]['href'])
href1=href[18:25]
#print(href1)
href2=href[27:36]
#print(href2)
href3=href[38:-6]
#print(href3)
url=('http://njggzy.nanjing.gov.cn/njweb/gchw/'+href1+href2+href3+".html")
#print(ProjectName+str("(")+BiaoDuanName+str(")"))
#print(FaBaoPrice)
project_Purchaser = area+'区'
project_Bid_opening_time = "详见网址"
project_Website = url
web="南京市公共资源交易中心(工程货物)"
classif='工程货物'
writer.writerow([BiaoDuanNO, ProjectName, project_Purchaser, FaBaoPrice, GongGaoFBDate, project_Bid_opening_time,project_Website, web, classif])
csv_to_xlsx_pd()
#itchat.auto_login(hotReload=True)
#users=itchat.search_friends("傅佑")
#userName= users[0]['UserName']
#itchat.send_file(area+'招标信息汇总('+mowtime+').csv',toUserName=userName)
三、实现过程
(1)观察与分析目标网站;
1、观察首页:http://njggzy.nanjing.gov.cn/njweb/zfcg/067001/goverPurchase.html
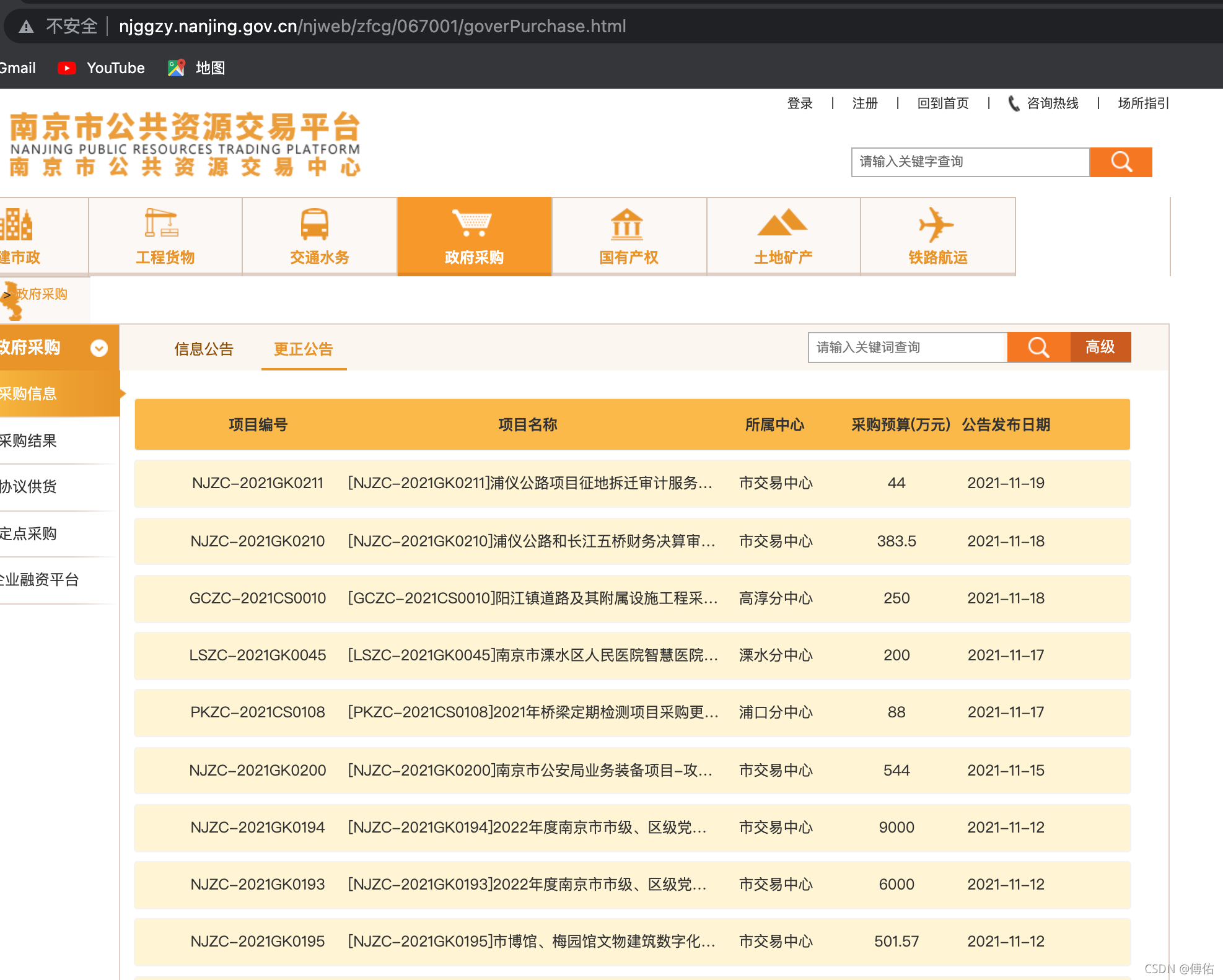
2、点击第2页及其他页,发现URL保持不变,可以得出不是普通的静态页面。
3、右键,再选择“显示网页源代码”
得到:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta name="renderer" content="webkit">
<meta name="SiteName" content="南京市公共资源交易平台">
<meta name="SiteDomain" content="http://njggzy.nanjing.gov.cn">
<meta name="SiteIDCode" content="3201000077">
<meta name="ColumnName" content="采购信息">
<meta name="ColumnDescription" content="">
<meta name="ColumnKeywords" content="">
<meta name="ColumnType" content="">
<title>南京市公共资源交易平台</title>
<link rel="stylesheet" href="/njweb/css/common.css">
<link rel="stylesheet" href="/njweb/css/goverPurchase.css">
<link rel="stylesheet" href="/njweb/css/pagination.css">
<script src="/njweb/js/lib/jquery-1.11.0.min.js"></script>
<script src="/njweb/js/jquery.pagination.js"></script>
<link rel="stylesheet" href="/njweb/css/subpage.css">
<script src="/njweb/js/webBuilderCommon.js"></script>
<script src="/njweb/js/ServiceUtil.js"></script>
<style>
.xyghspan{align:center;text-align:left;margin-bottom:10px;display:inline-block;margin-left:20px;margin-right:60px;cursor:pointer;line-height:48px;width:170px;height:48px;font-size:16px;font-family:Microsoft YaHei}
</style>
<link rel="stylesheet" href="/njweb/css/webBuilderCommonGray.css"></head>
<body>
<!-- header -->
<div id="header"></div>
<script type="text/javascript">
$("#header").load("/njweb/header.html");
</script>
<!-- main -->
<div class="ewb-container">
<div class="ewb-location">
<a href="/njweb/">首页</a> > <span class="ewb-yellow" id="viewGuid" value="cms_067001">政府采购</span>
</div>
<div class="ewb-main">
<div data-role="body" class="ewb-expose-bd ewb-main" >
<div data-role="tab-content" data-id="tab-aa">
<div class="ewb-menu clearfix">
<div class="wb-tree">
<ul class="ewb-menu-items">
<li class="wb-tree-items haschild current">
<h3 class="wb-tree-node first">
<i class="wb-tree-iconr"></i>
<a href="#" class="wb-tree-tt">政府采购</a>
</h3>
<ul class="wb-tree-sub">
<li class="ewb-menu-item cur">
<a href="/njweb/zfcg/goverPurchase.html">采购信息</a>
<i class="ewb-menu-icon"></i>
</li>
<li class="ewb-menu-item">
<a href="/njweb/zfcg/067002/goverPurchase2.html">采购结果</a>
<i class="ewb-menu-icon"></i>
</li>
<li class="ewb-menu-item">
<a href="/njweb/zfcg/067004/goverPurchase4.html">协议供货</a>
<i class="ewb-menu-icon"></i>
</li>
<li class="ewb-menu-item">
<a href="/njweb/zfcg/067005/goverPurchase5.html">定点采购</a>
<i class="ewb-menu-icon"></i>
</li>
<li class="ewb-menu-item">
<a href="/njweb/zfcg/067006/goverPurchase6.html">小企业融资平台</a>
<i class="ewb-menu-icon"></i>
</li>
</ul>
</li>
</ul>
</div>
<div class="ewb-menu-r">
<div class="ewb-comp tab-view">
<div class="ewb-comp-hd clearfix" data-role="head">
<span class="ewb-comp-tt current l " data-role="tab" data-target="tab-aa">
<a href="javascript:void(0);">信息公告</a>
</span>
<span class="ewb-comp-tt l" data-role="tab" data-target="tab-bb">
<a href="javascript:void(0);"> 更正公告</a>
</span>
<div class="ewb-info-search ewb-zfcg clearfix">
<input type="text" placeholder="请输入关键词查询" id="keywordcg">
<button class="ewb-high" onclick="javascript:void(window.location.href='/njweb/zfcg/067001/goverPurchase.html?type=gjss')">高级</button>
<button onclick="searchlistcg();"></button>
</div>
</div>
<div data-role="body" class="ewb-comp-bd" id="content">
<div data-role="tab-content" data-id="tab-aa">
<div class="ewb-addSearch clearfix" style="display:none;">
<span class="ewb-add-name">项目名称:</span>
<input type="text" class="ewb-add-input" id="xmmc1" style="width:228px;">
<span class="ewb-add-name" style="margin-left:30px;">项目编号:</span>
<input type="text" class="ewb-add-input" id="xmbh1" style="width:193px;">
<span class="ewb-add-name">价格:</span>
<input type="text" class="ewb-add-input" id="price1">
<span style="width:22px;padding-right:5px;">至</span>
<input type="text" class="ewb-add-input" id="price2">
<span style="width:40px;">万元</span>
<span class="ewb-add-name">时间:</span>
<input type="text" class="ewb-add-input" id="fbrq1" onfocus="WdatePicker({maxDate:'#F{$dp.$D(\'fbrq2\')}'})">
<span style="width:22px;padding-right:5px;">至</span>
<input type="text" class="ewb-add-input" id="fbrq2" onfocus="WdatePicker({minDate:'#F{$dp.$D(\'fbrq1\')}'})">
</div>
<div class="ewb-add-btn" style="display:none;">
<button onclick="searchgjlist();">查找</button>
</div>
<div id="iframe1"></div>
<script type="text/javascript">
$("#iframe1").load("/njweb/zfcg/067001/067001001/moreinfozfcg.html?_="+Math.floor(Math.random()*100000));
</script>
</div>
<div data-role="tab-content" data-id="tab-bb" class="hidden">
<div class="ewb-addSearch clearfix" style="display:none;">
<span class="ewb-add-name">项目名称:</span>
<input type="text" class="ewb-add-input" id="xmmc2" style="width:228px;">
<span class="ewb-add-name" style="margin-left:30px;">项目编号:</span>
<input type="text" class="ewb-add-input" id="xmbh2" style="width:193px;">
<span class="ewb-add-name">价格:</span>
<input type="text" class="ewb-add-input" id="price3">
<span style="width:22px;padding-right:5px;">至</span>
<input type="text" class="ewb-add-input" id="price4">
<span style="width:40px;">万元</span>
<span class="ewb-add-name">时间:</span>
<input type="text" class="ewb-add-input" id="fbrq3" onfocus="WdatePicker({maxDate:'#F{$dp.$D(\'fbrq4\')}'})">
<span style="width:22px;padding-right:5px;">至</span>
<input type="text" class="ewb-add-input" id="fbrq4" onfocus="WdatePicker({minDate:'#F{$dp.$D(\'fbrq3\')}'})">
</div>
<div class="ewb-add-btn" style="display:none;">
<button onclick="searchgjlist2();">查找</button>
</div>
<div id="iframe2"></div>
<script type="text/javascript">
$("#iframe2").load("/njweb/zfcg/067001/067001002/moreinfozfcg.html?_="+Math.floor(Math.random()*100000));
</script>
</div>
</div>
</div>
</div>
</div>
</div>
<div id="footer"></div>
<script type="text/javascript">
$("#footer").load("/njweb/footer.html");
</script>
</div>
</div>
</div>
<script src="/njweb/js/lib/jquery.placeholder.min.js"></script>
<script src="/njweb/js/lib/tabview.js"></script>
<script src="/njweb/js/common.js"></script>
<script src="/njweb/js/workGuide.js"></script>
<script src="/njweb/js/lib/tree.js"></script>
<script src="/njweb/js/page.js"></script>
<script src="/njweb/js/goverPurchase.js"></script>
<script src="/njweb/js/goverPurchase1.js"></script>
<script src="/njweb/js/pageView1.js"></script>
<script language="javascript" type="text/javascript" src="/njweb/js/My97DatePicker/WdatePicker.js"></script>
</body>
</html>
通过观察,确实没有首页显示的很多项目信息。可以得出这个网页这部分是读取外部json数据来动态更新的,细想是符合采购、招标信息的特性的,页面这部分是会适时更新,具有时效性。
(2)打开“开发者工具”分析欲爬取的目标信息;
选择鼠标:
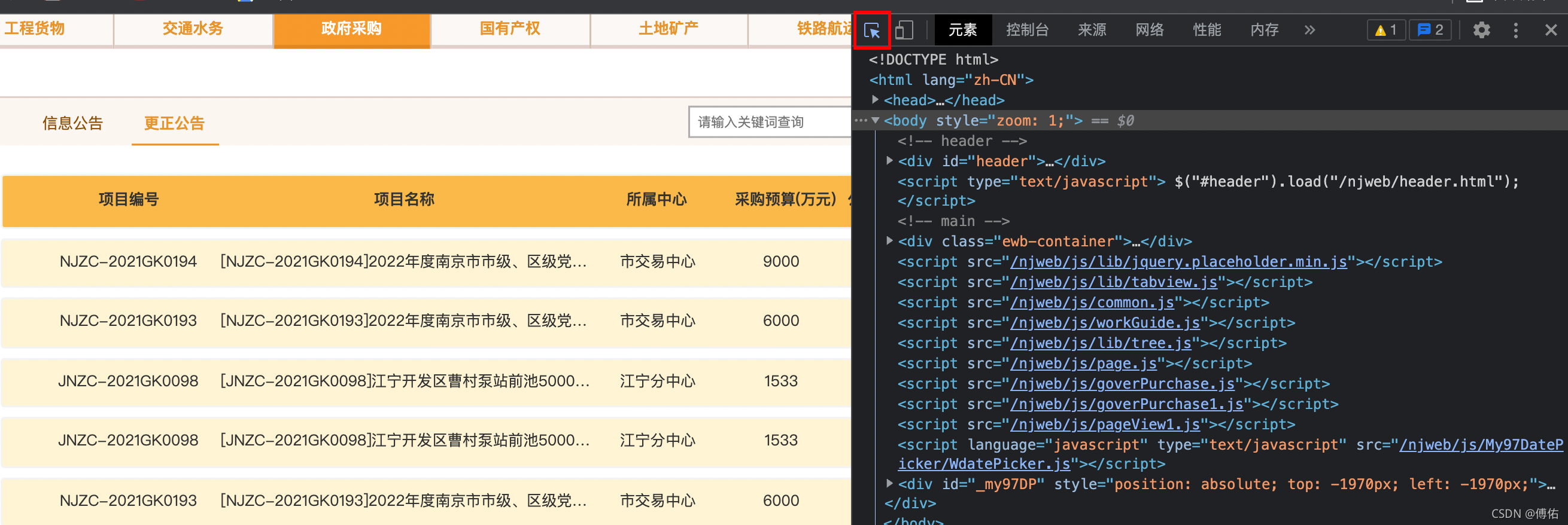
选择我们关心的信息:
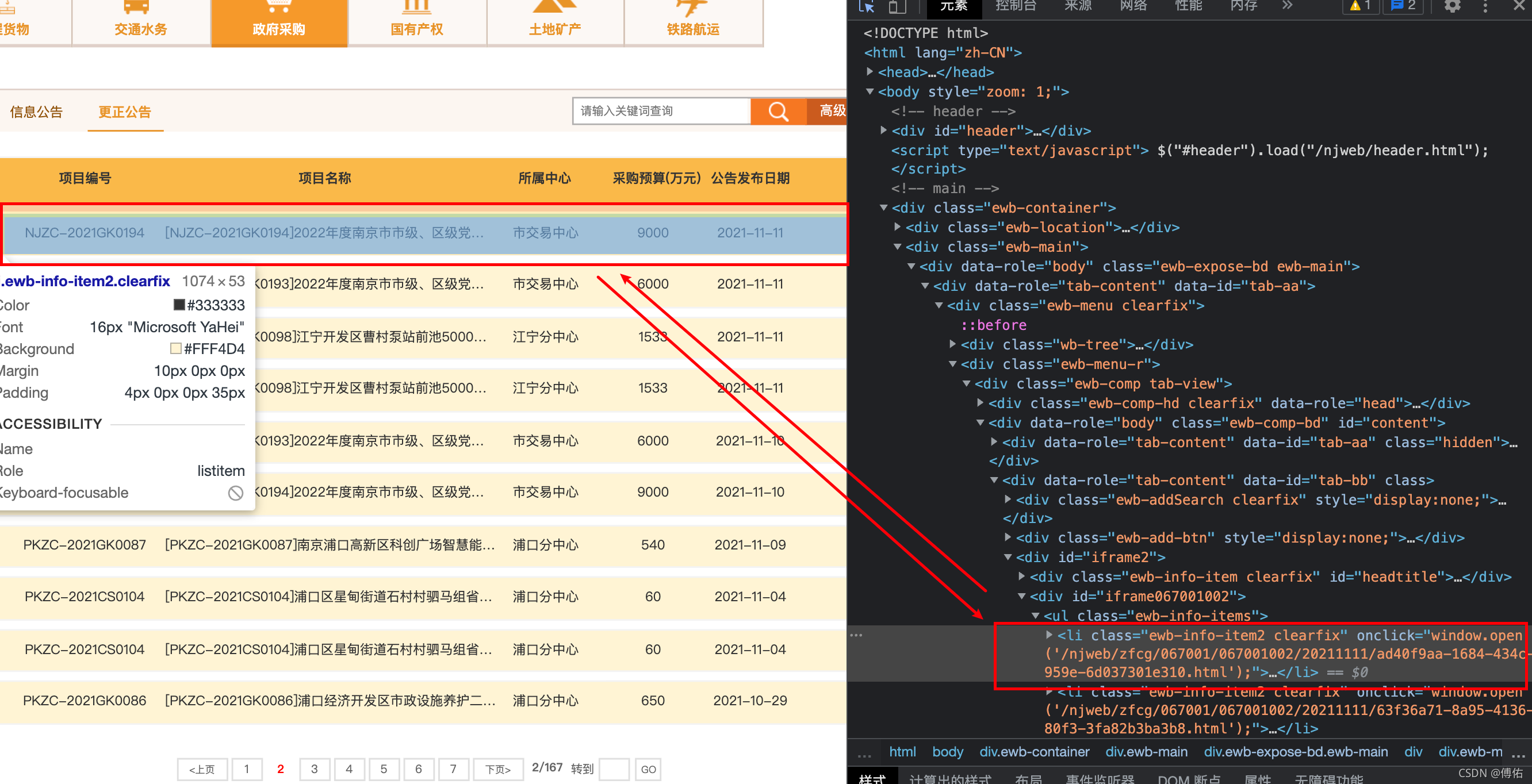
查看Xpath信息:
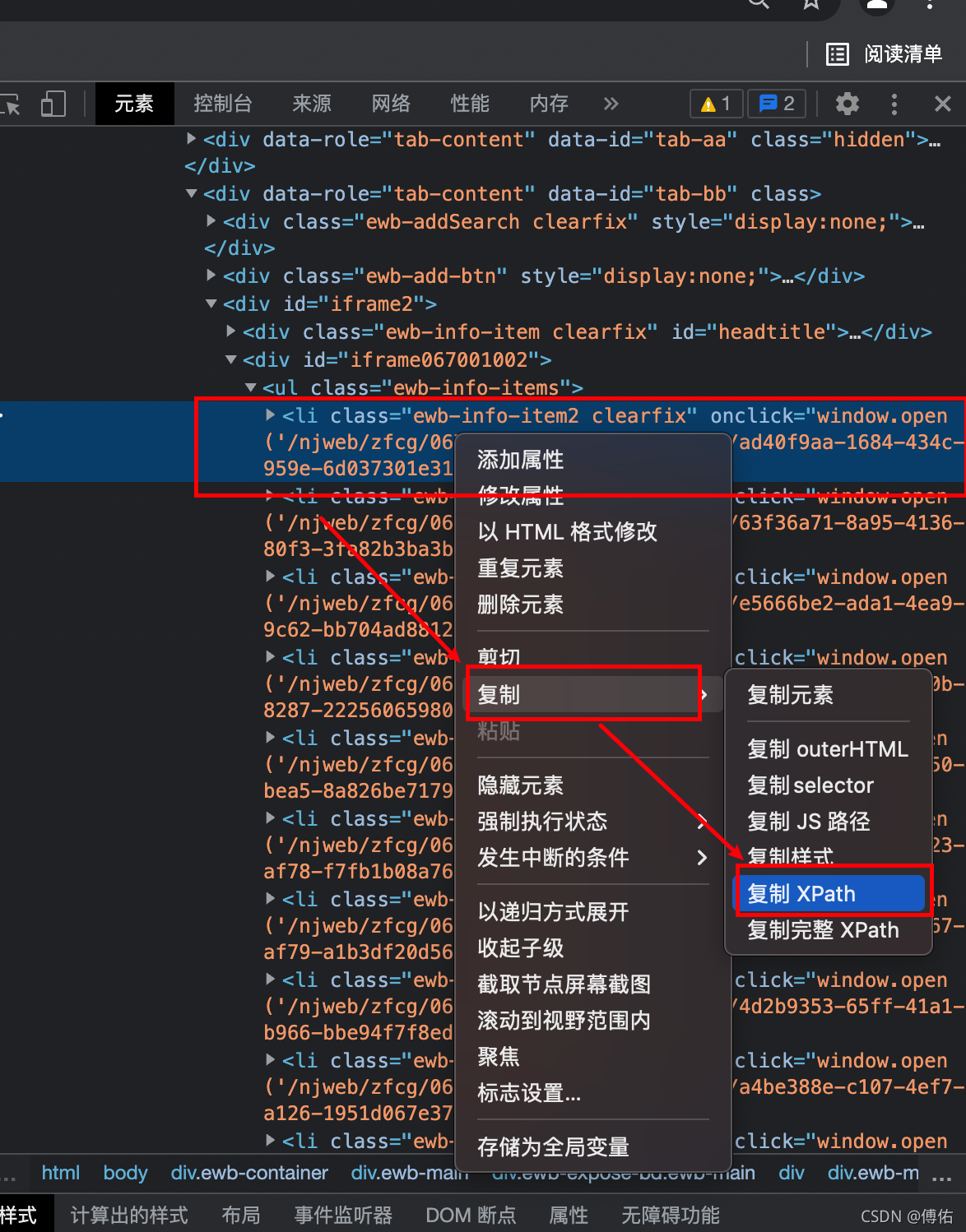
得到Xpath(但是不一定正确,要通过观察结构,本例是符合的:div/ul/li):
//*[@id="iframe067001001"]/ul/li[1]
于是可以通过该Xpath找到这行文字所在位置:
host = "http://njggzy.nanjing.gov.cn/njweb/zfcg/goverPurchase.html#"
rule_host1 = '//*[@id="iframe067001001"]/ul/li['+str(j)+']/@onclick' #
project_link1 = str(xml_aly(rule=rule_host1, url=u_host))
通过
(3)实现页面url跳转以及翻页;
1)实现页面url跳转:
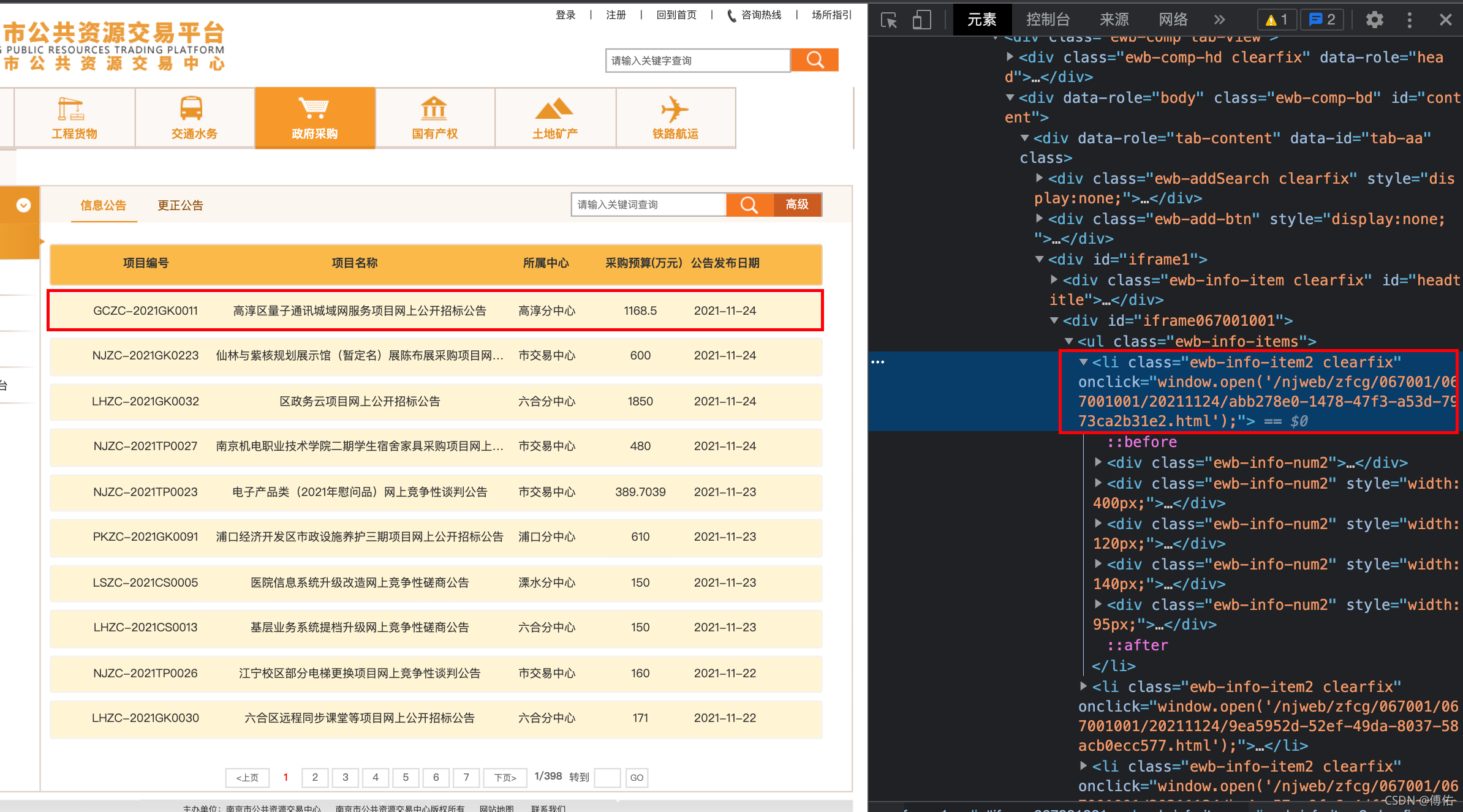
本例相对特殊,没有直接出现跳转页面的url,而是以“onclick="window.open('/njweb/zfcg/067001/067001001/20211124/abb278e0-1478-47f3-a53d-7973ca2b31e2.html');"”的形式。
所以我们想得到““οnclick="window.open(”后面部分。于是可以通过构造一下的方式:
k = k+1
host = "http://njggzy.nanjing.gov.cn/njweb/zfcg/goverPurchase.html#"
rule_host1 = '//*[@id="iframe067001001"]/ul/li['+str(j)+']/@onclick' #
project_link1 = str(xml_aly(rule=rule_host1, url=u_host))
url_head = "http://njggzy.nanjing.gov.cn"
url = url_head + str(project_link1)[15:-5]
print("第"+str(k)+"项,已经爬取目标网址:"+str(project_link[1])+str(url))
2)实现翻页:
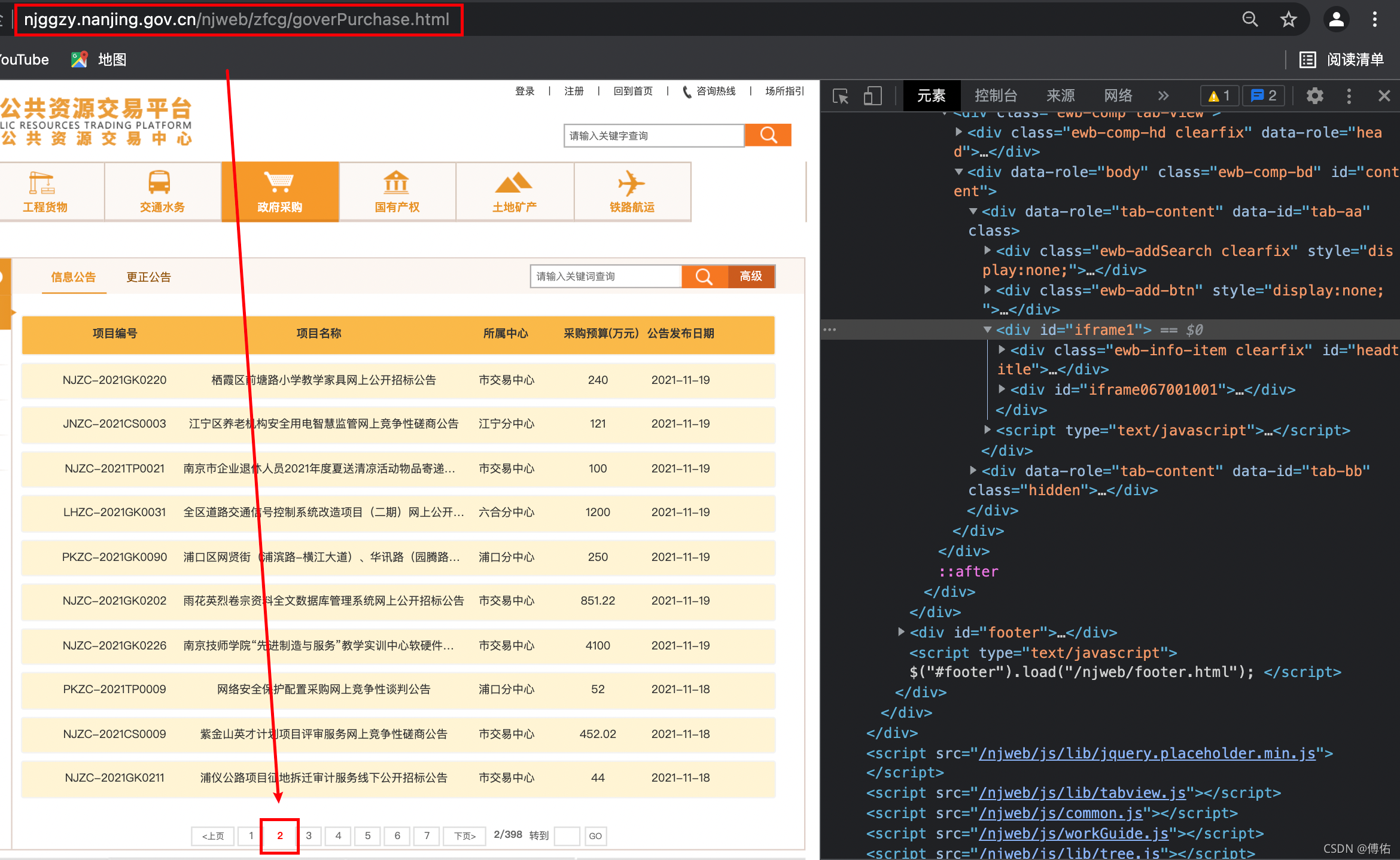



















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











