 Redis数据类型详解
Redis数据类型详解





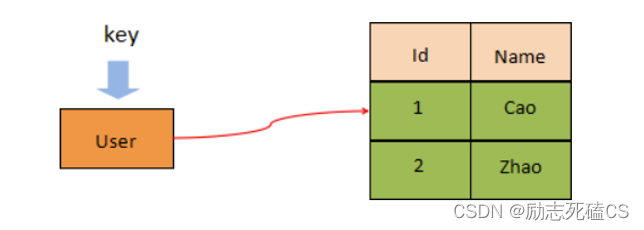
Redis数据类型
Redis 为了存储不同类型的数据,提供了五种常用数据类型
- string(字符串)
- hash(哈希散列)
- list(列表)
- set(集合)
- zset(sorted set:有序集合)
注意此处的数据类型指的是Value(值) 的数据类型,而非 key。
String类型
- 字符串是Redis里最基本的数据类型,Redis 使用标准 C 语言编写,在存储字符时,Redis 并未使用 C 语言的字符类型,而是自定义了一个属于特殊结构 SDS(Simple Dynamic String)即简单动态字符串)
- SDS是一个可以修改的内部结构,非常类似于 Java 的 ArrayList。
- SDS 的结构定义如下:

string 采用了预先分配冗余空间的方式来减少内存的频繁分配,如下图所示:
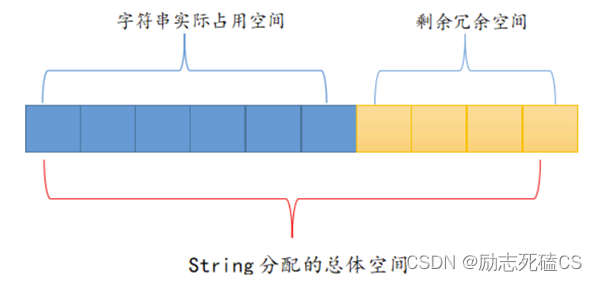
- Redis 每次给 string 分配的空间都要大于字符串实际占用的空间,这样就在一定程度上提升了 Redis string 存储的效率,比如当字符串长度变大时,无需再重新申请内存空间。
- 当字符串所占空间小于 1MB 时,Redis 对字符串存储空间的扩容是以成倍的方式增加的;而当所占空间超过 1MB 时,每次扩容只增加 1MB。Redis 字符串允许的最大值字节数是 512 MB。
- 字符串是Redis里最基本的数据类型。
- 可以使用set命令设置字符串类型数据,具体语法如下:
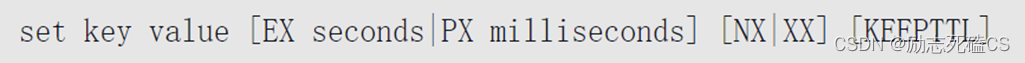
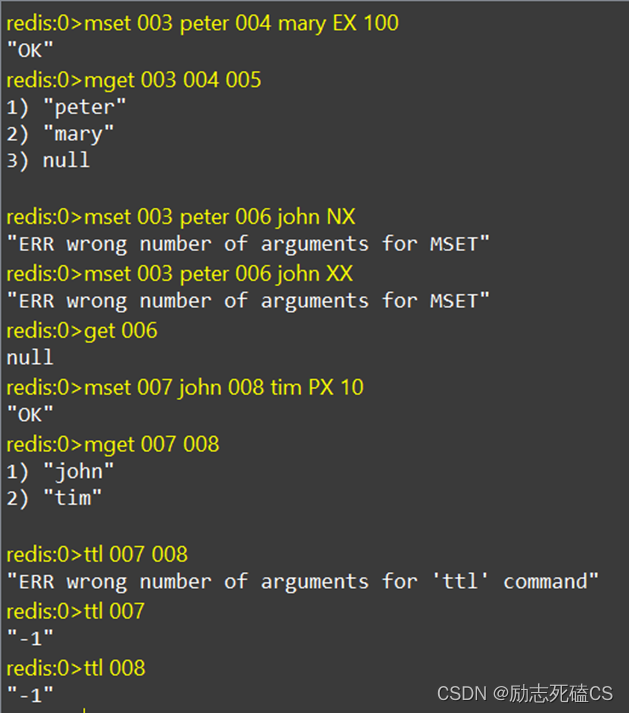
- key和value分别表示待设置字符串的键和值,如果对应的key里已经有值,那么再次执行set命令时会进行覆盖
- 通过EX和PX参数可以指定该变量的生存时间,在大多数场景里,应该合理设置对应的生存时间,否则可能会导致内存溢出的问题。
- NX参数表示当key不存在时才进行设置值的操作,如果key存在,那么该命令不执行;XX参数表示当key存在时才进行操作。
- KEEPTTL是Redis 6.0的新特性,是指“保留生存时间”,既重复set时,保留旧值的过期时间。
示例:

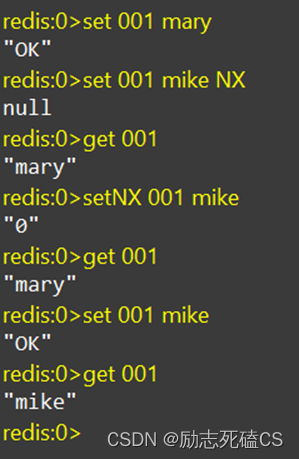
设置获取单个字符串
示例:

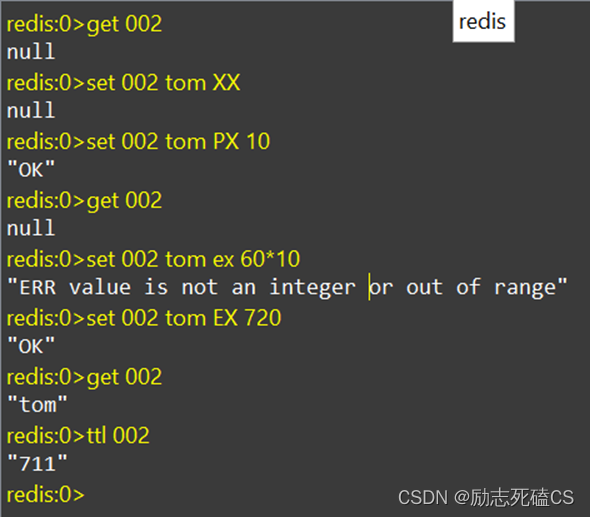
设置获取多个字符串
-
mset和mget命令分别能同时设置和获取多个字符串。其中,mset命令的语法如下:
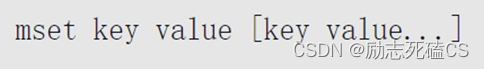
-
mget命令的语法如下:
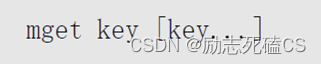
-
mset和mget命令不包含NX、XX、PX和EX等参数
示例:
对值进行增量和减量操作
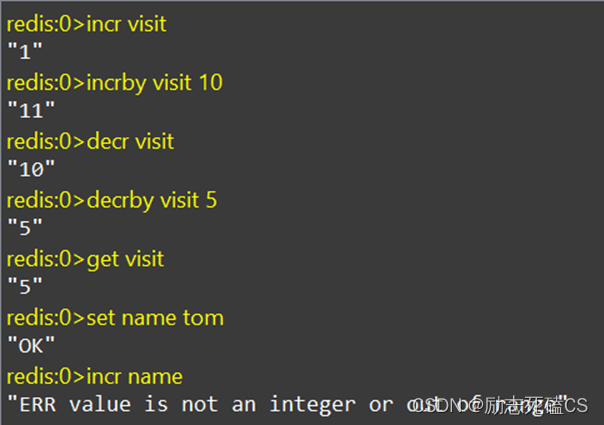
- 通过incr key命令能对key所对应的数字类型值进行加1操作,如果k不存在,默认在0的基础上+1
- 通过decr key命令能对key所对应的值进行减1操作,如果k不存在,默认在0的基础上-1
- 通过incrby key increment命令能对key对应的值进行加increment的操作
- 通过decrby by decrement命令能对key对应的值进行减decrement的操作。
- 运行上述命令时,需要确保key对应的值是数字类型,否则会报错。
- 在实际项目里,上述命令一般会用在统计流量和控制并发的场景中
示例:

Hash类型
- Redis hash(哈希散列)是由字符类型的 field(字段)和 value 组成的哈希映射表结构(也称散列表)
- hash 类型中,field 与 value 一一对应,且不允许重复。
- Redis hash 特别适合于存储对象。一个 filed/value 可以看做是表格中一条数据记录;而一个 key 可以对应多条数据。
- 当 hash 类型移除最后一个元素后,该存储结构就会被自动删除,其占用内存也会被系统回收
实现方式
Hash类型底层存储结构有两种实现方式
第一种,当存储的数据量较少的时,hash 采用 ziplist 作为底层存储结构,此时要求符合以下两个条件:
- 哈希对象保存的所有键值对(键和值)的字符串长度总和小于 64 个字节。
- 哈希对象保存的键值对数量要小于 512 个。
当无法满足上述条件时,hash 就会采用第二种方式来存储数据
- 也就是 **dict(字典结构)**该结构类似于 Java 的 HashMap,是一个无序的字典,并采用了数组和链表相结合的方式存储数据。
在 Redis 中,dict 是基于哈希表算法实现的,因此其查找性能非常高效,其时间复杂度为 O(1)。
哈希表
-
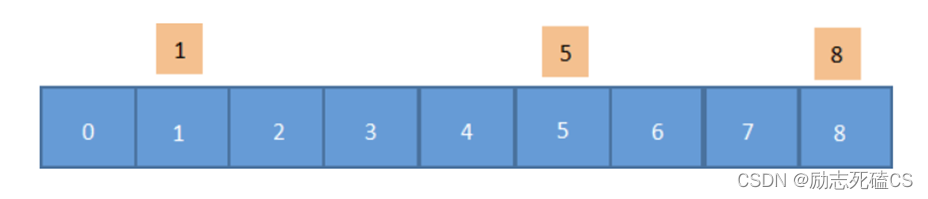
哈希表又称散列表,其初衷是将数据映射到数组中的某个位置上,这样就能够通过数组下标来访问该数据,从而提高数据的查找效率。
-
现在有 1/5/8/ 三个数字,你需要把这三个数字映射到数组中,由于哈希表规定必须使用下标来访问数据,因此你需要构建一个 0 到 8 的数组
-
我们把待查找的数字,在相应的下标数组上标记出来,它们之间一一对应。虽然这样做能实现元素的查找,但却很浪费存储空间,并且查找效率也不高。
-
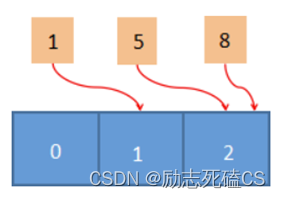
如果采用哈希表的话,我们只需要申请一个长度为 3 的数组(与待查找的元素个数相同),如下图所示:
-
将 1/5/8 分别对数组长度 3 做取模运算,然后把它们指向运算结果对应的数组槽位,这样就把一组离散的数据映射到了连续的空间中,从而在最大限度上提高了空间的利用率,并且也提高了元素的查找效率。
-
但可能会出现一个问题,数字 5、8 映射到同一个槽位上,这样就导致其中一个数字无法查找到。上述这种情况在实际中也会遇到,我们把它称为“哈希冲突”或者“哈希碰撞”。
-
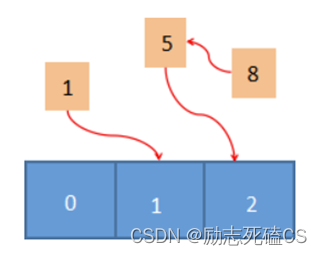
有许多方法可以解决“哈希冲突”,比如开放地址法、链表地址法,再次散列法等,而 Redis 采用是链表地址法。
-
将有冲突的数据使用链表把它们串联起来,这样即使发生了冲突,也可以将数据存储在一起,最后,通过遍历链表的方式就找到上述发生“冲突”的数据。如下所示:
-
如果值是字符串的话,就需要通过哈希函数将字符串转换成具体的数值,然后再对其进行映射。
设置与获取
示例:


hsetnx命令


针对key相关的操作
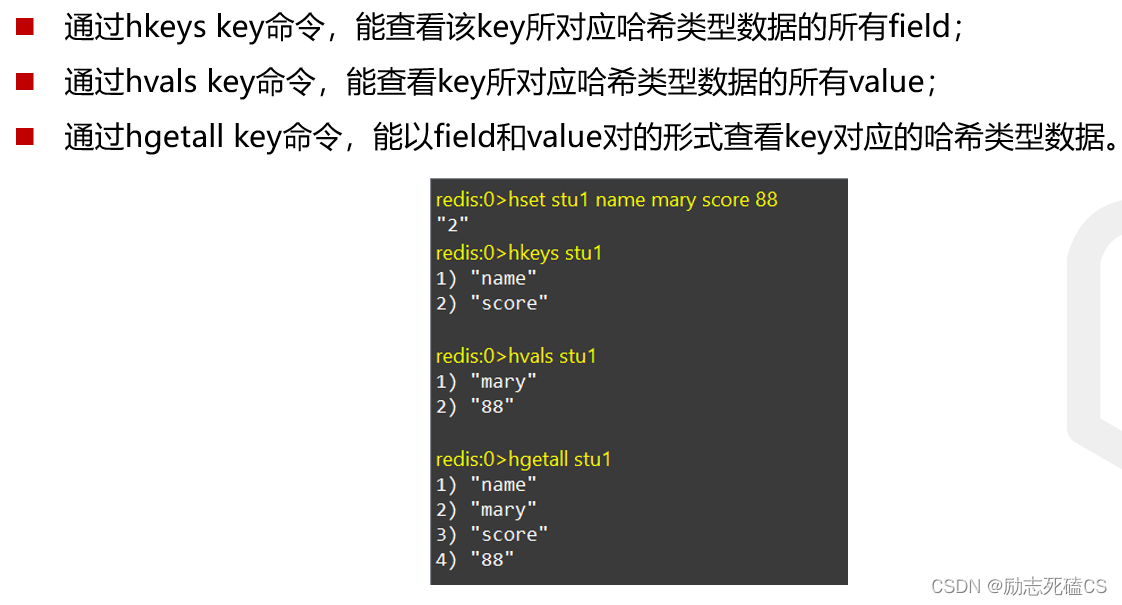
hexists命令

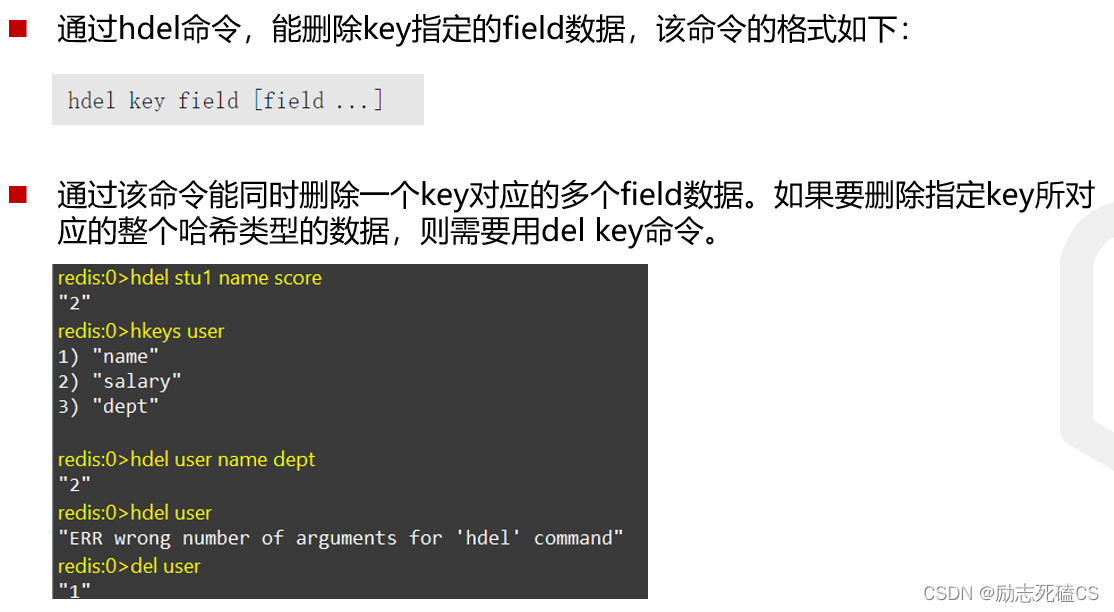
删除命令
List类型
- Redis list(列表)相当于 Java 语言中的 LinkedList 结构,是一个链表而非数组,其插入、删除元素的时间复杂度为 O(1),但是查询速度欠佳,时间复杂度为 O(n)。
- 当向列表中添加元素值时,首先需要给这个列表指定一个 key 键,然后使用相应的命令,从列表的左侧(头部)或者右侧(尾部)来添加元素,这些元素会以添加时的顺序排列。
- 当列表弹出最后一个元素时,该结构会被自动删除。
- Redis 列表的底层存储结构,其实是一个被称为快速链表(quicklist)的结构。
- 当列表中存储的元素较少时,Redis 会使用一块连续的内存来存储这些元素,这个连续的结构被称为 ziplist(压缩列表),它将所有的元素紧挨着一起存储。
- 当一个列表只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表的底层实现。
- 当一个哈希只包含少量键值对,比且每个键值对的键和值要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做哈希的底层实现。
- 压缩列表是Redis为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结枃。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值
- 而当数据量较大时,Redis 列表就会是用 quicklist(快速链表)存储元素。Redis 之所以采用两种方法相结合的方式来存储元素。
- 这是因为单独使用普通链表存储元素时,所需的空间较大,会造成存储空间的浪费。因此采用了链表和压缩列表相结合的方式,也就是 quicklist + ziplist,结构如下图:

- 将多个 ziplist 使用双向指针串联起来,这样既能满足快速插入、删除的特性,又节省了一部分存储空间。
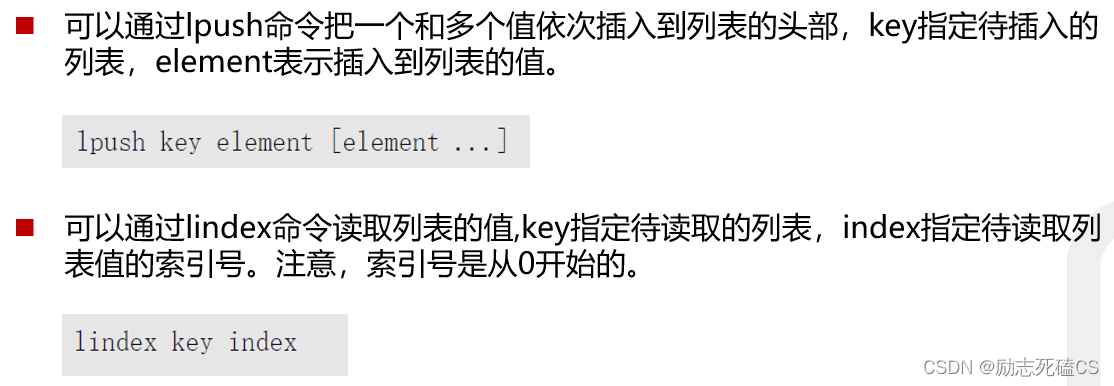
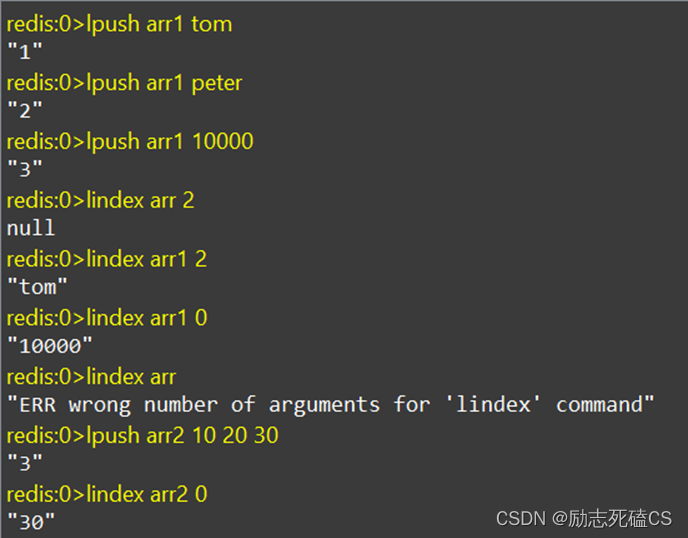
设置与获取
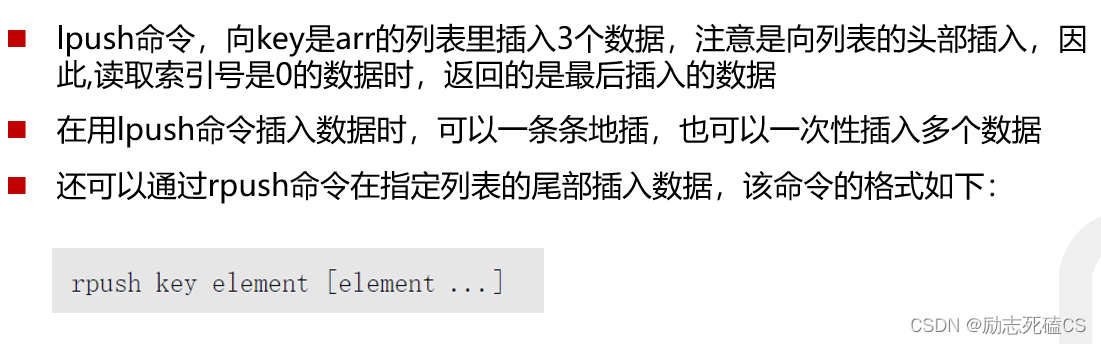
模拟堆栈和队列

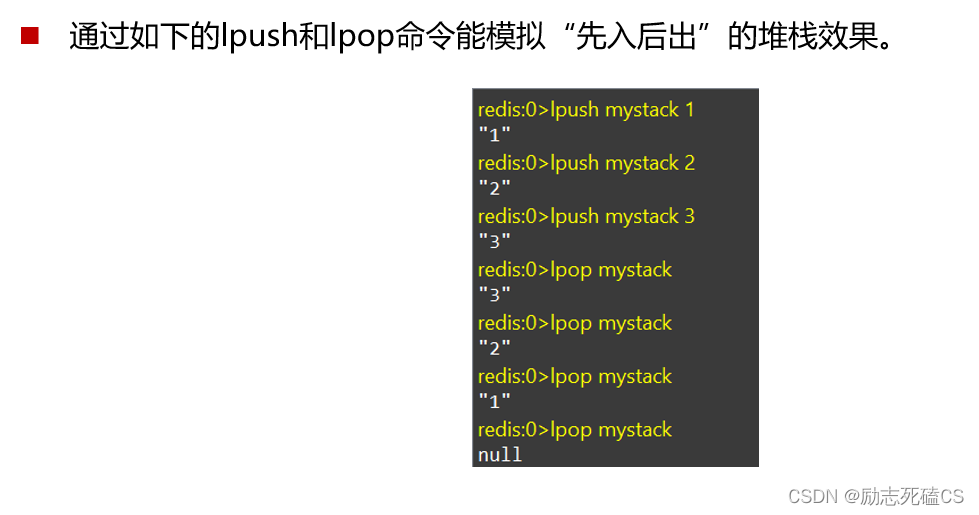
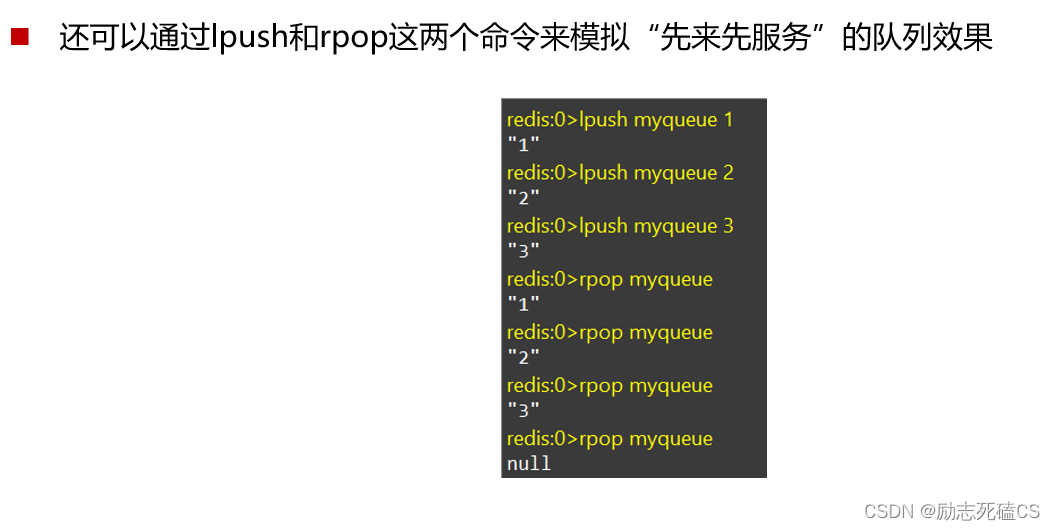
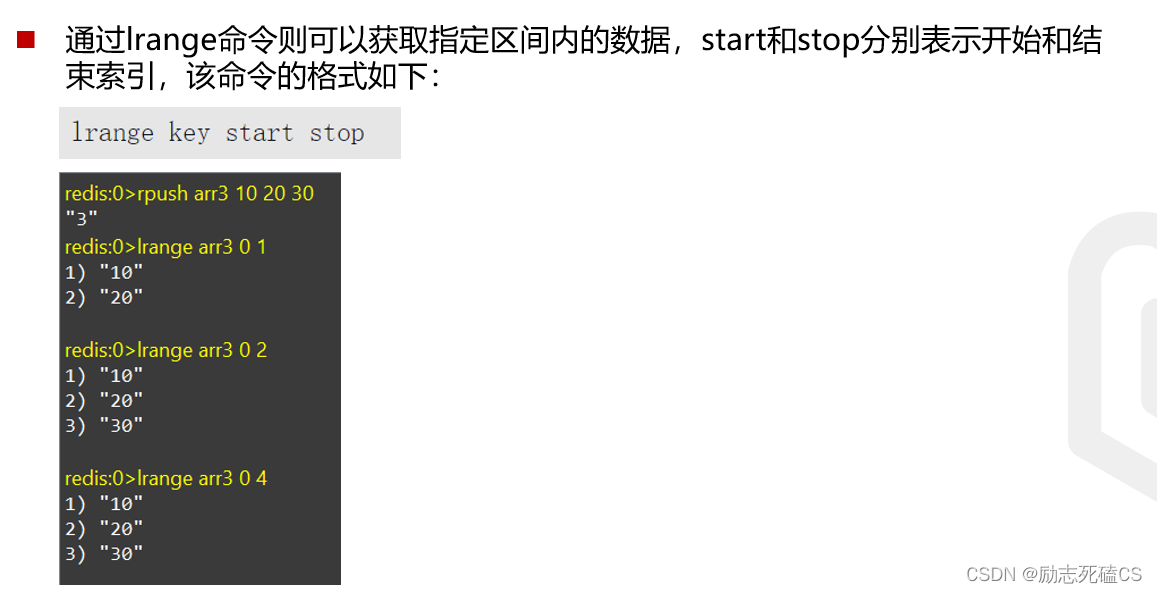
lrange命令
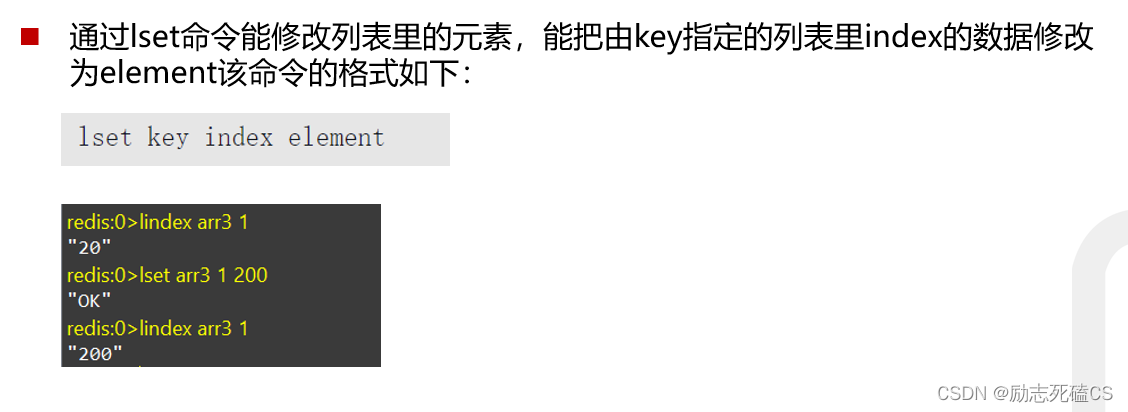
修改列表中的元素
将元素插入列表

获取列表长度

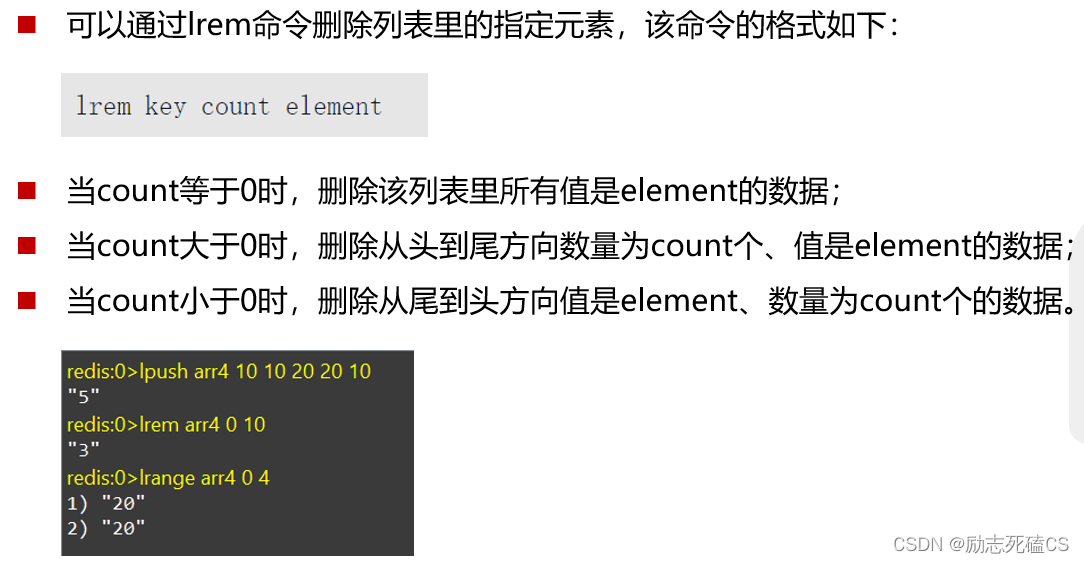
移除指定元素
修剪列表


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









